数据共享——悟道200G数据分享
-
openai的chatgpt现在已经非常火,虽然没有对中文开放,但是中文效果也很顶。据说用到了悟道数据集。 - 现在比较火的中文模型,比如
chatglm-6b模型,也用到悟道数据集。 - 最近也在训练大模型,也是缺质量好的,无监督数据。经过一番折腾,终于找到了。
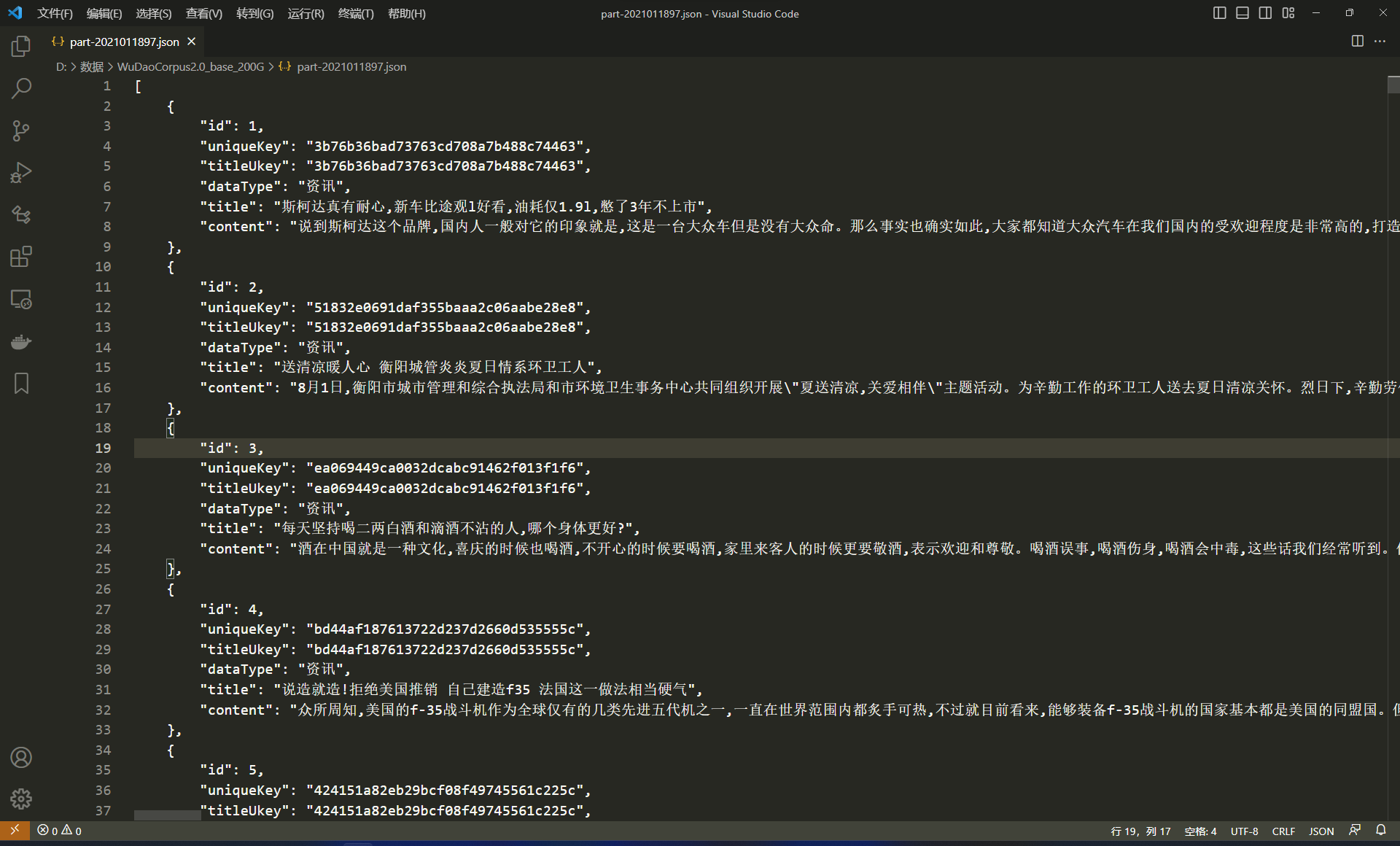
采用 20 多种规则从 100TB 原始网页数据中清洗得出最终数据集,注重隐私数据信息的去除,源头上避免 GPT-3 存在的隐私泄露风险;包含教育、科技等 50+个行业数据标签,可以支持多领域预训练模型的训练。
- 质量:在当前的开源的中文数据里面,质量算是比价好的了;
- 数量:解压前:
65GB,解压后:200GB; - 数据格式:
json - 数据字段
| 键 | 解释 |
|---|---|
| id | 数据在该 json 文件的 id |
| uniqueKey | 该条数据的唯一识别码 |
| titleUkey | 该标题的唯一识别码 |
| dataType | 数据类型 |
| title | 数据标题 |
| content | 正文 |

如果直接从官网下载的话,**下载速度比较慢,也不稳定。**后来我就把数据下载到本地,也把数据上传到百度云一份。
🚀关注公众号统计学人,回复悟道数据,即可获得。百度云下载基本上在10MB/S
1. 浏览器打开网站https://data.baai.ac.cn/data,找到WuDaoCorpora Text文本预训练数据集

如果你对自然语言处理、文本转向量、transformers、大模型、gpt等内容感兴趣欢迎关注我~