大模型的权重共享实现——transformers是如何实现大模型的embedding和lm_head权重绑定
- 前几天刘聪大哥在群里问了一个问题:“对于embedding和lm-head层权重共享的模型,仅训练这两层,是如何保证训落后权重是一样的。有代码吗,想了解了解”。
- 我记得之前在看流水线包pippy的时候,提出来,要注意那些模型权重有共享的网络。下面是注释
# from: https://github.com/pytorch/PiPPy/blob/f73076154ddffbb5476ca2ce6ae576c9efce6b13/pippy/LoadModule.py#L123
# Some weights like word_embeddings.weight and shared.weight will be used in
# different layers, but these layers may not in the index file, so we can only
# clone the shared weight to their corresponding layers.- 以前其实也没怎么研究过这个模型权重共享的代码,但又总感觉在哪里看到过,一直不太清楚。因此,这次打算把他搞懂。
-
- 到底哪些模型是权重共享的,怎么判断这个模型是不是权重共享。
-
- 搞懂transformers包在加载模型的时候,是如何如何将两个网络层绑定在一起的。
-
- 搞懂transformers包训练的时候,两个相同的网络层的权重是怎么参数更新的。
-
- 搞懂到底是使用pytorch的那一个属性来完成这些操作的。
-
- 在设计一个网络层的时候,工程上面,需要有哪些注意事项。
要先说明:权重共享和权重绑定都是一回事,只是说法不一样。就是在一个神经网络中,不同网络层共享同一个权重。
经过查找相关的资料,gpt2是权重共享的网络(他的embedding和lm_head层是共享一个权重的),具体可以参考这句话:
# from: https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/models/gpt2/modeling_gpt2.py#L953
@add_start_docstrings(
"""
The GPT2 Model transformer with a language modeling head on top (linear layer with weights tied to the input
embeddings).
""",
GPT2_START_DOCSTRING,
)把这句话,放在transformers包里面找一下,大概可以看出来,有几个模型确实是权重共享的,而且都是共享的lm_head和embedding层。
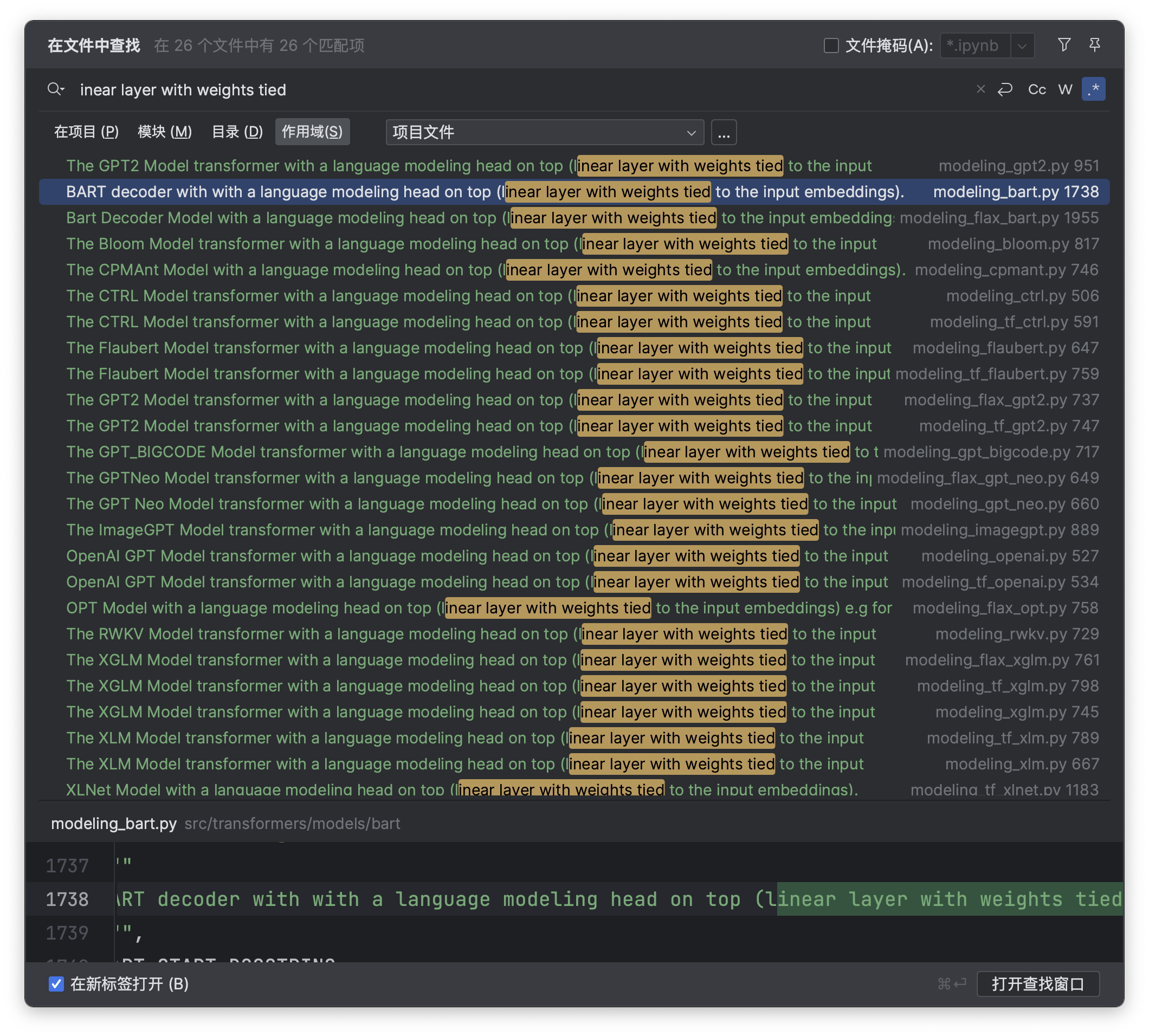
大部分nlp模型的权重共享,主要就是共享的是embedding和lm_head层的权重。我们来看看,transformers是如何实现的。
因为已经是看完了完整的代码,总结起来就是这样:
- 在模型初始化的时候,跳过对lm_head权重的加载.
- 将embedding的weight复制给lm_head的weight.
- 利用的就是pytorch的nn.Parameter对象的能力.
虽然道理简单,但是transformers的实现,就太复杂了。分析加载预训练模型的控制流程
- 使用
GPT2DoubleHeadsModel.from_pretrained,从预训练模型文件中,对model做初始化。
import torch
from transformers import AutoTokenizer, GPT2DoubleHeadsModel
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = GPT2DoubleHeadsModel.from_pretrained("gpt2")-
GPT2DoubleHeadsModel继承了GPT2PreTrainedModel,而GPT2PreTrainedModel是继承了PreTrainedModel。也就是说GPT2DoubleHeadsModel.from_pretrained是来源于PreTrainedModel.from_pretrained;
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/models/gpt2/modeling_gpt2.py
class GPT2PreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = GPT2Config
load_tf_weights = load_tf_weights_in_gpt2
class GPT2LMHeadModel(GPT2PreTrainedModel):
_tied_weights_keys = ["lm_head.weight"]
def __init__(self, config):
super().__init__(config)
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
- 接下来再在
PreTrainedModel.from_pretrained调用tie_weights方法,是的,就是tie_weights方法将embedding层和lm_head层绑定的。
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L2927
model.is_loaded_in_4bit = load_in_4bit
model.is_loaded_in_8bit = load_in_8bit
model.is_quantized = load_in_8bit or load_in_4bit
# make sure token embedding weights are still tied if needed
model.tie_weights()
# Set model in evaluation mode to deactivate DropOut modules by default
model.eval()-
tie_weights方法是如何将embedding层和lm_head层绑定的?接下来解读其代码。
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L1264
def tie_weights(self):
"""
Tie the weights between the input embeddings and the output embeddings.
If the `torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning the
weights instead.
"""
if getattr(self.config, "tie_word_embeddings", True):
output_embeddings = self.get_output_embeddings()
if output_embeddings is not None:
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
if getattr(self.config, "is_encoder_decoder", False) and getattr(self.config, "tie_encoder_decoder", False):
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
self._tie_encoder_decoder_weights(self.encoder, self.decoder, self.base_model_prefix)
for module in self.modules():
if hasattr(module, "_tie_weights"):
module._tie_weights()-
- 他会检查你模型的config里面有没有
tie_word_embeddings属性,只有在你明确表明tie_word_embeddings=False的时候,才不会进行权重绑定。
- 他会检查你模型的config里面有没有
-
- 取模型的
embedding层,然后调用_tie_or_clone_weights方法,将模型权重从embedding层复制给lm_head层。
- 取模型的
- 那
_tie_or_clone_weights方法到底是怎么复制的,下面是他的代码。
-
- 使用了nn.Parameter来做包裹,然后复制。
-
- 检测你是否用了偏置(bias),如果用到了,也要复制。
-
- 其实这里就是最核心的部分:虽然在我们眼里,在训练的过程中,是不同网络层进行梯度更新,实际上是网络层绑定的权重进行梯度更新
-
- 虽然权重从一个网络层复制给另外一个网络层,但是这个权重并不是重新在内存上复制一份,而只是把参数更新的权利给到另外一个网络。类似于python对象的浅拷贝:只是网络层A和网络层B都指向了权重,却不能独享和内存复制。
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L1360
def _tie_or_clone_weights(self, output_embeddings, input_embeddings):
"""Tie or clone module weights depending of whether we are using TorchScript or not"""
if self.config.torchscript:
output_embeddings.weight = nn.Parameter(input_embeddings.weight.clone())
else:
output_embeddings.weight = input_embeddings.weight
if getattr(output_embeddings, "bias", None) is not None:
output_embeddings.bias.data = nn.functional.pad(
output_embeddings.bias.data,
(
0,
output_embeddings.weight.shape[0] - output_embeddings.bias.shape[0],
),
"constant",
0,
)
if hasattr(output_embeddings, "out_features") and hasattr(input_embeddings, "num_embeddings"):
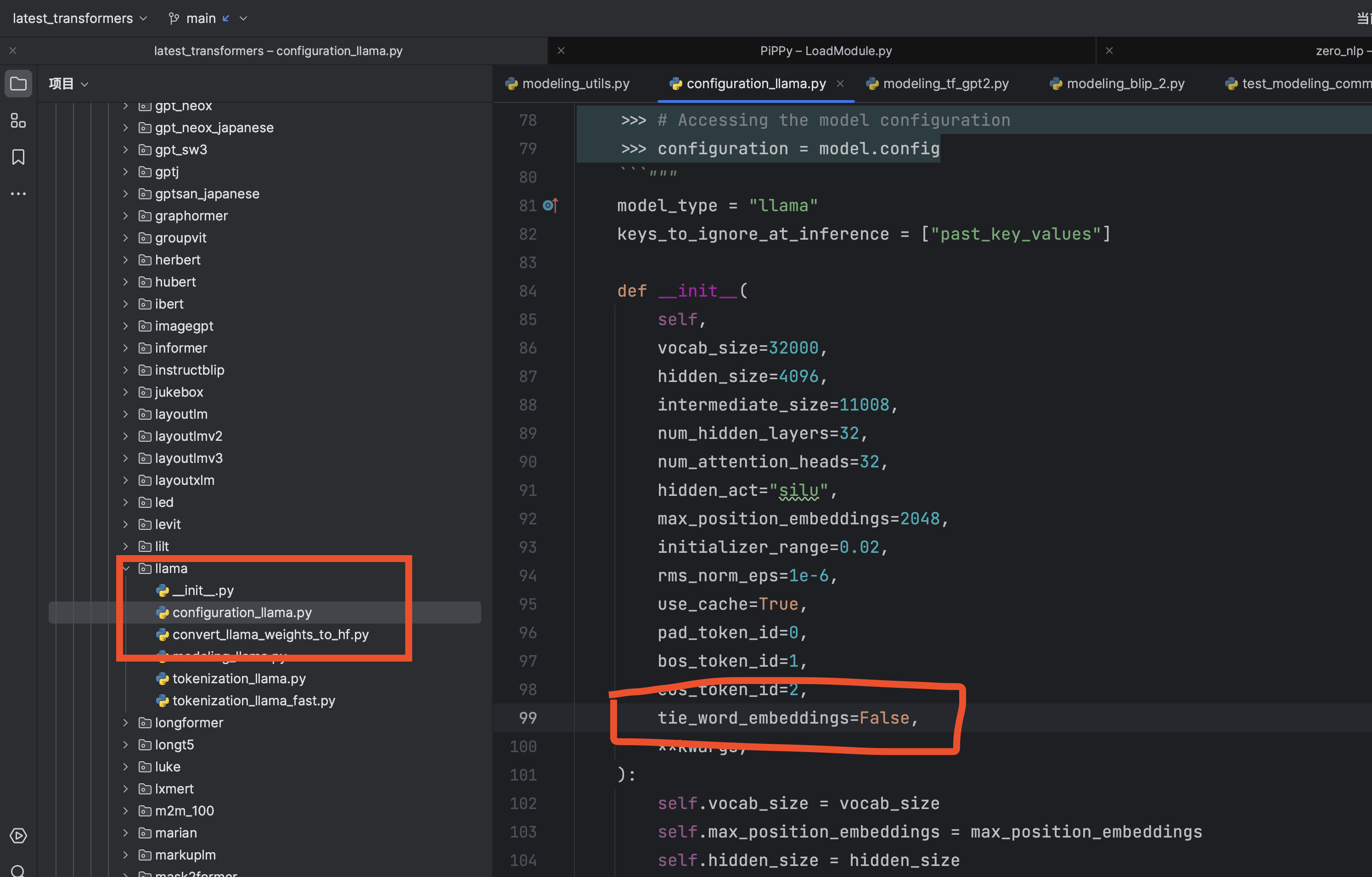
output_embeddings.out_features = input_embeddings.num_embeddings通过上面的源码阅读,你也就可以发现:如果不共享,只要在这个模型的config.py和config.json里面,明确的找到tie_word_embeddings=False
-
比如llama模型,就表示权重不共享(因为他明确的表示
tie_word_embeddings=False) -
chatglm-v1模型,权重是共享

- chatglm-v2模型,权重是不共享的(因为明确的表示
tie_word_embeddings=False)

- 网络层和权重的指向但不独享的关系,类似于python容器数据结构的浅拷贝;
- pytorch的
nn.Parameter; - 参数更新的时候,看似更新网络层,实际上是更新网络层对应的权重;
根据上面的源码,可以知道,如果想要实现embedding和lm_head权重绑定,你需要给模型添加get_output_embeddings、get_input_embeddings、set_input_embeddings三个方法。
喜欢阅读transformers源码,对nlp和transformers包感兴趣。如果你对自然语言处理、文本转向量、transformers、大模型、gpt等内容感兴趣欢迎关注我~