
![]()
![]()
![]()
![]()
![]()
![]()
Within this repository, a Music Recommender System using the K-Medoids clustering method is presented. The goal of this system is to provide the user with personalized suggestions, taking into account their preferences in terms of songs. The number of suggestions can be decided by the users (e.g., 5 suggestions). Spotify playlists are used to compute the clusters and provide song suggestions to the user. The user should provide a playlist with songs they like and may or may not provide a playlist from which suggestions should be made. To compute the best suggestions, a song is randomly picked from the user's preferences, and the Euclidean Distance measure is adopted to determine song recommendations, taking into account the songs' features.
The Spotipy library is used to extract both the songs and their features from the playlist or playlists provided by the user.
The Model and Data Cards are available here:
We selected Azure as cloud provider to deploy our services. We provide an overview of our services' architecture deployed on Azure.
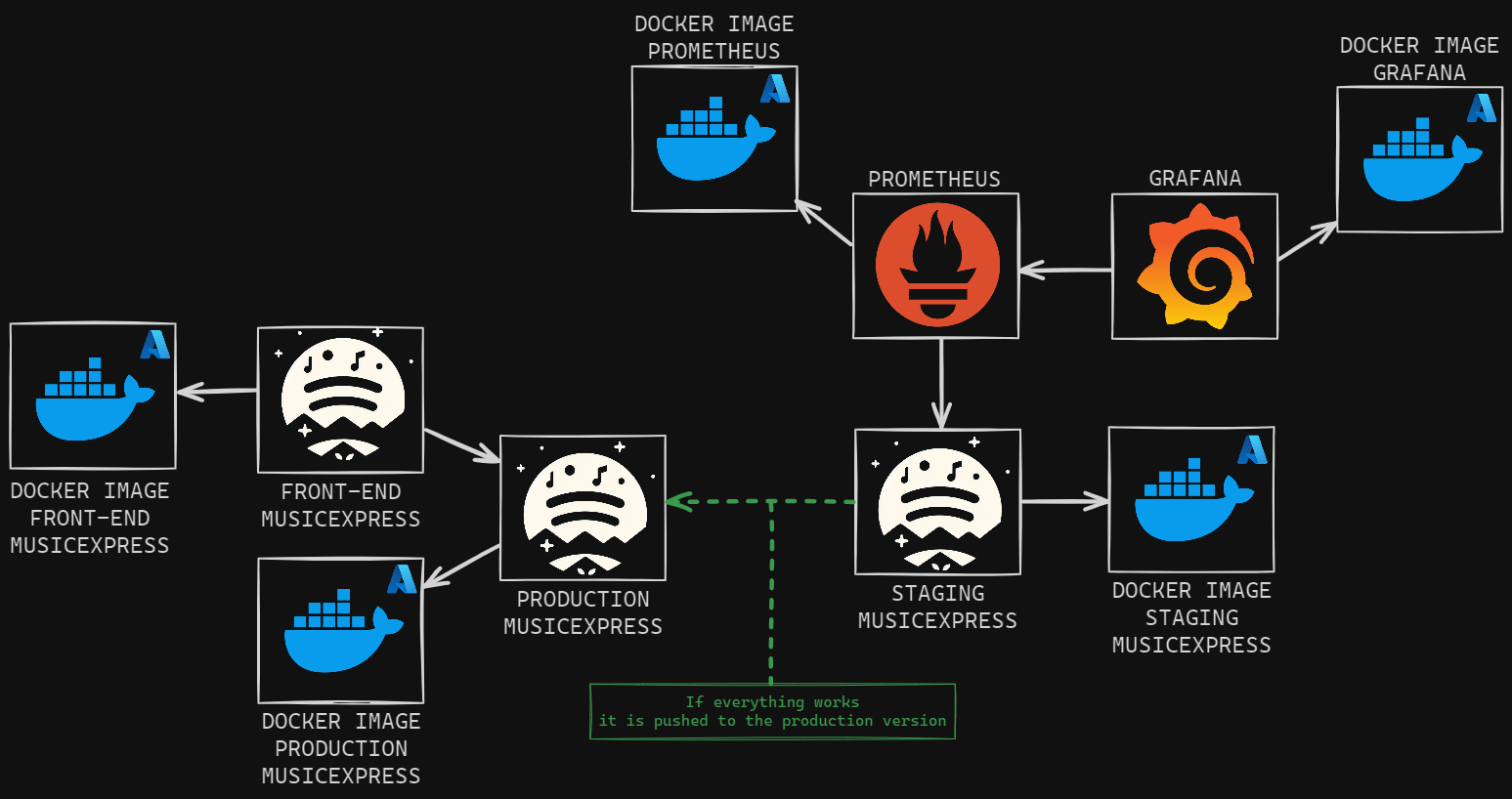
Here are the links for all our services:
We use Better Uptime to monitor the status of our website. Check the current status at our status page.
We made a new GitHub repository for our front-end code. You can find it here.
Note
We opted to maintain a separation between the back-end and front-end, aligning with industry standards in software development to ensure effective project manageability.
-
Python 3.11.5 (Download here) or even 3.11.6 (on VS Code select the correct Python Kernel) since there might be some problems with the scikit-learn-extra library when using Python 3.12.0
-
Pylance (if installed) may highlight libraries like mlflow and dagshub, indicating they cannot be resolved. However, this should not cause issues when running the code, provided all requirements are installed.
Tip
Considering the previous point, it is highly recommended to use a virtual environment for downloading the requirements. If you choose not to use it, you can skip the following section and proceed directly to the Installation of requirements part.
We report different ways to create a virtual environment so that if you have different versions of Python on your computer, you can easily create one without needing to look it up.
- Windows Distribution:
python -m venv your_venv_name- Linux Distribution:
python3 -m venv your_venv_namepath\to\the\python\version\exe\you\want\to\use -m venv your_venv_nameExample:
path\...\Python311\python.exe -m venv your_venv_name- Windows Distribution:
your_venv_name/Scripts/activate- Linux Distribution:
your_venv_name/bin/activateIt is recommended to update pip before installing requirements in the virtual environment to avoid potential installation issues. Copy and execute the following code to update pip:
python.exe -m pip install --upgrade pipOne pip is updated, proceed to install the requirements.txt to ensure the proper functioning of the model and visualization of results. You can easily install them with the following command:
pip install -r requirements.txtNote
The final step may require some time due to the installation of various libraries.
Given that the requirements have been installed, if you intend to utilize DVC for pipeline reproduction, download the data and execute the pipeline using the following commands:
# Retrieve data from remote storage
dvc pull -r myremote
# Run DVC Pipeline (only modified files are processed by default)
dvc repro
# Forcefully run the entire DVC Pipeline
dvc repro --forceFollowing the pipeline execution, the experiment is logged using Mlflow. All tracked files via DVC and the results of the experiment are showcased in our Dagshub Repository.
In this project, we've integrated a variety of tools, each designed for specific tasks. For detailed information about each tool, please refer to the following list:
- Testing: Great Expectations, Deepchecks and Pytest
- Quality Assessment (QA): Pylint, Pynblint and Flake8
- API: FastAPI
- Automated Workflows: Github Actions
- Containerization: Docker
- GreenAI: Code Carbon
- Performance & Load Testing: Locust
- Resource & Performance Monitoring: Prometheus and Grafana
- Data Drifts Monitoring: Deepchecks
@misc{MusicRecommendationUsingClusters,
author = {Rinaldi Ivan and, de Benedictis Salvatore and, Sibilla Antonio and, Laraspata Lucrezia},
title = {Music Recommendation using the K-Medoids Clustering Model},
month = {October},
year = {2023},
url = {https://github.com/se4ai2324-uniba/MusicExpress}
}├
├── .dvc <- DVC files
│
├── .github
│ │
│ └── workflows <- Github actions
│ │
│ ├── azure_deploy_main.yml <- Deployment on Azure of the Production release
│ ├── azure_deploy_staging.yml <- Deployment on Azure of the Staging release
│ ├── datadrift_scan.yml <- Data drift detection action
│ ├── Model_testing.yml <- Model testing (extract data, preprocess, and clustering) action
│ ├── test_scripts_api.yml <- Pytest scripts action
│ ├── QA.yml <- Quality Assessment action
│ └── README.md <- Github actions README
│
├── data <- Data folder
│ │
│ ├── interim <- Data before processing
│ ├── output <- Data after clustering and song recommendations
│ ├── processed <- Processed data, ready for clustering
│ ├── raw <- The original, immutable data dump
│ └── README.md <- Data Card
│
├── docker <- Docker files
│ │
│ ├── Dockerfile <- Docker image of our system (interact with API)
│ └── README.md <- Docker README
│
├── docs <- A default Sphinx project; see sphinx-doc.org for details
│
├── figures <- Images displayed in all the README(s) files
│
├── models <- Trained and serialized models, model predictions, or model summaries
│ │
│ ├── model.pkl <- Last trained model
│ └── README.md <- Model Card
│
├── notebooks <- Jupyter notebooks folder
│ │
│ └── MusicExpress <- Notebook providing an overview of the whole recommendation process
│
├── references <- Data dictionaries, manuals, and all other explanatory materials.
│
├── reports <- Generated analysis as HTML, PDF, LaTeX, etc
│ │
│ ├── codecarbon <- Codecarbon emission report
│ ├── deepchecks <- Deepchecks report for data integrity and data drift detection
│ ├── flake8 <- Flake8 report for quality assessment (QA)
│ ├── loucst <- Locust load testing reports
│ ├── pylint <- Pylint reports for quality assessment (QA)
│ ├── pynblint <- Pynblint reports for quality assessment (QA)
│ └── README.md <- Reporting tools README
│
├── src <- Project's source code
│ │
│ ├── api <- Scripts related to API
│ │ │
│ │ ├── main.py <- API endpoints
│ │ ├── monitoring.py <- Additional Prometheus metrics
│ │ ├── schemas.py <- API utilities
│ │ └── README.md <- API README
│ │
│ ├── data <- Scripts to download or extract data
│ │ │
│ │ └── extract_data.py <- Script to extract data from Spotify playlists
│ │
│ ├── features <- Scripts to process raw data
│ │ │
│ │ └── preprocessing.py <- Script to preprocess extracted data
│ │
│ ├── locust <- Scripts to run Locust performance and load tests
│ │ │
│ │ ├── locustfile.py <- Script to perform Locust load testing
│ │ └── README.md <- Locust README
│ │
│ ├── models <- Scripts to train the model, make suggestions, and compute metrics
│ │ │
│ │ ├── clustering.py <- Script to cluster data
│ │ ├── recommend.py <- Script to compute song recommendations
│ │ └── metrics.py <- Script to compute metrics
│ │
│ ├── tests <- Test scripts
│ │ │
│ │ ├── datadrift
│ │ │ │
│ │ │ ├── deepchecks_datadrift.ipynb <- Deepchecks data drift monitoring
│ │ │ └── README.md <- Data drift monitoring README
│ │ │
│ │ ├── pytest
│ │ │ │
│ │ │ ├── test_api.py <- Pytest API tests
│ │ │ ├── test_files_utilities.py <- Pytest files utilities methods tests
│ │ │ ├── test_preprocessing.py <- Pytest data preprocessing tests
│ │ │ ├── test_recommend.py <- Pytest recommendation methods tests
│ │ │ └── test_spotipy_utilities.py <- Pytest spotipy utilities methods tests
│ │ │
│ │ ├── test_deepchecks.ipynb <- Deepchecks data inspection tests
│ │ ├── test_extract_data.py <- GreatExpectations test on extract_data.py
│ │ ├── test_preprocessed_data.py <- GreatExpectations test on preprocessed_data.py
│ │ │
│ │ └── README.md <- Testing tools README
│ │
│ │── conf.py <- Variables used in all the other scripts
│ │── files_utilities.py <- Methods for file operations
│ │── great_expectations_utilities.py <- Methods for file operations
│ └── spotipy_utilities.py <- Methods that make use of Spotipy features
│
├── .dockerignore <- Docker-ignore file
├── .dvcignore <- DVC-ignore file
├── compose.yaml <- Docker-compose file
├── dvc.lock <- DVC record file
├── dvc.yaml <- DVC pipeline file
├── LICENSE <- MIT License
├── Makefile <- Makefile with commands like `make data` or `make train`
├── prometheus.yaml <- Prometheus config file
├── README.md <- The top-level README of the repository
├── requirements.txt <- The requirements file for reproducing the analysis environment
├── setup.py <- Makes project pip installable (pip install -e .) so src can be imported
├── test_environment.py <- Checks Python Version
└── tox.ini <- tox file with settings for running tox; see tox.readthedocs.io
Project based on the cookiecutter data science project template. #cookiecutterdatascience