Channel
经过解析和变换完成后的数据,就认为已经是处理好的,此时就会进入logkit的待发送队列,即我们的Channel部分。
数据收集工具,顾名思义,就是将数据收集起来,再发送到指定位置,而为了将性能最优化,我们必须把收集和发送解耦,中间提供一个缓冲带,而Channel就是负责这个数据暂存的地方。有了Channel,读取和发送就解耦了,可以利用多核优势,多线程发送数据,提高数据吞吐量。
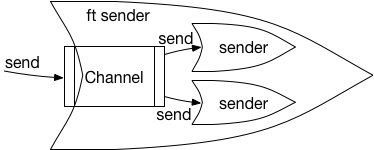
logkit的设计思路是把整个Channel,包括多线程发送做成一个框架,封装成了一个特殊的sender,我们称这个特殊的sender为"ft sender"。其架构如图1所示,ft sender与其他sender一样也提供了Send()方法,解析完毕后的数据调用Send方法实际上就是将数据传入到Channel中,然后再由ft sender处理多线程发送的逻辑,将从队列中取出的数据交由实际的sender多线程发送。
我们为用户提供了磁盘和内存两大队列方式选择。
- 如果追求最高的可靠性,那么就使用磁盘队列,数据会暂存到本地磁盘中,发送后自动删除,即使突然宕机也不怕丢失数据。若要开启该模式,在设置sender时增加如下配置即可:
"senders":[{
"fault_tolerant":"true", //开启容错(同时就代表开启了Channel)
"ft_save_log_path":"./ft_log", //指定Channel数据保存的位置(同时也包括格式错误的数据存放位置)
"ft_strategy":"always_save", //指定策略为永远保存
"ft_procs":"2" //开启并发发送的数量
}]
- 如果追求更高的性能,可以使用内存队列,其实现方式就是Go语言的Channel机制,稳定而简单,在关停过程中,也需要将Channel中的数据落地到磁盘,在随后重新启动时载入,正常使用过程中也没有数据丢失的风险。若要开启该模式,在设置sender时增加如下配置即可:
"senders":[{
"fault_tolerant":"true", //开启容错(同时就代表开启了Channel)
"ft_save_log_path":"./ft_log", //指定格式错误的数据存放的位置
"ft_strategy":"always_save", //指定策略为永远保存
"ft_memory_channel":"true", //指定使用内存队列
"ft_memory_channel_size":"100", //指定内存队列大小(批次数)
"ft_procs":"2" //开启并发发送的数量
}]
注意到,使用内存队列依旧要指定文件夹保存落地的数据,与磁盘队列的区别上只是增加了2个参数。
- 得益于Go语言的同步Channel机制,你甚至可以把内存队列的大小设置为0,以此实现多线程发送,这样使用内存队列即使宕机,也没有了数据丢失的风险。若要开启该模式,在设置sender时增加如下配置即可:
"senders":[{
"fault_tolerant":"true", //开启容错(同时就代表开启了Channel)
"ft_save_log_path":"./ft_log", //指定格式错误的数据存放的位置
"ft_strategy":"concurrent", //指定策略为并发发送
"ft_procs":"2" //开启并发发送的数量
}]
注意到,策略上变为 concurrent,同时也要指定错误数据的存放位置。
可以在Sender首页查看 https://github.com/qiniu/logkit/wiki/Senders
除了正常的作为待发送数据的等待队列以外,Channel如下一些非常有趣而实用的功能。
并不是所有解析完毕的数据发送到服务端就一定是正确的,有时服务端指定的数据格式和解析完毕的格式存在出入,或者数据中含有一些非法字符等情况,则数据不能发送成功,此时,如果一批数据中只有一条这样错误的数据,就很容易导致这一整批都失败。
错误数据筛选的作用就在于,把这一整批数据中对的数据筛选出来,留下错误的数据,将正确的发送出去。
做法很简单,当发送时遇到服务端返回存在格式错误的数据时,将这一批数据平均拆分为两批(二分),再放入队列,等待下次发送。再遇到错误时则再拆分,这样不断二分,直到一个批次中只有一条数据,且发送失败,那我们就找到了这个错误数据,可以选择丢弃或记录。
借助队列,我们很容易就能将错误数据筛选出来。
包拆分的由来是服务端不可能无限制开放每个批次数据传输的大小,出于服务器性能、传输性能等原因,总有会有一些限制。
当一个批次的数据过大时,就会导致传输失败。此时的做法与错误筛选的方法相似,只要将包二分即可,如果还是太大就再次二分,以此类推。
相信限速的功能最容易理解,数据统统经过Channel,那么只要限制这个Channel传输介质的速度即可。例如磁盘队列,只需要限制磁盘的IO读写速度;内存队列则限制队列大小以此达到限速的目的。
常见的流量控制的算法有漏桶算法(Leaky bucket)和令牌桶算法(Token bucket)两种,比较推荐采用令牌桶算法实现该功能,感兴趣的朋友可以阅读一下logkit 的 rateio 包。