{kind=link}
{kind=link}
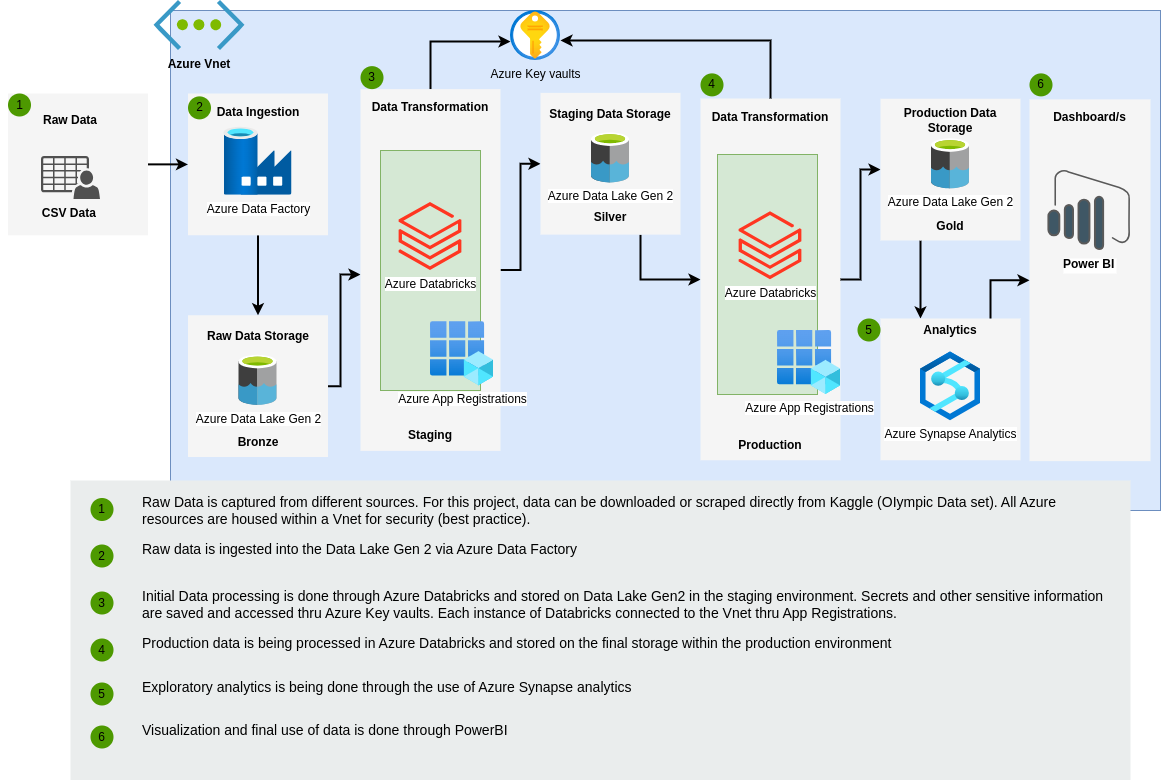
The basic architecture of the project is illustrated below:
Requirements:
- Azure account (preferably with Free credits to reduce costs)
- Basic knowledge of Python
- Introduction to Cloud Computing
- Introduction to Distributed Computing
- Introduction to Spark (and the Hadoop ecosystem)
- In most data projects, Raw data is captured from different sources. For this project we will be using a set data to be captured from an external source. The data can either be downloaded or scraped directly from Kaggle (Tokyo Olympic Data set).
- All provisioned services must be housed within an Azure VNet, for security purposes.
- Raw data is ingested via an HTTP pipeline within Azure Data Factory which is then stored into a Azure Data Lake Gen2.
- Create connectivity between Vnet and internal Azure Services via Azure App Registrations (Azure Entra).
- Most of the Data processing is done through Azure Databricks and stored on the Data Lake Gen2, in a Raw-Transformed-Prod style of layering.
- After production-level data processing is done, Exploratory Analysis is done through Azure Synapse Analytics.
- Visualization is then done through the use of PowerBI.