This project, created for the AI Alignment Course - AI Safety Fundamentals powered by BlueDot Impact, leverages a range of advanced resources to explore key concepts in mechanistic interpretability in transformers.
👇 To access more detailed information and comments on the analysis results, read the project's blog post 👇
I would like to express my gratitude to the AI Safety Fundamental team, the facilitators, and all participants in the cohorts that I had the opportunity to contribute to developing new ideas in our discussions. I am pleased to be a part of this team.
Mechanistic Interpretability in Action: Understanding Induction Heads and QK Circuits in Transformers
This repository contains two projects aimed at enhancing the mechanistic interpretability of transformer-based models, specifically focusing on GPT-2. The projects provide insights into two critical aspects of transformer behavior: Induction Head Detection and QK Circuit Analysis. By understanding these mechanisms, we aim to make transformer models more transparent, interpretable, and aligned with human values.
GPT-2, based on the Transformer architecture and developed by OPenAI, has been trained on a large dataset of internet text. It is an LLM developed to predict the next word in a sentence.
TransformerLens is designed to interpret and analyze the inner workings of Transformer-based models like GPT-2. It allows researchers to investigate specific layers, attention heads, and other internal components of the model to understand better how it processes information and makes decisions. It provides functionality to access and manipulate various aspects of the model, such as activation caches, query key (QK) circuits, and induction heads, but also makes it easier to visualize and interpret the model's behavior.
This project used these two tools together.
Induction heads are specialized attention heads within transformer models that help maintain and repeat sequences during in-context learning. This project focuses on identifying these heads and visualizing their behavior in repetitive sequences.
Here is the notebook!
- Dynamic Threshold Detection: A novel method to detect induction heads using dynamic thresholds based on attention score variance.
- Attention Heatmaps: Visualizations of attention patterns to highlight induction head activity in repetitive sequences.
- Evaluation Metrics: Precision, recall, and F1-score calculations to measure the effectiveness of the detection method.
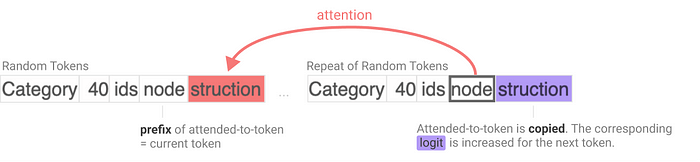
The way an induction head in transformer models pays attention to repeated patterns in a sequence is presented in the image. When a sequence of tokens is repeated, the induction head notices the repetition. Thus, it shifts its attention to the corresponding token in the previous sequence, and the probability of predicting the next token based on the previously attended pattern, i.e., logit, increases. This mechanism helps the model to remember and repeat sequences during in-context learning.
- Install Required Libraries:
pip install transformer-lens circuitsvis matplotlib seaborn-
Execute the Script: Run the
qk_circuit_analysis.pyscript to extract and visualize QK interactions for the provided sample sequences. -
Modify Input Sequences: Change the sequences variable in the script to analyze your own text sequences for QK circuit interactions.
The script generates attention heatmaps showing induction head activity for each sequence, providing a visual representation of how the model captures and retains context.
QK (Query-Key) circuits are fundamental to how transformers allocate attention among tokens in an input sequence. This project focuses on analyzing and visualizing QK interactions to understand how transformers prioritize information.
Here is the notebook!
- QK Pattern Extraction: Extracts Query and Key matrices from a specified layer of the transformer model.
- QK Interaction Heatmaps: Visualizations of the interaction between Query and Key matrices to showcase attention distribution.
- Causal Interventions: Analyzes the impact of QK circuits on model behavior through causal interventions like ablations.

It shows how QK (Query-Key) circuits in transformer models attend to different tokens according to their relevance. The attention pattern is visualized as moving information from the "key" token to the "query" token, affecting the model's prediction for the next token, the logit effect. This mechanism shows how attention is directed to specific words, thus affecting how the model processes and predicts the following tokens in a sequence.
- Install Required Libraries:
pip install transformer-lens circuitsvis matplotlib seaborn- Execute the Script: Run the
qk_circuit_analysis.pyscript to extract and visualize QK interactions for the provided sample sequences. - Modify Input Sequences: Change the sequences variable in the script to analyze your own text sequences for QK circuit interactions.
The script generates QK interaction heatmaps for each sequence, highlighting how attention is distributed among tokens based on the model's Query and Key matrices.
- Text Generation: Improve understanding of how models retain and repeat context over long sequences.
- Machine Translation: Analyze how models allocate attention to relevant parts of a sentence.
- Sentiment Analysis: Understand how specific tokens are prioritized based on context.
Clone the repository and install the necessary dependencies:
git clone <repository-link>
pip install -r requirements.txt- Choose a project directory (
induction_headsorqk_circuits). - Run the respective script for the project you are interested in:
induction_head_detection.pyfor Induction Heads.qk_circuit_analysis.pyfor QK Circuits.
- Modify the sequences variable in the script to use your own text sequences.
- Larger Transformer Models: Extend the analysis to larger models like GPT-3 or T5.
- Fine-Tuned Causal Interventions: Implement more precise causal interventions to isolate the effects of specific model components.
- Bias and Fairness Analysis: Explore the impact of induction heads and QK circuits on model bias and fairness.
- Cross-Modal Analysis: Apply these techniques to cross-modal transformers that handle both vision and language tasks.
📣 Exciting News! 💌 Don't miss a single update from me!🚀
🔔 Subscribe now to receive instant email alerts whenever I publish new content.
Join the community of learners and stay ahead together!📚
Contributions are welcome! Please open an issue or submit a pull request if you have suggestions or improvements.
For any questions or inquiries, please contact [[email protected]].
- Induction Heads - Illustrated by Callum McDougall
- Zoom-In: An Introduction to Circuits - OpenAI
- Intro to Mechanistic Interpretability: TransformerLens & induction circuits
- TransformerLens Library by Neel Nanda
- A Mathematical Framework for Transformer Circuits
- OpenAI's Research on Transformer Interpretability
- Anthropic's Research on Transformer Behaviors
- EleutherAI Research on Large Language Models
- QK Circuit Analysis for Attention Allocation in Transformers
- Attention Is All You Need (Vaswani et al., 2017)
- DeepMind's Research on Model Interpretability
- Distill Articles on Neural Network Interpretability