![]()

Makes visual reviews of web app releases easy.

squint compare https://prod.myapp.com https://beta.myapp.com uses Puppeteer to:
- automatically crawl all url paths from the beta version (see this issue)
- take screenshots of each page from prod and beta versions of the app
- output all diff images for pages that had visual differences
That's the main intended use case. The diffs will likely have false positives due to async loading, animations, and different data. That's ok, the main intention is not to be a full solution, but rather a light-weight alternative.
For most production setups, I'd recommend using Percy instead. That said, CLI flags have been designed customization in mind: you can for example run custom JS code before Puppeteer takes a screenshot.
Goodies:
-
Puppeteer under the hood
-
Smart defaults but highly configurable.
The goal is to provide most convenience flags via CLI, but allow flexible JS options for advanced tricks.
-
Supports connecting to your local Chrome, with its existing logins and sessions. No need to deal with cookies in code.
-
Tested on all platforms: macOS, Windows, and Linux
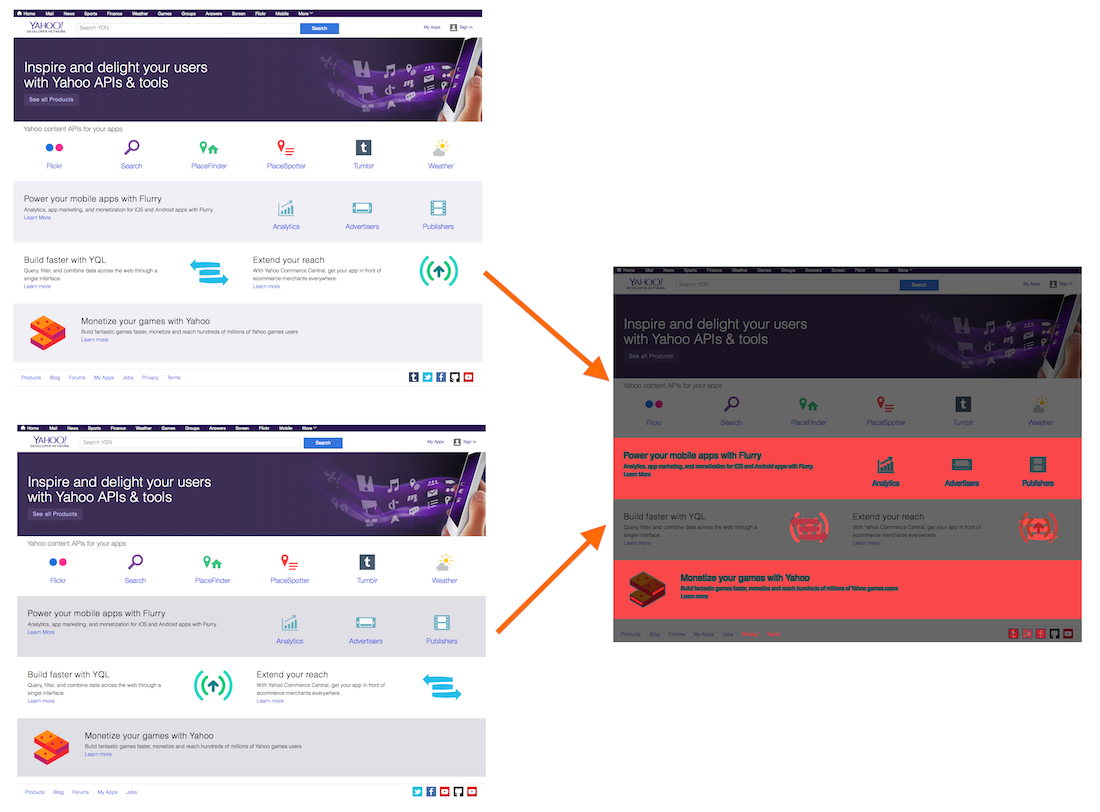
The path structure needs to be 1-to-1 match between the two sites. If you have preview builds for example under
https://prod.myapp.com/previews/123/..., this won't work automatically. The workaround is to use a proxy:
http-proxy -p 8080 https://prod.myapp.com/previews/123/ &
PID=$!
squint compare https://prod.myapp.com/ http://localhost:8080
kill $PIDnpm i -g squint-cli
Auto-generated
EXAMPLES
Compare current production to beta. The whole site is automatically crawled.
$ squint compare https://example.com https://beta.example.com
Crawl all paths from beta site and pipe output to a file. The crawler only follows site-internal links.
$ squint crawl https://beta.example.com > paths.txt
Get screenshot of a page.
$ squint screenshot https://beta.example.com
Get screenshot of a single element in a page.
$ squint screenshot --selector 'div' https://beta.example.com
Compare current production to beta, but use an existing file of paths.
$ squint compare --paths-file paths.txt https://example.com https://beta.example.com
Compare a single page.
$ squint compare --single-page https://example.com/about https://beta.example.com/about
Compare a single element with a selector.
$ squint compare --selector '#logo' https://example.com https://beta.example.com
Compare a single element, but use JS to dig an element from the page. (page: Puppeteer.Page) => HTMLElement
$ squint compare --selector-js '(page) => page.$("#logo")' https://example.com https://beta.example.com
COMMON OPTIONS
--help Shows this help message
--puppeteer-launch-mode Options: launch, connect. Default: launch
--puppeteer-launch-options Puppeteer .launch or .connect options in JS. Default: {"headless":true}
--puppeteer-page-pool-max Maximum pages to use at the same time with Puppeteer. Default: 10
--include-hash When enabled, URL hashes are not ignored when crawling. Default: false
--include-search-query When enabled, URL search queries are not ignored when crawling. Default: false
--should-visit Custom JS function that can limit which links the crawler follows.
This is an AND filter on top of all other filters.
(
urlToVisit: url.URL,
hrefDetails: { currentUrl: string, href: string },
visited: Set<string>,
config: Config
) => boolean
--trailing-slash-mode Options: preserve, remove, add. Default: preserve
COMPARE & SCREENSHOT
-w --width Viewport width for Puppeteer. Default: 1280
-h --height Viewport height for Puppeteer. Default: 800
--paths-file File of URL paths. One path per line.
--selector Takes screenshot from a single element. Selector for document.querySelector.
page.waitForSelector is called to ensure the element is visible.
--selector-js Takes screenshot from a single element. Selector as JS function that digs an element.
(page: Puppeteer.Page) => HTMLElement
--screenshot-options Puppeteer .screenshot options in JS. Overrides other options.
--after-goto Custom JS function that will be run after Puppeteer page.goto has been called.
(page: Puppeteer.Page) => Promise<void>
--after-page Custom JS function that will be run after Puppeteer page has been created.
(page: Puppeteer.Page) => Promise<void>
COMPARE
--out-dir Output directory for images. Default: .squint
--single-page Disable automatic crawling. Only take a screenshot from single page.
-o --out-file Relevant in only in single-page mode. Output file for the diff image.
--save-all Saves all diff image files, even if there are zero differences.
SCREENSHOT
-o --out-file Output file for the screenshot
CRAWL
--max-depth Maximum depth of links to follow. Default: Infinity
Got a trick? Submit a PR!
squint screenshot https://github.com/kimmobrunfeldt/squint --after-page "async (page) => page.setDefaultTimeout(60000)"You can also use page.setDefaultNavigationTimeout(60000) to only change navigation timeouts.
Click "I agree" button to hide ToS popup before taking a screenshot. Beware of character escaping, it's fragile.
squint screenshot https://google.com --puppeteer-launch-options '{ headless: false }' --after-goto 'async (page) => {
const [button] = await page.$x(`//button[contains(., "I agree")]`);
await button.click();
}'Take screenshot from the current viewport:
squint screenshot https://github.com/kimmobrunfeldt/squint --screenshot-options '{ fullPage: false }';DEBUG="puppeteer:* squint screenshot https://example.comWarning: It seems that Puppeteer element screenshot works differently when running with headless: false. Use with caution!
squint screenshot --puppeteer-launch-options '{ headless: false }' https://example.comThis way you can reuse existing sessions and logins. No need to do difficult setup with cookies.
-
Close your Chrome process (unless you already have remote debugging enabled).
-
Launch Chrome with a remote debugger enabled
In macOS:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222 -
squint screenshot --puppeteer-launch-mode connect --puppeteer-launch-options '{ browserURL: "http://localhost:9222" }' https://example.com
--should-visit can be useful if your page has a ton of blog posts:
squint crawl https://mysite.com --should-visit '(urlToVisit, hrefDetails, visited) => {
// Only visit 2 blog posts at max, assuming your site uses structure: /blog/posts/:id
const isBlogPost = (url) => url.includes("/blog/posts/");
if (!isBlogPost(urlToVisit.toString())) {
// Visit if something else than blog post
return true;
}
// If the visited list has 0 or 1 visits to a post,
// we should still visit one post.
return [...visited].filter(url => isBlogPost(url)).length <= 1;
}'urlToVisit is a WHATWG URL object.
The flag also works for compare command.
Start crawling from a nested path, and use --should-visit to limit crawling.
squint crawl https://github.com/kimmobrunfeldt/squint/ --should-visit '(urlToVisit) => {
const isTree = urlToVisit.pathname.startsWith("/kimmobrunfeldt/squint/tree/main");
const isBlob = urlToVisit.pathname.startsWith("/kimmobrunfeldt/squint/blob/main");
return isTree || isBlob;
}'You can use regular JS console.log for the incoming parameters, for example for --should-visit:
squint crawl https://myapp.com --should-visit '(...args) => console.log(...args) || true'squint screenshot --puppeteer-launch-options '{ headless: false }' https://example.comDEBUG_TESTS=true npm test
There's also DEBUG_PUPPETEER=true that launches Chrome with the UI visible. It seems that Puppeteer element screenshot works differently when running with headless: false. Use with caution!
Make sure the images are small because they are stored in git.
Run bash tools/populate-test-data.sh to re-generate PNG images for test cases.
These images are the baseline, and considered to be correct results.
bash release.sh