Releases: dmlc/gluon-cv
GluonCV 0.10.0 release
Highlights
GluonCV 0.10.0 release features a new Auto Module designed to bootstrap training tasks with less code and effort:
-
simpler and better custom dataset loading experience with pandas DataFrame visualization. Comparing with obsolete code based dataset composition, it allows you to load arbitrary datasets faster and more reliable.
-
one liner
fitfunction with configuration file support(yaml configuration file) -
built-in HPO support, for effortless tuning of hyper-parameters
gluoncv.auto
This release includes a new module called gluoncv.auto, with gluoncv.auto you can access many high-level APIs such as data, estimators and tasks.
gluoncv.auto.data
auto.data module is designed to load arbitrary web datasets you find on the internet, such as Kaggle competition datasets.
You may refer to this tutorial or check out the fully compatible d8 dataset for loading custom datasets.
Loading data:

The dataset has internal DataFrame storage for easier access and analysis

Visualization:

similar for object detection:

gluoncv.auto.estimators
In this release, we packed the following high-level estimators for training and predicting images for image classification and object detection.
- gluoncv.auto.estimators.ImageClassificationEstimator
- gluoncv.auto.estimators.SSDEstimator
- gluoncv.auto.estimators.CenterNetEstimator
- gluoncv.auto.estimators.FasterRCNNEstimator
- gluoncv.auto.estimators.YOLOv3Estimator
Highlighted usages
fitfunction:

predict,predict_proba(for image classification),predict_feature(for image classification)
![]()

saveandload.
You may visit the tutorial website for more detailed examples.
gluoncv.auto.tasks
In this release, the following auto tasks are supported and have been massively tested on many datasets to ensure HPO performance:
- gluoncv.auto.tasks.ImageClassification
- gluoncv.auto.tasks.ObjectDetection
Comparing with pure algorithm-based estimators, the auto tasks provide identical APIs and functionalities but allow you to fit with hyper-parameter optimization(HPO) with specified num_trials and time_limit. For object detection, it allows multiple algorithms(e.g., SSDEstimator and FasterRCNNEstimator) to be tuned as a categorical search space.
The tutorial is available here
Bug fixes and improvements
GluonCV 0.9.0 Release
Highlights
GluonCV v0.9.0 starts to support PyTorch!
PyTorch Support
We want to make our toolkit agnostic to deep learning frameworks so that it is available for everyone. From this release, we start to support PyTorch. All PyTorch code and models are under torch folder inside gluoncv, arranged in the same hierarchy as before: model, data, nn and utils. model folder contains our model zoo with model definitions, data folder contains dataset definition and dataloader, nn defines new operators and utils provide utility functions to help model training, evaluation and visualization.
To get started, you can find installation instructions, model zoo and tutorials on our website. In order to make our toolkit easier to use and customize, we provide model definitions separately for each method without extreme abstraction and modularization. In this manner, you can play with each model without jumping across multiple files, and you can modify individual model implementation without affecting other models. At the same time, we adopt yaml for easier configuration. We thrive to make our toolkit more user friendly for students and researchers.
Video Action Recognition PyTorch Model Zoo
We have 46 PyTorch models for video action recognition, with better I3D models, more recent TPN family, faster training (DDP support and multi-grid) and K700 pretrained weights. Finetuning and feature extraction can never be easier.
Details of our model zoo can be seen at here. In terms of models, we cover TSN, I3D, I3D_slow, R2+1D, Non-local, CSN, TSN and TPN. In terms of datasets, we cover Kinetics400, Kinetics700 and Something-something-v2. All of our models have similar or better performance compared to numbers reported in original paper.
We provide several tutorials to get you started, including how to make predictions using a pretrained model, how to extract video features from a pretrained model, how to finetune a model on your dataset, how to measure a model's flops/speed, and how to use our DDP framework.
Since video models are slow to train (due to slow IO and large model), we also support distributed dataparallel (DDP) training and multi-grid training. DDP can provide 2x speed up and multi-grid training can provide 3-4x speed up. Combining these two techniques can significantly shorten the training process. In addition, both techniques are provided as helper functions. You can easily add your model definitions to GluonCV (a single python file like this) and enjoy the speed brought by our framework. More details can be read in this tutorial.
Bug fixes and Improvements
- Refactored table in csv form. (#1465 )
- Added DeepLab ResNeSt200 pretrained weights (#1456 )
- StyleGAN training instructions (#1446 )
- More settings for Monodepth2 and bug fix (#1459 #1472 )
- Fix RCNN target generator (#1508)
- Revise DANet (#1507 )
- New docker image is added which is ready for GluonCV applications and developments(#1474)
Acknowledgement
Special thanks to @Arthurlxy @ECHO960 @zhreshold @yinweisu for their support in this release. Thanks to @coocoo90 for contributing the CSN and R2+1D models. And thanks to other contributors for the bug fixes and improvements.
GluonCV 0.8.0 Release
GluonCV 0.8.0 Release Note
Highlights
GluonCV v0.8.0 features the popular depth estimation model Monodepth2, semantic segmentation models (DANet and FastSCNN), StyleGAN, and multiple usability improvements.
Monodepth2 (thanks @KuangHaofei )
We provide GluonCV implementation of Monodepth2 and the results are fully reproducible. To try out on your own images, please see our demo tutorial. To train a Monodepth2 model on your own dataset, please see our dive deep tutorial.
Following table shows its performance on the KITTI dataset.
| Name | Modality | Resolution | Abs. Rel. Error | delta < 1.25 | Hashtag |
|---|---|---|---|---|---|
| monodepth2_resnet18_kitti_stereo_640x192 1 | Stereo | 640x192 | 0.114 | 0.856 | 92871317 |

More Semantic Segmentation Models (thanks @xdeng7 and @ytian8 )
We include two new semantic segmentation models in this release, one is DANet, the other is FastSCNN.
Following table shows their performance on the Cityscapes validation set.
| Model | Pre-Trained Dataset | Dataset | pixAcc | mIoU |
|---|---|---|---|---|
| danet_resnet50_citys | ImageNet | Cityscapes | 96.3 | 78.5 |
| danet_resnet101_citys | ImageNet | Cityscapes | 96.5 | 80.1 |
| fastscnn_citys | - | Cityscapes | 95.1 | 72.3 |
Our FastSCNN is an improved version from a recent paper using semi-supervised learning. To our best knowledge, 72.3 mIoU is the highest-scored implementation of FastSCNN and one of the best real-time semantic segmentation models.
StyleGAN (thanks @xdeng7 )

A GluonCV implementation of StyleGAN "A Style-Based Generator Architecture for Generative Adversarial Networks": https://github.com/dmlc/gluon-cv/tree/master/scripts/gan/stylegan
Bug fixes and Improvements
- We now officially deprecated python2 support, the minimum required python 3 version is 3.6. (#1399)
- Fixed Faster-RCNN training script (#1249)
- Allow SRGAN to be hybridized (#1281)
- Fix market1501 dataset (#1227)
- Added Visdrone dataset (#1267)
- Improved video action recognition task's
train.py(#1339) - Added jetson object detection tutorial (#1346)
- Improved guide for contributing new algorithms to GluonCV (#1354)
- Fixed amp parameter that required in class ForwardBackwardTask (#1404)
GluonCV 0.7.0 Release
Highlights
GluonCV 0.7 added our latest backbone network: ResNeSt, and the derived models for semantic segmentation and object detection. We achieve significant performance improvement on all three tasks.
Image Classification
GluonCV now provides the state-of-art image classification backbones that can be used by various downstream tasks. Our ResNeSt outperforms EfficientNet in accuracy-speed trade-off as shown in the following figures. You can now swap in our new ResNeSt in your research or product to get immediate performance improvement. Checkout the detail in our paper: ResNeSt: Split Attention Network
Here is a comparison between ResNeSt and EfficientNet. The average latency is computed using a single V100 on a p3dn.24xlarge machine with a batch size of 16.

| Model | input size | top-1 acc (%) | avg latency (ms) | |
|---|---|---|---|---|
| SENet_154 | 224x224 | 81.26 | 5.07 | previous |
| ResNeSt50 | 224x224 | 81.13 | 1.78 | v0.7 |
| ResNeSt101 | 256x256 | 82.83 | 3.43 | v0.7 |
| ResNeSt200 | 320x320 | 83.90 | 9.49 | v0.7 |
| ResNeSt269 | 416x416 | 84.54 | 19.50 | v0.7 |
Object Detection
We add two new ResNeSt based Faster R-CNN model. Noted that our model is trained using 2x learning rate schedule instead of the 1x schedule used in our paper. Our two new models are 2-4% higher on COCO mAP than our previous best model “faster_rcnn_fpn_resnet101_v1d_coco”. Notebly, our ResNeSt-50 based model has a 4.1% higher mAP than our previous ResNet-101 based model.
| Model | Backbone | mAP | |
|---|---|---|---|
| Faster R-CNN | ResNet-101 | 40.8 | previous |
| Faster R-CNN | ResNeSt-50 | 42.7 | v0.7 |
| Faster R-CNN | ResNeSt-101 | 44.9 | v0.7 |
Semantic Segmentation
We add ResNeSt-50 and ResNeSt-101 based DeepLabV3 for semantic segmentation task on ADE20K dataset. Our new models are 1-2.8% higher than our previous best. Similar to our detection result, ResNeSt-50 performs better than ResNet-101 based model. DeepLabV3 with ResNeSt-101 backbone achieves a new state-of-the-art of 46.9 mIoU on ADE20K validation set, which outperform previous best by more than 1%.
| Model | Backbone | pixel Accuracy | mIoU | |
|---|---|---|---|---|
| DeepLabV3 | ResNet-101 | 81.1 | 44.1 | previous |
| DeepLabV3 | ResNeSt-50 | 81.2 | 45.1 | v0.7 |
| DeepLabV3 | ResNeSt-101 | 82.1 | 46.9 | v0.7 |
Bug fixes and Improvements
- Instructions for achieving 25.7 min Mask R-CNN training.
- Fix R-CNNs export
GluonCV 0.6.0 Release
GluonCV 0.6.0 Release
Highlights
GluonCV v0.6.0 added more video classification models, added pose estimation models that are suitable for mobile inference, added quantized models for video classification and pose estimation, and we also included multiple usability and code improvements.
More video action recognition models
https://gluon-cv.mxnet.io/model_zoo/action_recognition.html
We now provide state-of-the-art video classification networks, such as I3D, I3D-Nonlocal and SlowFast. We have a complete model zoo over several widely adopted video datasets. We provide a general video dataloader (which can handle both frame format and raw video format). Users can do training, fine-tuning, prediction and feature extraction without writing complicate code. Just prepare a text file containing the video information is enough.
Below is the table of new models included in this release.
| Name | Pretrained | Segments | Clip Length | Top-1 | Hashtag |
|---|---|---|---|---|---|
| inceptionv1_kinetics400 | ImageNet | 7 | 1 | 69.1 | 6dcdafb1 |
| inceptionv3_kinetics400 | ImageNet | 7 | 1 | 72.5 | 8a4a6946 |
| resnet18_v1b_kinetics400 | ImageNet | 7 | 1 | 65.5 | 46d5a985 |
| resnet34_v1b_kinetics400 | ImageNet | 7 | 1 | 69.1 | 8a8d0d8d |
| resnet50_v1b_kinetics400 | ImageNet | 7 | 1 | 69.9 | cc757e5c |
| resnet101_v1b_kinetics400 | ImageNet | 7 | 1 | 71.3 | 5bb6098e |
| resnet152_v1b_kinetics400 | ImageNet | 7 | 1 | 71.5 | 9bc70c66 |
| i3d_inceptionv1_kinetics400 | ImageNet | 1 | 32 (64/2) | 71.8 | 81e0be10 |
| i3d_inceptionv3_kinetics400 | ImageNet | 1 | 32 (64/2) | 73.6 | f14f8a99 |
| i3d_resnet50_v1_kinetics400 | ImageNet | 1 | 32 (64/2) | 74.0 | 568a722e |
| i3d_resnet101_v1_kinetics400 | ImageNet | 1 | 32 (64/2) | 75.1 | 6b69f655 |
| i3d_nl5_resnet50_v1_kinetics400 | ImageNet | 1 | 32 (64/2) | 75.2 | 3c0e47ea |
| i3d_nl10_resnet50_v1_kinetics400 | ImageNet | 1 | 32 (64/2) | 75.3 | bfb58c41 |
| i3d_nl5_resnet101_v1_kinetics400 | ImageNet | 1 | 32 (64/2) | 76.0 | fbfc1d30 |
| i3d_nl10_resnet101_v1_kinetics400 | ImageNet | 1 | 32 (64/2) | 76.1 | 59186c31 |
| slowfast_4x16_resnet50_kinetics400 | ImageNet | 1 | 36 (64/1) | 75.3 | 9d650f51 |
| slowfast_8x8_resnet50_kinetics400 | ImageNet | 1 | 40 (64/1) | 76.6 | d6b25339 |
| slowfast_8x8_resnet101_kinetics400 | ImageNet | 1 | 40 (64/1) | 77.2 | fbde1a7c |
| resnet50_v1b_ucf101 | ImageNet | 3 | 1 | 83.7 | d728ecc7 |
| i3d_resnet50_v1_ucf101 | ImageNet | 1 | 32 (64/2) | 83.9 | 7afc7286 |
| i3d_resnet50_v1_ucf101 | Kinetics400 | 1 | 32 (64/2) | 95.4 | 760d0981 |
| resnet50_v1b_hmdb51 | ImageNet | 3 | 1 | 55.2 | 682591e2 |
| i3d_resnet50_v1_hmdb51 | ImageNet | 1 | 32 (64/2) | 48.5 | 0d0ad559 |
| i3d_resnet50_v1_hmdb51 | Kinetics400 | 1 | 32 (64/2) | 70.9 | 2ec6bf01 |
| resnet50_v1b_sthsthv2 | ImageNet | 8 | 1 | 35.5 | 80ee0c6b |
| i3d_resnet50_v1_sthsthv2 | ImageNet | 1 | 16 (32/2) | 50.6 | 01961e4c |
We include tutorials for how to fine-tune a pre-trained model on users' own dataset.
https://gluon-cv.mxnet.io/build/examples_action_recognition/finetune_custom.html
We include tutorials for introducing a new efficient video reader, Decord.
https://gluon-cv.mxnet.io/build/examples_action_recognition/decord_loader.html
We include tutorials for how to extract features from a pre-trained model.
https://gluon-cv.mxnet.io/build/examples_action_recognition/feat_custom.html
We include tutorials for how to make predictions from a pre-trained model.
https://gluon-cv.mxnet.io/build/examples_action_recognition/demo_custom.html
We include tutorials for how to perform distributed training on deep video models.
https://gluon-cv.mxnet.io/build/examples_distributed/distributed_slowfast.html
We include tutorials for how to prepare HMDB51 and Something-something-v2 dataset.
https://gluon-cv.mxnet.io/build/examples_datasets/hmdb51.html
https://gluon-cv.mxnet.io/build/examples_datasets/somethingsomethingv2.html
We will provide Kinetics600 and Kinetics700 pre-trained models in the next release, please stay tuned.
Mobile pose estimation models
https://gluon-cv.mxnet.io/model_zoo/pose.html#mobile-pose-models
| Model | OKS AP | OKS AP (with flip) | Hashtag |
|---|---|---|---|
| mobile_pose_resnet18_v1b | 66.2/89.2/74.3 | 67.9/90.3/75.7 | dd6644eb |
| mobile_pose_resnet50_v1b | 71.1/91.3/78.7 | 72.4/92.3/79.8 | ec8809df |
| mobile_pose_mobilenet1.0 | 64.1/88.1/71.2 | 65.7/89.2/73.4 | b399bac7 |
| mobile_pose_mobilenetv2_1.0 | 63.7/88.1/71.0 | 65.0/89.2/72.3 | 4acdc130 |
| mobile_pose_mobilenetv3_large | 63.7/88.9/70.8 | 64.5/89.0/72.0 | 1ca004dc |
| mobile_pose_mobilenetv3_small | 54.3/83.7/59.4 | 55.6/84.7/61.7 | b1b148a9 |
By replacing the backbone network, and use pixel shuffle layer instead of deconvolution, we can have models that are very fast. These models are suitable for edge device applications, tutorials on deployment will come soon.
More Int8 quantized models
https://gluon-cv.mxnet.io/build/examples_deployment/int8_inference.html
Below CPU performance is benchmarked on AWS EC2 C5.12xlarge instance with 24 physical cores.
Note that you will need nightly build of MXNet to properly use these new features.

| Model | Dataset | Batch Size | Speedup (INT8/FP32) | FP32 Accuracy | INT8 Accuracy |
|---|---|---|---|---|---|
| simple_pose_resnet18_v1b | COCO Keypoint | 128 | 2.55 | 66.3 | 65.9 |
| simple_pose_resnet50_v1b | COCO Keypoint | 128 | 3.50 | 71.0 | 70.6 |
| simple_pose_resnet50_v1d | COCO Keypoint | 128 | 5.89 | 71.6 | 71.4 |
| simple_pose_resnet101_v1b | COCO Keypoint | 128 | 4.07 | 72.4 | 72.2 |
| simple_pose_resnet101_v1d | COCO Keypoint | 128 | 5.97 | 73.0 | 72.7 |
| vgg16_ucf101 | UCF101 | 64 | 4.46 | 81.86 | 81.41 |
| inceptionv3_ucf101 | UCF101 | 64 | 5.16 | 86.92 | 86.55 |
| resnet18_v1b_kinetics400 | Kinetics400 | 64 | 5.24 | 63.29 | 63.14 |
| resnet50_v1b_kinetics400 | Kinetics400 | 64 | 6.78 | 68.08 | 68.15 |
| inceptionv3_kinetics400 | Kinetics400 | 64 | 5.29 | 67.93 | 67.92 |
For pose-estimation models, the accuracy metric is OKS AP w/o flip. Quantized 2D video action recognition models are calibrated with num-segments=3 (7 is for ResNet-based models).
Bug fixes and Improvements
- Performance of PSPNet using ResNet101 as backbone on Cityscapes (semantic segmentation) is improved from mIoU 77.1% to 79.9%, higher than the number reported in original paper.
- We will deprecate Python2 support in the next release.
GluonCV 0.5.0 Release
GluonCV 0.5.0 Release
Highlights
GluonCV v0.5.0 added Video Action Recognition models, added AlphaPose, added MobileNetV3, added VPLR semantic segmentation models for driving scenes, added more Int8 quantized models for deployment, and we also included multiple usability improvements.
New Models released in 0.5
| Model | Metric | 0.5 |
|---|---|---|
| vgg16_ucf101 | UCF101 Top-1 | 83.4 |
| inceptionv3_ucf101 | UCF101 Top-1 | 88.1 |
| inceptionv3_kinetics400 | Kinetics400 Top-1 | 72.5 |
| alpha_pose_resnet101_v1b_coco | OKS AP (with flip) | 76.7/92.6/82.9 |
| MobileNetV3_Large | ImageNet Top-1 | 75.32 |
| MobileNetV3_Small | ImageNet Top-1 | 67.72 |
| deeplab_v3b_plus_wideresnet_citys | Cityscapes mIoU | 83.5 |
New application: Video Action Recognition
https://gluon-cv.mxnet.io/model_zoo/action_recognition.html

Video Action Recognition in GluonCV is a complete application set, including model definition, training scripts, useful loss and metric functions. We also included some pre-trained models and usage tutorials.
| Model | Pre-Trained Dataset | Clip Length | Num of Segments | Metric | Dataset | Accuracy |
|---|---|---|---|---|---|---|
| vgg16_ucf101 | ImageNet | 1 | 1 | Top-1 | UCF101 | 81.5 |
| vgg16_ucf101 | ImageNet | 1 | 3 | Top-1 | UCF101 | 83.4 |
| inceptionv3_ucf101 | ImageNet | 1 | 1 | Top-1 | UCF101 | 85.6 |
| inceptionv3_ucf101 | ImageNet | 1 | 3 | Top-1 | UCF101 | 88.1 |
| inceptionv3_kinetics400 | ImageNet | 1 | 3 | Top-1 | Kinetics400 | 72.5 |
The tutorial for how to prepare UCF101 and Kinetics400 dataset: https://gluon-cv.mxnet.io/build/examples_datasets/ucf101.html and https://gluon-cv.mxnet.io/build/examples_datasets/kinetics400.html .
The demo for using the pre-trained model to predict human actions: https://gluon-cv.mxnet.io/build/examples_action_recognition/demo_ucf101.html.
The tutorial for how to train your own action recognition model: https://gluon-cv.mxnet.io/build/examples_action_recognition/dive_deep_ucf101.html.
More state-of-the-art models (I3D, SlowFast, etc.) are coming in the next release. Stay tuned.
New model: AlphaPose
https://gluon-cv.mxnet.io/model_zoo/pose.html#alphapose

| Model | Dataset | OKS AP | OKS AP (with flip) |
|---|---|---|---|
| alpha_pose_resnet101_v1b_coco | COCO Keypoint | 74.2/91.6/80.7 | 76.7/92.6/82.9 |
The demo for using the pre-trained AlphaPose model: https://gluon-cv.mxnet.io/build/examples_pose/demo_alpha_pose.html.
New model: MobileNetV3
https://gluon-cv.mxnet.io/model_zoo/classification.html#mobilenet
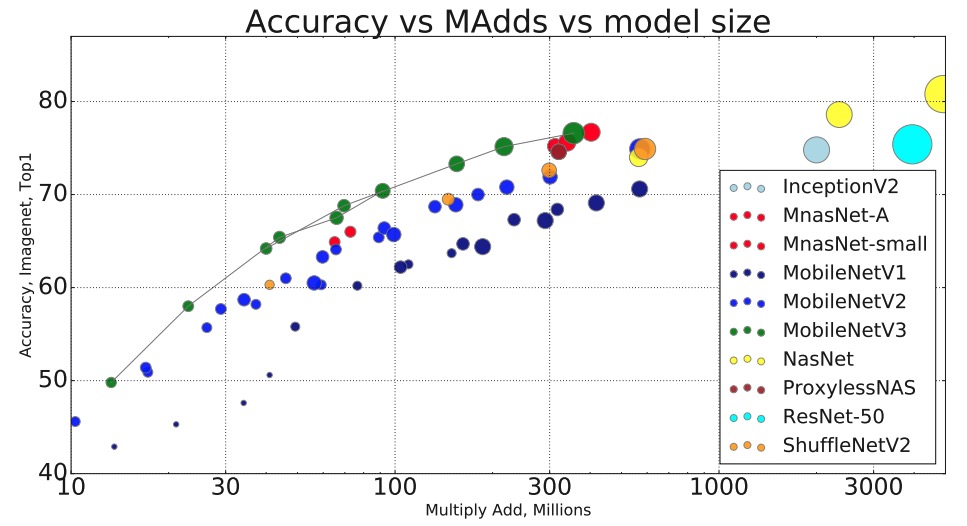
| Model | Dataset | Top-1 | Top-5 | Top-1 (original paper) |
|---|---|---|---|---|
| MobileNetV3_Large | ImageNet | 75.3 | 92.3 | 75.2 |
| MobileNetV3_Small | ImageNet | 67.7 | 87.5 | 67.4 |
New model: Semantic Segmentation VPLR
https://gluon-cv.mxnet.io/model_zoo/segmentation.html#cityscapes-dataset

| Model | Pre-Trained Dataset | Dataset | mIoU | iIoU |
|---|---|---|---|---|
| deeplab_v3b_plus_wideresnet_citys | ImageNet, Mapillary Vista | Cityscapes | 83.5 | 64.4 |
Improving Semantic Segmentation via Video Propagation and Label Relaxation ported in GluonCV. State-of-the-art method on several driving semantic segmentation benchmarks (Cityscapes, CamVid and KITTI), and generalizes well to other scenes.
New model: More Int8 quantized models
https://gluon-cv.mxnet.io/build/examples_deployment/int8_inference.html
Below CPU performance is benchmarked on AWS EC2 C5.12xlarge instance with 24 physical cores.
Note that you will need nightly build of MXNet to properly use these new features.

| Model | Dataset | Batch Size | C5.12xlarge FP32 | C5.12xlarge INT8 | Speedup | FP32 Acc | INT8 Acc |
|---|---|---|---|---|---|---|---|
| FCN_resnet101 | VOC | 1 | 5.46 | 26.33 | 4.82 | 97.97% | 98.00% |
| PSP_resnet101 | VOC | 1 | 3.96 | 10.63 | 2.68 | 98.46% | 98.45% |
| Deeplab_resnet101 | VOC | 1 | 4.17 | 13.35 | 3.20 | 98.36% | 98.34% |
| FCN_resnet101 | COCO | 1 | 5.19 | 26.22 | 5.05 | 91.28% | 90.96% |
| PSP_resnet101 | COCO | 1 | 3.94 | 10.60 | 2.69 | 91.82% | 91.88% |
| Deeplab_resnet101 | COCO | 1 | 4.15 | 13.56 | 3.27 | 91.86% | 91.98% |
For segmentation models, the accuracy metric is pixAcc. Usage of int8 quantized model is identical to standard GluonCV models, simple use suffix _int8.
Bug fixes and Improvements
- RCNN added automatic mix precision and horovod integration. Close to 4x improvements in training throughput on 8 V100 GPU.
- RCNN added multi-image per device support.
GluonCV toolkit v0.4.0
0.4.0 Release Note
Highlights
GluonCV v0.4 added Pose Estimation models, Int8 quantization for intel CPUs, added FPN Faster/Mask-RCNN, wide se/resnext models, and we also included multiple usability improvements.
We highly suggest to use GluonCV 0.4.0 with MXNet>=1.4.0 to avoid some dependency issues. For some specific tasks you may need MXNet nightly build. See https://gluon-cv.mxnet.io/index.html
New Models released in 0.4
| Model | Metric | 0.4 |
|---|---|---|
| simple_pose_resnet152_v1b | OKS AP* | 74.2 |
| simple_pose_resnet50_v1b | OKS AP* | 72.2 |
| ResNext50_32x4d | ImageNet Top-1 | 79.32 |
| ResNext101_64x4d | ImageNet Top-1 | 80.69 |
| SE_ResNext101_32x4d | ImageNet Top-1 | 79.95 |
| SE_ResNext101_64x4d | ImageNet Top-1 | 81.01 |
| yolo3_mobilenet1.0_coco | COCO mAP | 28.6 |
* Using Ground-Truth person detection results
Int8 Quantization with Intel Deep Learning boost
GluonCV is now integrated with Intel's vector neural network instruction(vnni) to accelerate model inference speed.
Note that you will need a capable Intel Skylake CPU to see proper speed up ratio.
| Model | Dataset | Batch Size | C5.18x FP32 | C5.18x INT8 | Speedup | FP32 Acc | INT8 Acc |
|---|---|---|---|---|---|---|---|
| resnet50_v1 | ImageNet | 128 | 122.02 | 276.72 | 2.27 | 77.21%/93.55% | 76.86%/93.46% |
| mobilenet1.0 | ImageNet | 128 | 375.33 | 1016.39 | 2.71 | 73.28%/91.22% | 72.85%/90.99% |
| ssd_300_vgg16_atrous_voc* | VOC | 224 | 21.55 | 31.47 | 1.46 | 77.4 | 77.46 |
| ssd_512_vgg16_atrous_voc* | VOC | 224 | 7.63 | 11.69 | 1.53 | 78.41 | 78.39 |
| ssd_512_resnet50_v1_voc* | VOC | 224 | 17.81 | 34.55 | 1.94 | 80.21 | 80.16 |
| ssd_512_mobilenet1.0_voc* | VOC | 224 | 31.13 | 48.72 | 1.57 | 75.42 | 75.04 |
*nms_thresh=0.45, nms_topk=200

Usage of int8 quantized model is identical to standard GluonCV models, simple use suffix _int8.
For example, use resnet50_v1_int8 as int8 quantized version of resnet50_v1.
Pruned ResNet
https://gluon-cv.mxnet.io/model_zoo/classification.html#pruned-resnet
Pruning channels of convolution layers is an very effective way to reduce model redundency which aims to speed up inference without sacrificing significant accuracy. GluonCV 0.4 has included several pruned resnets from original GluonCV SoTA ResNets for ImageNet.
| Model | Top-1 | Top-5 | Hashtag | Speedup (to original ResNet) |
|---|---|---|---|---|
| resnet18_v1b_0.89 | 67.2 | 87.45 | 54f7742b | 2x |
| resnet50_v1d_0.86 | 78.02 | 93.82 | a230c33f | 1.68x |
| resnet50_v1d_0.48 | 74.66 | 92.34 | 0d3e69bb | 3.3x |
| resnet50_v1d_0.37 | 70.71 | 89.74 | 9982ae49 | 5.01x |
| resnet50_v1d_0.11 | 63.22 | 84.79 | 6a25eece | 8.78x |
| resnet101_v1d_0.76 | 79.46 | 94.69 | a872796b | 1.8x |
| resnet101_v1d_0.73 | 78.89 | 94.48 | 712fccb1 | 2.02x |
Scripts for pruning resnets will be release in the future.
More GANs(thanks @husonchen)
SRGAN

A GluonCV SRGAN of "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network ": https://github.com/dmlc/gluon-cv/tree/master/scripts/gan/srgan
CycleGAN

Image-to-Image translation reproduced in GluonCV: https://github.com/dmlc/gluon-cv/tree/master/scripts/gan/cycle_gan
Residual Attention Network(thanks @PistonY)
GluonCV implementation of https://arxiv.org/abs/1704.06904

New application: Human Pose Estimation
https://gluon-cv.mxnet.io/model_zoo/pose.html

Human Pose Estimation in GluonCV is a complete application set, including model definition, training scripts, useful loss and metric functions. We also included some pre-trained models and usage tutorials.
| Model | OKS AP | OKS AP (with flip) |
|---|---|---|
| simple_pose_resnet18_v1b | 66.3/89.2/73.4 | 68.4/90.3/75.7 |
| simple_pose_resnet18_v1b | 52.8/83.6/57.9 | 54.5/84.8/60.3 |
| simple_pose_resnet50_v1b | 71.0/91.2/78.6 | 72.2/92.2/79.9 |
| simple_pose_resnet50_v1d | 71.6/91.3/78.7 | 73.3/92.4/80.8 |
| simple_pose_resnet101_v1b | 72.4/92.2/79.8 | 73.7/92.3/81.1 |
| simple_pose_resnet101_v1d | 73.0/92.2/80.8 | 74.2/92.4/82.0 |
| simple_pose_resnet152_v1b | 72.4/92.1/79.6 | 74.2/92.3/82.1 |
| simple_pose_resnet152_v1d | 73.4/92.3/80.7 | 74.6/93.4/82.1 |
| simple_pose_resnet152_v1d | 74.8/92.3/82.0 | 76.1/92.4/83.2 |
Feature Pyramid Network for Faster/Mask-RCNN
| Model | bbox/seg mAP | Caffe bbox/seg |
|---|---|---|
| faster_rcnn_fpn_resnet50_v1b_coco | 0.384/- | 0.379 |
| faster_rcnn_fpn_bn_resnet50_v1b_coco | 0.393/- | - |
| faster_rcnn_fpn_resnet101_v1d_coco | 0.412/- | 0.398/- |
| maskrcnn_fpn_resnet50_v1b_coco | 0.392/0.353 | 0.386/0.345 |
| maskrcnn_fpn_resnet101_v1d_coco | 0.423/0.377 | 0.409/0.364 |
Bug fixes and Improvements
- Now all resnet definitions in GluonCV support Synchronized BatchNorm
- Now pretrained object detection models support
reset_classfor reuse partial category knowledge so some task may not need to finetune models anymore: https://gluon-cv.mxnet.io/build/examples_detection/skip_fintune.html#sphx-glr-build-examples-detection-skip-fintune-py - Fix some dataloader issue(need mxnet >= 1.4.0)
- Fix some segmentation models that won't hybridize
- Fix some detection model random Nan problems (require mxnet latest nightly build, >= 20190315)
- Various other minor bug fixes
Gluon CV Toolkit 0.3.0
0.3 Release Note
Highlights
Added 5 new algorithms and updated 38 pre-trained models with improved accuracy
Compare 7 selected models
| Model | Metric | 0.2 | 0.3 | Reference |
|---|---|---|---|---|
| ResNet-50 | top-1 acc on ImageNet | 77.07% | 79.15% | 75.3% (Caffe impl) |
| ResNet-101 | top-1 acc on ImageNet | 78.81% | 80.51% | 76.4% (Caffe impl) |
| MobileNet 1.0 | top-1 acc on ImageNet | N/A | 73.28% | 70.9% (tensorflow impl) |
| Faster-RCNN | mAP on COCO | N/A | 40.1% | 39.6% (Detectron) |
| Yolo-v3 | mAP on COCO | N/A | 37.0% | 33.0% (paper) |
| DeepLab-v3 | mIoU on VOC | N/A | 86.7% | 85.7% (paper) |
| Mask-RCNN | mask AP on COCO | N/A | 33.1% | 32.8% (Detectron) |
Interactive visualizations for pre-trained models
For image classification:

and for object detection

Deploy without Python
All models are hybridiziable. They can be deployed without Python. See tutorials to deploy these models in C++.
New Models with Training Scripts
DenseNet, DarkNet, SqueezeNet for image classification
We now provide a broader range of model families that are good for out of box usage and various research purposes.
YoloV3 for object detection
Significantly more accurate than original paper. For example, we get 37.0% mAP on CoCo versus the original paper's 33.0%. The techniques we used will be included in a paper to be released later.
Mask-RCNN for instance segmentation
Accuracy now matches Caffe2 Detectron without FPN, e.g. 38.3% box AP and 33.1% mask AP on COCO with ResNet50.
FPN support will come in future versions.
DeepLabV3 for semantic segmentation.
Slightly more accurate than original paper. For example, we get 86.7% mIoU on voc versus the original paper's 85.7%.
WGAN
Reproduced WGAN with ResNet
Person Re-identification
Provide a baseline model which achieved 93.1 best rank1 score on Market1501 dataset.
Enhanced Models with Better Accuracy
Faster R-CNN
- Improved Pascal VOC model accuracy. mAP improves to 78.3% from previous version's 77.9%. VOC models with 80%+ mAP will be released with the tech paper.
- Added models trained on COCO dataset.
- Now Resnet50 model achieves 37.0 mAP, out-performs Caffe2 Detectron without FPN (36.5 mAP).
- Resnet101 model achieves 40.1 mAP, out-performs Caffe2 Detectron with FPN(39.8 mAP)
- FPN support will come in future versions.
ResNet, MobileNet, DarkNet, Inception for image classifcation
- Significantly improved accuracy for some models. For example, ResNet50_v1b gets 78.3% versus previous version's ResNet50_v1b's 77.07%.
- Added models trained with mixup and distillation. For example, ResNet50_v1d has 3 versions: ResNet50_v1d_distill (78.67%), ResNet50_v1d_mixup (79.16%), ResNet50_v1d_mixup_distill (79.29%).
Semantic Segmentation
- Synchronized Batch Normalization training.
- Added Cityscapes dataset and pretrained models.
- Added training details for reproducing state-of-the-art on Pascal VOC and Provided COCO pre-trained models for VOC.
Dependency
GluonCV 0.3.0 now depends on incubator-mxnet >= 1.3.0, please update mxnet according to installation guide to avoid compatibility issues.
Gluon CV Toolkit v0.2.0
Gluon CV Toolkit v0.2 Release Notes
Note: This release rely on some features of mxnet 1.3.0. You can early access these features by installing nightly build of mxnet.
You can update mxnet with pip:
pip install mxnet --upgrade --pre
# or
pip install mxnet-cu90 --upgrade --preNew Features in 0.2
Image Classification
Highlight: Much more accurate pre-trained ResNet models on ImageNet classification
These high accuracy models are updated to Gluon Model Zoo.
- ResNet50 v1b achieves over 77% accuracy, ResNet101 v1b at 78.8%, and ResNet152 v1b over 79%.
- Training with large batchsize, with float16 data type
- Speeding up training with ImageRecordIter interface
- ResNeXt for ImageNet and CIFAR10 classification
- SE-ResNet(v1b) for ImageNet
Object Detection
Highlight: Faster-RCNN model with training/testing scripts
-
Faster-RCNN
- RPN (region proposal network)
- Region Proposal
- ROI Align operator
-
Train SSD on COCO dataset
Semantic Segmentation
Highlight: PSPNet for Semantic Segmentation
- PSPNet
- ResNetV1b for ImageNet classification and Semantic Segmentation
- Network
dilationis an option
- Network
Datasets
Added the following datasets and usage tutorials
- MS COCO
- ADE20k
New Pre-trained Models in GluonCV
- cifar_resnext29_16x64d
- resnet{18|34|50|101}_v1b
- ssd_512_mobilenet1.0_voc
- faster_rcnn_resnet50_v2a_voc
- ssd_300_vgg16_atrous_coco
- ssd_512_vgg16_atrous_coco
- ssd_512_resnet50_v1_coco
- psp_resnet50_ade
Breaking changes
- Rename
DilatedResnetV0toResNetV1b
Gluon CV Toolkit v0.1
Gluon CV Toolkit v0.1 Release Notes
GluonCV provides implementations of state-of-the-art (SOTA) deep learning algorithms in computer vision. It is designed for helping engineers, researchers, and students to quickly prototype products, validate new ideas, and learning computer vision.
Table of Contents
- New Features
-
Tutorials
- Image Classification (CIFAR + ImageNet demo + divedeep)
- Object Detection (SSD demo + train + divedeep)
- Semantic Segmentation (FCN demo + train)
-
Model Zoo
- ResNet on ImageNet and CIFAR-10
- SSD on VOC
- FCN on VOC
- Dilated ResNet
-
Training Scripts
- Image Classification:
Train ResNet on ImageNet and CIFAR-10, including Mix-Up training - Object Detection:
Train SSD on PASCAL VOC - Semantic Segmentation
Train FCN on PASCAL VOC
- Image Classification:
-
Util functions
- Image Visualization:
- plot_image
- get_color_pallete for segmentation
- Bounding Box Visualization
- plot_bbox
- Training Helpers
- PolyLRScheduler
- Image Visualization:
-