![]()
"We find ourselves living in a society which is rich with data and the opportunities that comes with this. Yet, when disconnected, this data is limited in its usefulness. ... Being able to link data will be vital for enhancing our understanding of society, driving policy change for greater public good." Sir Ian Diamond, the National Statistician
The Privacy Preserving Record Linkage (PPRL) toolkit demonstrates the feasibility of record linkage in difficult 'eyes off' settings. It has been designed for a situation where two organisations (perhaps in different jurisdictions) want to link their datasets at record level, to enrich the information they contain, but neither party is able to send sensitive personal identifiers - such as names, addresses or dates of birth - to the other. Building on previous ONS research, the toolkit implements a well-known privacy-preserving linkage method in a new way to improve performance, and wraps it in a secure cloud architecture to demonstrate the potential of a layered approach.
The toolkit has been developed by data scientists at the Data Science Campus of the UK Office for National Statistics. This project has benefitted from early collaborations with colleagues at NHS England.
The two parts of the toolkit are:
- a Python package for privacy-preserving record linkage with Bloom filters and hash embeddings, that can be used locally with no cloud set-up
- instructions, scripts and resources to run record linkage in a cloud-based secure enclave. This part of the toolkit requires you to set up Google Cloud accounts with billing
We're publishing the repo as a prototype and teaching tool. Please feel free to download, adapt and experiment with it in compliance with the open-source license. The reference documentation and tutorials are published here. You can submit issues here. However, as this is a prototype, the development team cannot commit to maintaining the repo indefinitely or responding to all issues.
This toolkit is not assured for use in production settings, but we believe the tools and methods demonstrated here have great potential for positive impact with further development and adaptation. If you'd like to collaborate with us, to put these ideas into practice for the public good, please get in touch.
To install the package from source, you must clone the repository before
installing locally via pip:
git clone https://github.com/datasciencecampus/pprl_toolkit.git
cd pprl_toolkit
python -m pip install .If you are developing on (or contributing to) the project, install the package
as editable with the dev optional dependencies:
python -m pip install -e ".[dev]"We also encourage the use of pre-commit hooks for development work. These hooks help us ensure the security of our code base and a consistent code style.
To install these, run the following command from the root directory of the repository:
pre-commit installThe Python package implements the Bloom filter linkage method (Schnell et al., 2009), and can also implement pretrained Hash embeddings (Miranda et al., 2022), if a suitable large, pre-matched corpus of data is available.
Let us consider a small example where we want to link two excerpts of data on bands. In this scenario, we are looking at some toy data on the members of a fictional, German rock trio called "Verknüpfung". In this example we will see how to use untrained Bloom filters to match data.
First, we load our data into pandas.DataFrame objects. Here, the first
records align, but the other two records should be swapped to have an aligned
matching. We will use the toolkit to identify these matches.
>>> import pandas as pd
>>>
>>> df1 = pd.DataFrame(
... {
... "first_name": ["Laura", "Kaspar", "Grete"],
... "last_name": ["Daten", "Gorman", "Knopf"],
... "gender": ["f", "m", "f"],
... "instrument": ["bass", "guitar", "drums"],
... }
... )
>>> df2 = pd.DataFrame(
... {
... "name": ["Laura Datten", "Greta Knopf", "Casper Goreman"],
... "sex": ["female", "female", "male"],
... "main_instrument": ["bass guitar", "percussion", "electric guitar"],
... }
... )Note
These datasets don't have the same column names or follow the same encodings, and there are several spelling mistakes in the names of the band members.
Thankfully, the PPRL Toolkit is flexible enough to handle this!
The next step is to decide how to process each of the columns in our datasets.
The pprl.embedder.features module provides functions that process different data types so that they can be embedded into the Bloom filter. We pass these functions into the embedder in a dictionary called a feature factory. We also provide a column specification for each dataset mapping our columns to column types in the factory.
>>> from pprl.embedder import features
>>> from functools import partial
>>>
>>> factory = dict(
... name=features.gen_name_features,
... sex=features.gen_sex_features,
... instrument=partial(features.gen_misc_shingled_features, label="instrument"),
... )
>>> spec1 = dict(
... first_name="name",
... last_name="name",
... gender="sex",
... instrument="instrument",
... )
>>> spec2 = dict(name="name", sex="sex", main_instrument="instrument")With our specifications sorted out, we can get to creating our Bloom filter
embedding. We can create our Embedder instance and use it to embed
our data with their column specifications. The Embedder object has two more parameters: the size of the filter and the number of hashes. We can use the defaults.
>>> from pprl.embedder.embedder import Embedder
>>>
>>> embedder = Embedder(factory, bf_size=1024, num_hashes=2)
>>> edf1 = embedder.embed(df1, colspec=spec1, update_thresholds=True)
>>> edf2 = embedder.embed(df2, colspec=spec2, update_thresholds=True)We can now perform the linkage by comparing these Bloom filter embeddings. The package uses the Soft Cosine Measure to calculate record-wise similarity scores.
>>> similarities = embedder.compare(edf1, edf2)
>>> similarities
SimilarityArray([[0.81229552, 0.1115206 , 0.09557733],
[0.35460909, 0.16368072, 0.60428527],
[0.11720977, 0.50957391, 0.10343462]])Lastly, we compute the matching using an adapted Hungarian algorithm with local match thresholds:
>>> matching = similarities.match()
>>> matching
(array([0, 1, 2]), array([0, 2, 1]))So, all three of the records in each dataset were matched correctly. Excellent! You can find a longer version of this tutorial here.
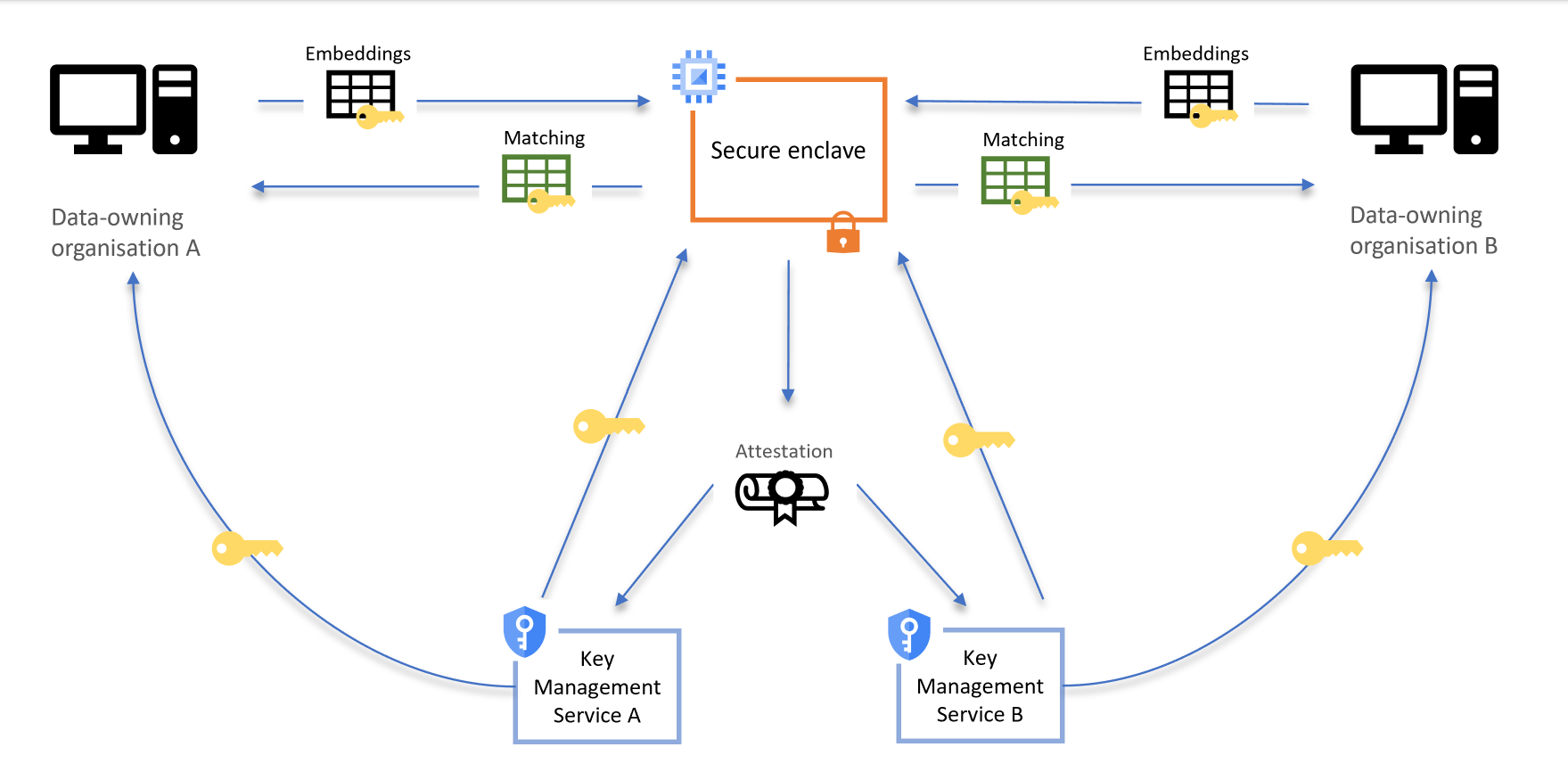
The cloud demo uses a Google Cloud Platform (GCP) Confidential Space compute instance, which is a virtual machine (VM) using AMD Secure Encrypted Virtualisation (AMD-SEV) technology to encrypt data in-memory.
The Confidential Space VM can also provide cryptographically signed documents, called attestations, which the server can use to prove that it is running in a secure environment before gaining access to data.
The cloud demo assigns four roles: two data-owning parties, a workload author, and a workload operator. These roles can be summarised as follows:
- Each data-owning party is responsible for embedding and uploading their data to the cloud. They also download their results.
- The workload author audits and assures the source code of the server, and then builds and uploads the server as a Docker image.
- The workload operator sets up and runs the Confidential Space virtual machine, which uses the Docker image to perform the record linkage.
We have set up the PPRL Toolkit to allow any configuration of these roles among users. You could do it all yourself, split the workload roles between two data owning-parties, or ask a trusted third party to maintain the workload.
Warning
The cloud demo requires you to set up one or more Google Cloud accounts with billing. The cost of running the demo should be very small, or within your free quota. However, you should ensure that all resources are torn down after running the demo to avoid ongoing charges.
Please refer to our cloud tutorial for further details on how to get working in the cloud.
This package is accompanied by documentation which includes tutorials and API reference materials. These are available on GitHub Pages.
If you would like to build the documentation yourself, you will need to install
Quarto. After that, install the docs
optional dependencies for the toolkit:
python -m pip install ".[docs]"Now you can build, render, and view the documentation yourself. First, build the API reference material:
python -m quartodoc buildThis will create a set of Quarto files under docs/reference/. You can render the
documentation itself with the following command, opening a local version of the
site in your browser:
quarto preview