
English|中文
GoBatch is a batch processing framework in Go like Spring Batch in Java. If you are familiar with Spring Batch, you will find GoBatch very easy to use.
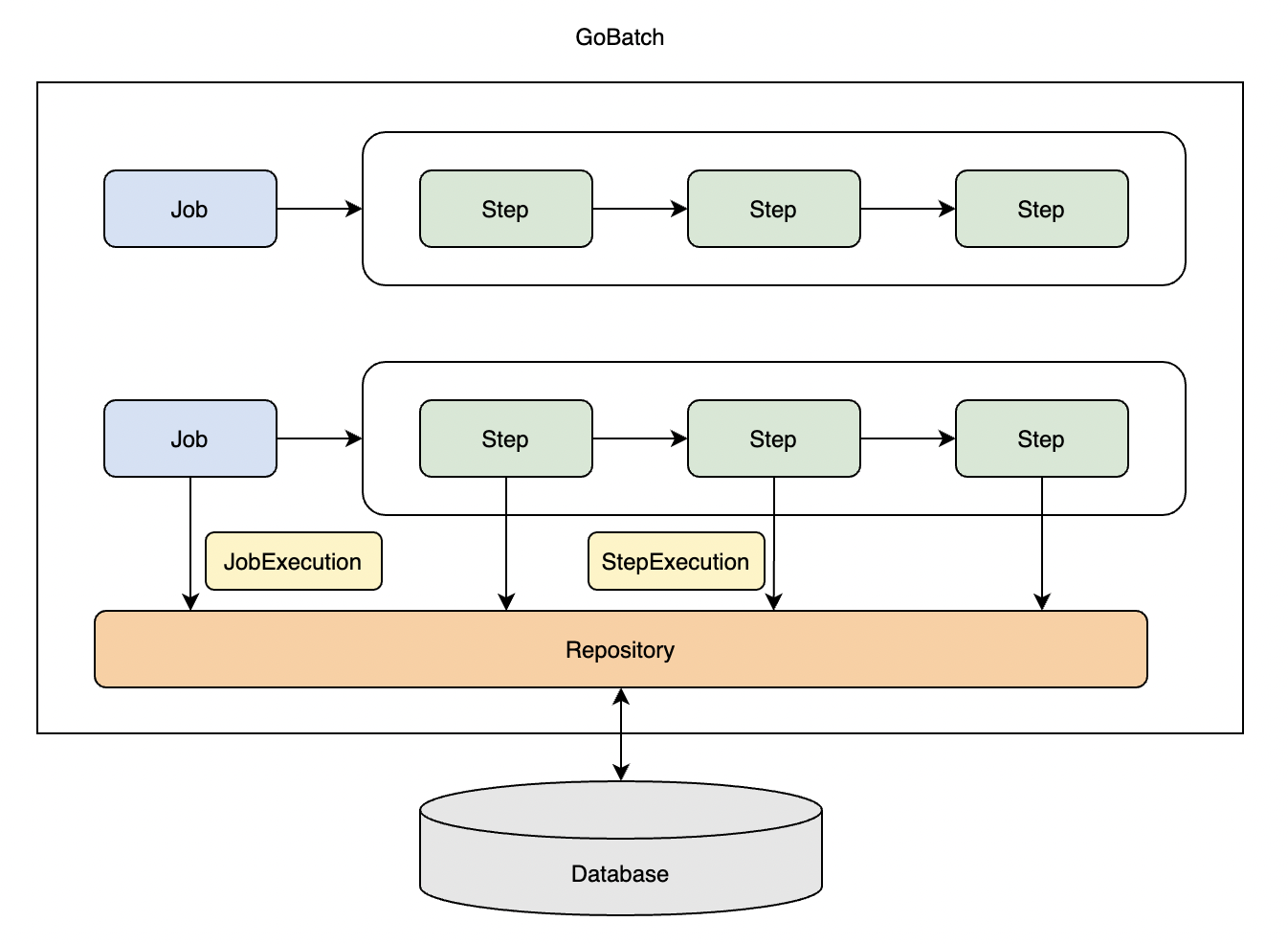
In GoBatch, Job is divided into multiple Steps, the steps are executed successively. GoBatch will create a JobExecution data stored into database when executing a Job, also will create a StepExecution when executing a Step.
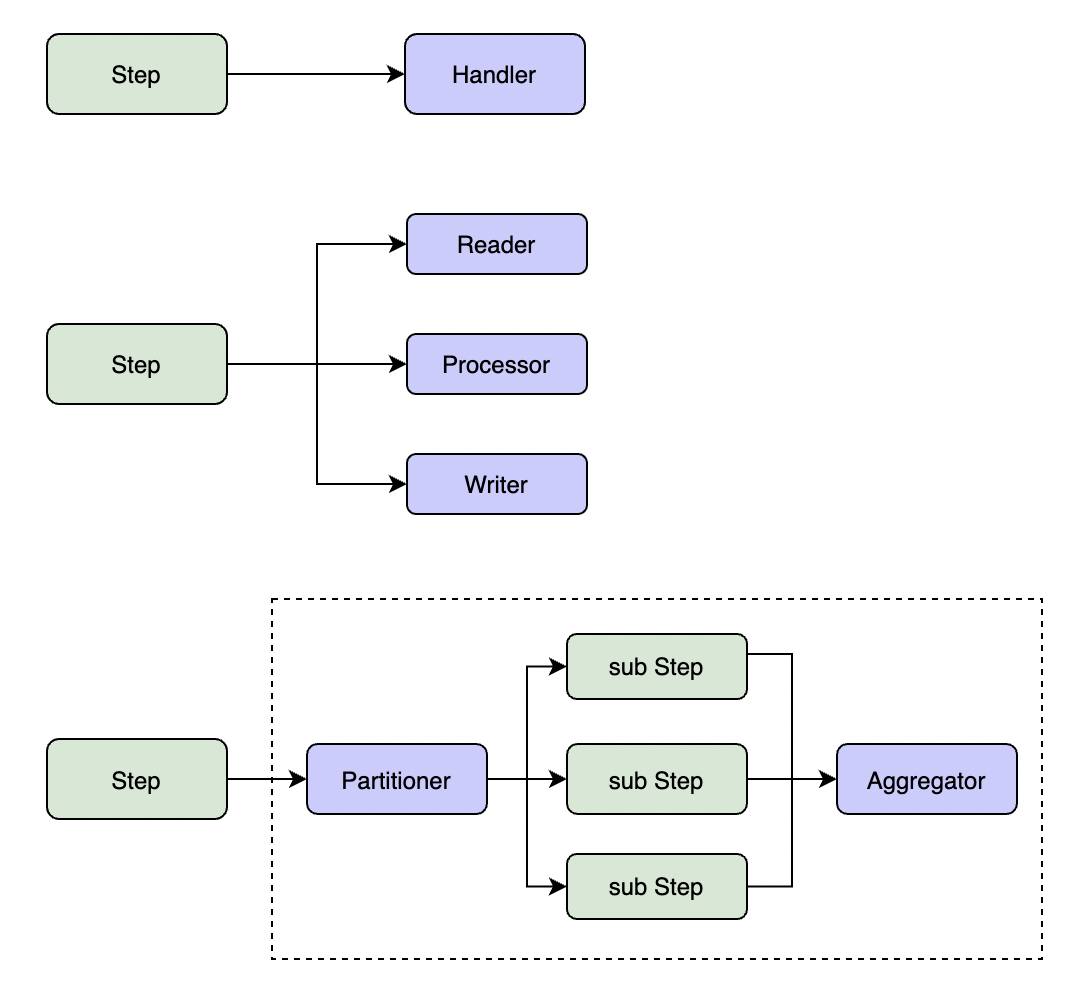
There are three types of step:
- Simple Step execute business logic defined in Handler in a single thread.
- Chunk Step process data by chunks. The process flow is reading a chunk of data, processing it, then writing output. The process is repeated until no more data to read.
- Partition Step split task into multiple sub tasks, then execute sub tasks parallelly in sub steps, and aggregate result of sub steps at last.
- Modular construction for batch application
- Serial and parallel process flow on your need
- Break point to resume job
- Builtin file processing component
- Listeners for job and step execution
- Easy to extend
go get -u github.com/chararch/gobatch- Create or choose a database, eg: gobatch
- Create tables from sql/schema_mysql.sql into previous database
- Write gobatch code and run it
import (
"chararch/gobatch"
"context"
"database/sql"
"fmt"
)
// simple task
func mytask() {
fmt.Println("mytask executed")
}
//reader
type myReader struct {
}
func (r *myReader) Read(chunkCtx *gobatch.ChunkContext) (interface{}, gobatch.BatchError) {
curr, _ := chunkCtx.StepExecution.StepContext.GetInt("read.num", 0)
if curr < 100 {
chunkCtx.StepExecution.StepContext.Put("read.num", curr+1)
return fmt.Sprintf("value-%v", curr), nil
}
return nil, nil
}
//processor
type myProcessor struct {
}
func (r *myProcessor) Process(item interface{}, chunkCtx *gobatch.ChunkContext) (interface{}, gobatch.BatchError) {
return fmt.Sprintf("processed-%v", item), nil
}
//writer
type myWriter struct {
}
func (r *myWriter) Write(items []interface{}, chunkCtx *gobatch.ChunkContext) gobatch.BatchError {
fmt.Printf("write: %v\n", items)
return nil
}
func main() {
//set db for gobatch to store job&step execution context
db, err := sql.Open("mysql", "gobatch:gobatch123@tcp(127.0.0.1:3306)/gobatch?charset=utf8&parseTime=true")
if err != nil {
panic(err)
}
gobatch.SetDB(db)
//build steps
step1 := gobatch.NewStep("mytask").Handler(mytask).Build()
//step2 := gobatch.NewStep("my_step").Handler(&myReader{}, &myProcessor{}, &myWriter{}).Build()
step2 := gobatch.NewStep("my_step").Reader(&myReader{}).Processor(&myProcessor{}).Writer(&myWriter{}).ChunkSize(10).Build()
//build job
job := gobatch.NewJob("my_job").Step(step1, step2).Build()
//register job to gobatch
gobatch.Register(job)
//run
//gobatch.StartAsync(context.Background(), job.Name(), "")
gobatch.Start(context.Background(), job.Name(), "")
}You can look at the code in test/example.go
There are several methods to write a simple step logic:
// 1. write a function with one of the following signature
func(execution *StepExecution) BatchError
func(execution *StepExecution)
func() error
func()
// 2. implement the Handler interface
type Handler interface {
Handle(execution *StepExecution) BatchError
}Once you wrote the function or Handler interface implementation, you can build step like this:
step1 := gobatch.NewStep("step1").Handler(myfunction).Build()
step2 := gobatch.NewStep("step2").Handler(myHandler).Build()
//or
step1 := gobatch.NewStep("step1", myfunction).Build()
step2 := gobatch.NewStep("step2", myHandler).Build()To build a chunk step, you should implement the following interfaces, only the Reader is required:
type Reader interface {
//Read each call of Read() will return a data item, if there is no more data, a nil item will be returned.
Read(chunkCtx *ChunkContext) (interface{}, BatchError)
}
type Processor interface {
//Process process an item from reader and return a result item
Process(item interface{}, chunkCtx *ChunkContext) (interface{}, BatchError)
}
type Writer interface {
//Write write items generated by processor in a chunk
Write(items []interface{}, chunkCtx *ChunkContext) BatchError
}There is another interface named ItemReader, which you can use instead of Reader:
type ItemReader interface {
//ReadKeys read all keys of some kind of data
ReadKeys() ([]interface{}, error)
//ReadItem read value by one key from ReadKeys result
ReadItem(key interface{}) (interface{}, error)
}For convenience, you can implement the following interface along with Reader or Writer to do some initialization or cleanup:
type OpenCloser interface {
Open(execution *StepExecution) BatchError
Close(execution *StepExecution) BatchError
}You could see the chunk step example under test/example2
you can implement the Partitioner interface to split a step into multiple sub steps, optionally you can implement the Aggregator interface if you want to do some aggregation after all sub steps completed:
type Partitioner interface {
//Partition generate sub step executions from specified step execution and partitions count
Partition(execution *StepExecution, partitions uint) ([]*StepExecution, BatchError)
//GetPartitionNames generate sub step names from specified step execution and partitions count
GetPartitionNames(execution *StepExecution, partitions uint) []string
}
type Aggregator interface {
//Aggregate aggregate result from all sub step executions
Aggregate(execution *StepExecution, subExecutions []*StepExecution) BatchError
}If you already have a chunk step with an ItemReader, you can easily build a partition step nothing more than specifying partitions count:
step := gobatch.NewStep("partition_step").Handler(&ChunkHandler{db}).Partitions(10).Build()Suppose a file with the following content(each field seperated by a '\t'):
trade_1 account_1 cash 1000 normal 2022-02-27 12:12:12
trade_2 account_2 cash 1000 normal 2022-02-27 12:12:12
trade_3 account_3 cash 1000 normal 2022-02-27 12:12:12
……We want to read the content and insert each record into a database table named 't_trade', then we do it this way:
type Trade struct {
TradeNo string `order:"0"`
AccountNo string `order:"1"`
Type string `order:"2"`
Amount float64 `order:"3"`
TradeTime time.Time `order:"5"`
Status string `order:"4"`
}
var tradeFile = file.FileObjectModel{
FileStore: &file.LocalFileSystem{},
FileName: "/data/{date,yyyy-MM-dd}/trade.data",
Type: file.TSV,
Encoding: "utf-8",
ItemPrototype: &Trade{},
}
type TradeWriter struct {
db *gorm.DB
}
func (p *TradeWriter) Write(items []interface{}, chunkCtx *gobatch.ChunkContext) gobatch.BatchError {
models := make([]*Trade, len(items))
for i, item := range items {
models[i] = item.(*Trade)
}
e := p.db.Table("t_trade").Create(models).Error
if e != nil {
return gobatch.NewBatchError(gobatch.ErrCodeDbFail, "save trade into db err", e)
}
return nil
}
func buildAndRunJob() {
//...
step := gobatch.NewStep("trade_import").ReadFile(tradeFile).Writer(&TradeWriter{db}).Partitions(10).Build()
//...
job := gobatch.NewJob("my_job").Step(...,step,...).Build()
gobatch.Register(job)
gobatch.Start(context.Background(), job.Name(), "{\"date\":\"20220202\"}")
}Suppose we want export data in 't_trade' to a csv file, we can do like this:
type Trade struct {
TradeNo string `order:"0" header:"trade_no"`
AccountNo string `order:"1" header:"account_no"`
Type string `order:"2" header:"type"`
Amount float64 `order:"3" header:"amount"`
TradeTime time.Time `order:"5" header:"trade_time" format:"2006-01-02_15:04:05"`
Status string `order:"4" header:"trade_no"`
}
var tradeFileCsv = file.FileObjectModel{
FileStore: &file.LocalFileSystem{},
FileName: "/data/{date,yyyy-MM-dd}/trade_export.csv",
Type: file.CSV,
Encoding: "utf-8",
ItemPrototype: &Trade{},
}
type TradeReader struct {
db *gorm.DB
}
func (h *TradeReader) ReadKeys() ([]interface{}, error) {
var ids []int64
h.db.Table("t_trade").Select("id").Find(&ids)
var result []interface{}
for _, id := range ids {
result = append(result, id)
}
return result, nil
}
func (h *TradeReader) ReadItem(key interface{}) (interface{}, error) {
id := int64(0)
switch r := key.(type) {
case int64:
id = r
case float64:
id = int64(r)
default:
return nil, fmt.Errorf("key type error, type:%T, value:%v", key, key)
}
trade := &Trade{}
result := h.db.Table("t_trade").Find(trade, "id = ?", id)
if result.Error != nil {
return nil, result.Error
}
return trade, nil
}
func buildAndRunJob() {
//...
step := gobatch.NewStep("trade_export").Reader(&TradeReader{db}).WriteFile(tradeFileCsv).Partitions(10).Build()
//...
}There are different listeners for the lifecycle of job and step execution:
type JobListener interface {
BeforeJob(execution *JobExecution) BatchError
AfterJob(execution *JobExecution) BatchError
}
type StepListener interface {
BeforeStep(execution *StepExecution) BatchError
AfterStep(execution *StepExecution) BatchError
}
type ChunkListener interface {
BeforeChunk(context *ChunkContext) BatchError
AfterChunk(context *ChunkContext) BatchError
OnError(context *ChunkContext, err BatchError)
}
type PartitionListener interface {
BeforePartition(execution *StepExecution) BatchError
AfterPartition(execution *StepExecution, subExecutions []*StepExecution) BatchError
OnError(execution *StepExecution, err BatchError)
}You can specify listeners during building job:
func buildAndRunJob() {
//...
step := gobatch.NewStep("my_step").Handler(handler,...).Listener(listener,...).Build()
//...
job := gobatch.NewJob("my_job").Step(step,...).Listener(listener,...).Build()
}GoBatch needs a database to store job and step execution contexts, so you must pass a *sql.DB instance to GoBatch before running job.
gobatch.SetDB(sqlDb)If you are trying to build a chunk step, you must register a TransactionManager instance to GoBatch, the interface is:
type TransactionManager interface {
BeginTx() (tx interface{}, err BatchError)
Commit(tx interface{}) BatchError
Rollback(tx interface{}) BatchError
}GoBatch has a DefaultTxManager, if you have set DB and have no TransactionManager set yet, GoBatch also create a DefaultTxManager instance for you.
GoBatch has internal TaskPools to run jobs and steps, the max running jobs and steps are limited by the pool size. The default value of the max running jobs and steps are 10, 1000. You can change the default settings by:
gobatch.SetMaxRunningJobs(100)
gobatch.SetMaxRunningSteps(5000)