VI. Engine Installation (EngineInstall)
When JDLL is installed, none of the engines needed to run Deep Learning (DL) models are downloaded with it. There are more than 20 engines per Operating System (OS), thus in order to avoid dowloading an excesive amount of data, the user will decide which are the engines that they need.
JDLL allows the user to run any combination of engines in the same session, meaning that Tensorflow 1, Tensorflow 2, Pytorch or any other supported Java DL framework can be used one after another without needing to re-start the software. Models from different frameworks can now be combined in the same workflow.
This feat is achieved thanks to the a separate dynamic classloading system that loads each of the engine required JAR files in a separate classloader avoiding the conflicts that appear in the classspace with some of the DL frameworks. To enable the separate loading, each of the engines has to be downloaded in a separate folder, which is named following a naming convention that allows its identification. All the engine folders must be in the same directory.
The engine convention followed by each of the engine folders goes as follows:
<DL_framework_name>-<python_version>-<java_api_version>-<os>-<architecture>-<cpu_if_it_runs_in_cpu>-<gpu_if_it_runs_in_gpu>
Some names examples of existing engines are:
tensorflow-2.7.0-0.4.0-windows-x86_64-cpu-gpupytorch-1.13.1-1.13.1-arm64-cputensorflow-1.15.0-1.15.0-linux-x86_64-cpuonnx-17-1.12.1-macosx-x86_64-cpu-gpu
Below there is an example of how the directory where the engines are installed would look like. Also regard which are the contents of an engine folder:
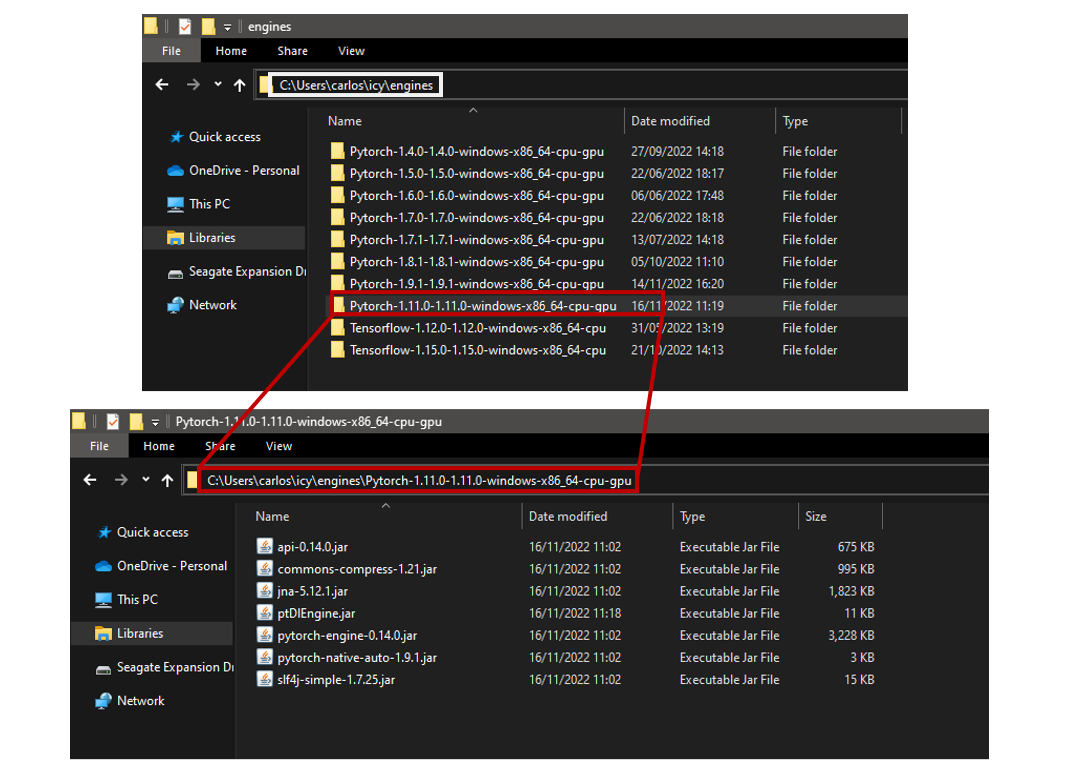
A JDLL engine consists in the JAR files that are required to load the corresponding DL framework in Java. The JARs required per engine, version and OS are specified in this json file
As previously mentioned, JDLL is downloaded without engines, to start using DL models in Java the required engines need to be installed depending on the needs of the user.
The installation of engines can be done manually, creating the corresponding folders and downloading the specific [JARs] (https://github.com/bioimage-io/model-runner-java/blob/main/src/main/resources/availableDLVersions.json). However, as manually installing the engines is not optimal, JDLL enables the installation and management of engines with code.
The class EngineInstall from the package io.bioimage.modelrunner.engine.installation contains several static methods to install easily a Deep Learning framework and track its download.
EngineInstall.installEngineWithArgsInDir(String framework, String version, boolean cpu, boolean gpu, String dir)
Install an engine of interest providing the parameters that define it.
-
framework: the DL framework of intererst (pytorch,tensorflow,onnx) -
version: the version of the DL framework we want to install (2.7.0,1.3.0,...). The supported versions correspond to the tagpythonVersionin this file -
cpu: whether the engine supports CPU or not -
gpu: whether the engine supports GPU or not -
dir: directory where the engine will be installed. The directory where the engine folder will be downloaded.
Regard that the method EngineInstall.installEngineWithArgs(String framework, String version, boolean cpu, boolean gpu) also exists. The only difference is that this method downloads the engine into a directory called engines inside the software directory.
If the engine specified does not exist or is not supported an exception will be thrown.
Regard that the method EngineInstall.installEngineWithArgs(String framework, String version, boolean cpu, boolean gpu) also exists. The only difference is that this method downloads the engine into a directory called engines inside the software directory.
Install an engine of interest providing the parameters that define it.
-
engine:DeepLearningVersionobject that defines a JDLL engine. The classAvailableEnginesfrom the packageio.bioimage.modelrunner.versionmanagementprovides several methods that return lists ofDeepLearningVersionobjects filtered by framewoks or OS. For example the methodAvailableEngines.getAll()reads the JSON file and returns a list containing all the engines supported by JDLL asDeepLearningVersionobjects. The method 'AvailableEngines.getForCurrentOS()' returns the same but only considering the engines compatible with the OS where JDLL is running. -
engineDir: directory where the engine will be installed. The directory where the engine folder will be downloaded.
The Java class DeepLearningVersion is defined by JDLL. Another useful methods to get available engines as DeepLearningVersion objects is AvailableEngines.getEngineForOsByParams(String framework, String version, boolean cpu, boolean gpu). This method retrieves the supported engines that fulfil the arguments. I any of the arguments is null, the parameter will not be taken into accout for filtering the engines.
JDLL is strongly is strongly integrated with the Bioimage.io. JDLL tries to simplify as much as possible running models from the Bioimage.io repository. This implies easying the installation of the required engine by the model.
There are several methods to install the DL frameworks needed by a Bioimage.io model directly:
Installs the engines supported by JDLL that are required by the Bioimage.io model, as specified in the weightsfield of the rdf.yaml file.
-
modelFolder: folder of the Bioimage.io model. It is the parent directory of the rdf.yaml file -
enginesDir: directory where the engines will be installed
Installs the engines supported by JDLL that are required by the Bioimage.io model, as specified in the weightsfield of the rdf.yaml file. The model is identified by its name (the field name in the rdf.yaml file).
-
modelName: name of the model as defined in the fieldnameof the rdf.yaml -
enginesDir: directory where the engines will be installed
Installs the engines supported by JDLL that are required by the Bioimage.io model, as specified in the weightsfield of the rdf.yaml file. The model is identified by its name (the field id in the rdf.yaml file).
-
modelID: model id of the model as defined in the fieldidof the rdf.yaml -
enginesDir: directory where the engines will be installed
Instances of JDLL classes, such as ModelDescriptor can also be used for the sam purpose, as it is explained below.
Installs the engines supported by JDLL that are required by the Bioimage.io model, as specified in the weightsfield of the rdf.yaml file. The model is identified by the ModelDescriptor object that contains the rdf.yaml info.
-
descriptor: ModelDescriptor object containing all the info of the rdf.yaml file -
enginesDir: directory where the engines will be installed
Some of the JDLL engines contain relatively big files (>100MB) that depending on the Internet connection of the user, might take some minutes to be downloaded, making the corresponding method used take some time to finish.
In order to enable a good user experience and favour comprehensive and intuitive user interafces, all the methods defined above can take another argument, DownloadTracker.TwoParameterConsumer<String, Double> consumer. This argument is a funcitonal interface that tracks the progress of the download of each of the JAR files of the engine. Note that it is not provided or if it is equal to ``null`, it will simply be ignored.
A DownloadTracker.TwoParameterConsumer<String, Double> can be created as follows:
DownloadTracker.TwoParameterConsumer<String, Double> consumer = DownloadTracker.createConsumerProgress();
and if it is provided to any of the install engine methods, it can be used in a separate thread to track the progress of the download.
This object contains a LinkedHashMap<String, Double> where each key is the complete path in the system to the file that is being downloaded and the value is the progress over 1 of the download. When the download is finished, all the values have to be 1.
In order to get the progress LinkedHashMap<String, Double>:
LinkedHashMap<String, Double> progress = consumer.get();
A more detailed example of how to use this object to track downloads can be seen here or here.
Currently, the following DL frameworks are supported:
| Framework | Source code | Tag used in JDLL to refer to the framework | Bioimage.io tag |
|---|---|---|---|
| PyTorch | https://github.com/bioimage-io/pytorch-java-interface |
pytorch or torchscript
|
torchscript |
| Tensorflow 1 | https://github.com/bioimage-io/tensorflow-1-java-interface |
tensorflow or tensorflow_saved_model_bundle
|
tensorflow_saved_model_bundle |
| Tensorflow 2 API 0.2.0 | https://github.com/bioimage-io/tensorflow-2-java-interface-0.2.0 |
tensorflow or tensorflow_saved_model_bundle
|
tensorflow_saved_model_bundle |
| Tensorflow 2 API 0.3-0.4 | https://github.com/bioimage-io/tensorflow-2-java-interface |
tensorflow or tensorflow_saved_model_bundle
|
tensorflow_saved_model_bundle |
| Tensorflow 2 API 0.5.0 | https://github.com/bioimage-io/tensorflow-2-java-interface-0.5.0 |
tensorflow or tensorflow_saved_model_bundle
|
tensorflow_saved_model_bundle |
| Onnx | https://github.com/bioimage-io/onnx-java-interface | onnx |
onnx |
The information about the engines supported currently by the model runner, for which OS and architectures and which JAR files are required for each of the engines is stored in this json file.
Note that the model runner will be in constant development and that it is open to community collaboration, so pull requests to the official repository of the model runner to improve functionality or to add new engines are very welcomed.
Deep Learning is a very rapidly changing field. DL frameworks need to keep up with the changes of the field adapting to them, which makes them release new versions frequently and efficiently. However, in order to avoid the chaos that would emerge if already trained models where only runnable by a small subset of the available versions, the DL frameworks developers carefully design the libraries to provide great backwards compatibility with the previous ones.
In practice, the vast majority of models that a user will encounter will be compatible with the latest version of the DL framework used to train it. For the case of JDLL, installing the latest vesion of Tensorflow 1, Tensorflow 2, Pytorch 1, Pytorch 2 and Onnx will allow the user running almost every model supported by JDLL.
Installing a version per one of the frameworks supported (Tensorflow 1, Tensorflow 2, Pytorch 1, Pytorch 2 and Onnx) is what we call the basic or minimal installation of engines.
In order to avoid the complexity of installing several engines for each particular model, the basic engine installation can set up one engine per framework to be compatible with the majority of models, reducing not only complexity for the user, but the amount of disk space used by all the extra engines.
JDLL provides direct methods to install the basic engines with just one or a couple of lines. First, the creation of an EngineInstall instance from the package io.bioimage.modelrunner.engine.installation is necessary. It can be done like the following:
String installationDir = "/path/where/we/want/to/install/the/engines";
EngineInstall manager = EngineInstall.createInstaller(installationDir);
Once created, the following methods are available
Installs the latest version of each framework (JDLL considers major versions of the same DL frameworks as different) supported by JDLL. At the moment of writing, it will install Pytorch 1.13.1 for Pytorch 1; Pytorch 2.0.0 for Pytorch 2; Tensorflow 1.15.0 for Tensorflow 2; Tensorflow 2.7.0 for Tensorflow 2 and Onnx 1.12.1 (o`pset 17) for Onnx. If a newer engine or a new framework are added to the availableDLEngines.json, the versions installed will be updated, for example if Pytorch 2.1 is added, it will be installed instead of Pytorch 2.0.
Regard that if any of the basic engines has already been installed, it will not be reinstalled.
In order to keep track of the installation, this mehtod can be called before manager.basicEngineInstallation(). The method will return a map, where each key is the framework name plus the major version of the engine (pytorch1, tensorflow2...) and the value is a DownloadTracker.TwoParameterConsumer<String, Double> from the package io.bioimage.modelrunner.bioimageio.download that contains another LinkedHashMap internally where the key is the directory is the file being installed and the value is the progress of the installation over 1.
Regard that the map will only contain the engines that have not been installed, if any of the main engines has already been installed, it will not have a consumer to track its download, as tehre will be no download.
The Map of DownloadTracker.TwoParameterConsumer<String, Double> can beused to track the download of the different engines in another thread. For more info similar to this, click here.
Another interesting method is manager.getMissingEngines() which returns what are the basic minimal engines taht have not yet been installed.