Home
I File System Distribuiti, in particolare i Grid File System, garantiscono affidabilità, efficienza e scalabilità nella memorizzazione di grosse quantità di dati. In questo articolo si discuterà in particolare del file system GridFS integrato all’interno del DBMS NoSQL MongoDB. Verrà presentata un’applicazione Java dotata di GUI che consentirà un facile interfacciamento con MongoDB così da poter svolgere tutte le operazioni tipiche dei File System tradizionali. Si introdurrà anche una tecnica per l’implementazione di sotto-directory (funzionalità non prevista originariamente da GridFS). Infine, si effettuerà una breve comparazione in termini di spazio con i file system FAT32, NTFS ed Ext4.
MongoDB è un DMBS NoSQL sviluppato da MongoDB Inc. molto popolare ed utilizzato da grandi società come eBay e SourceForce e da istituti di ricerca come il CERN.
MongoDB rientra tra i DMBS document-oriented poiché rappresenta i dati sotto forma di file, in particolare utilizzando il formato BSON (una rappresentazione in binario del formato JSON). Ciascuna informazione, cioè ciascun Document (documento), sarà caratterizzata da un insieme di Chiavi a cui viene associato un valore (si veda Figura 1).
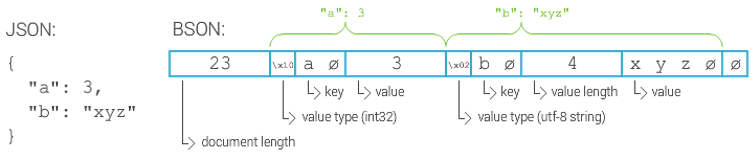
I documenti che condividono le stesse chiavi sono raggruppati in una Collection (collezione). Ciascuna collezione conterrà pertanto un insieme di file omogenei. Non vi è alcun vincolo di unicità nella definizione delle collezioni ovvero possono esistere più collezioni che contengono documenti con gli stessi campi. Questa proprietà è fondamentale per il funzionamento di GridFS.
GridFS è un modello di dati che consente di organizzare i file all’interno di un database MongoDB.
Per garantire affidabilità e scalabilità, il modello GridFS utilizza la filosofia dei Grid File System ovvero suddivide i dati di un file da inserire nel database in piccole porzioni chiamate Chunks. La dimensione di default dei chunks è di 255 KByte ma può essere configurata dall’utente.
Ciascun file verrà quindi memorizzato in MongoDB utilizzando due diverse Collection:
- “.files” che conterrà i metadati del file (ID, data di creazione, dimensione, MD5 ed altri campi impostabili);
- “.chunks” che conterrà un puntatore al rispettivo documento di tipo “.files” e un campo binario contenente i dati.
Le due collection, per la proprietà vista prima, possono essere presenti in più copie all’interno di un database. Ciascuna coppia viene denominata Bucket e le due collection in MongoDB assumeranno la denominazione “NomeBucket.files” e “NomeBucket.chunks”.
Quando un file viene inserito in GridFS, sarà possibile selezionare il suo Bucket. In caso contrario, GridFS utilizzerà il Bucket di default “fs”.
GridFS si adatta molto bene al modello dati di un comune File System anche se ci sono alcune considerazioni sul mapping e dei limiti da affrontare.
Innanzitutto, MongoDB come qualsiasi altro DBMS offre la possibilità di gestire più database che possono essere opportunamente protetti per consentire l’accesso solamente ad alcuni utenti. Ciascun database si può pertanto mettere in analogia con:
- Un disco, una partizione o una qualsiasi unità fisica o logica;
- Una directory assegnata ad un utente (Home Directory).
Nel caso in cui si voglia utilizzare GridFS come sistema di backup decentralizzato o si voglia mantenere un approccio più legato ai dispositivi fisici di memorizzazione, la prima scelta è l’ideale. La seconda possibilità è invece più “user-oriented” ed è chiaramente più appropriata in contesti multi utente. Si può anche utilizzare un approccio misto. Ad esempio si possono creare delle Home Directory (una per ciascun utente) ed altri Dischi condivisi tra più utenti.
Il Bucket è un’oggetto specifico di GridFS che non esiste direttamente in MongoDB. Si può considerare un’astrazione logica della coppia di collection “.files” e “.chunks” necessaria alla memorizzazione dei file. Quindi, su MongoDB si può agire sulle Collection mentre su GridFS si può agire sui Bucket.
Il Bucket è l’analogo delle directory in un file system a due livelli, ossia un file system nel quale in ogni disco (il primo livello) è presente un solo livello di directory (il secondo livello).
La limitazione appena illustrata è data dal fatto che in GridFS non è possibile inserire un Bucket all’interno di un Bucket. Ciò si traduce nel fatto che non si possono avere nativamente delle sotto-directory.
Infine, l’analogia tra il Document di MongoDB, il File di GridFS ed il file del File System è immediata. Va solamente ricordato che in MongoDB per ogni file si ha un documento appartenente alla collection “.files” e uno o più documenti appartenenti alla collection “.chunks”. Inoltre, poiché ogni File deve necessariamente appartenere ad un Bucket, non si possono inserire dei file direttamente all’interno di un disco (database).
La Tabella 1 confronta i data model appena analizzati inserendo anche un confronto con il modello relazionale.

Tabella 1 - Confronto tra modelli di dati: DBMS Relazionale, MongoDB, GridFS e File System tradizionale
Tabella 1 - Confronto tra modelli di dati: DBMS Relazionale, MongoDB, GridFS e File System tradizionale
La creazione di sotto-directory, che come si è visto non è supportata da GridFS, può essere simulata attraverso un’opportuna strategia di denominazione dei Bucket.
In particolare, se si vuole inserire una directory “Y” all’interno di una directory “X”, si può creare un Bucket denominato “X/Y”.
Per GridFS, i due Bucket corrispondenti alle directory saranno situati allo stesso livello, ossia all’interno del database in uso. Bisogna pertanto agire a livello di “visualizzazione” implementando una tecnica che effettua il list di una directory (cioè l’analogo di un comando “dir” su Windows o “ls” su Linux) tenendo conto del nome delle altre directory del disco.
Quando si sta eseguendo il list del disco, bisognerà considerare solamente le directory il cui nome non contiene “/” (come ad esempio “X”).
Quando invece si sta visualizzando il contenuto di una directory (ad esempio “X”) bisognerà considerare, oltre ai file contenuti in essa, solamente le directory che iniziano nello stesso modo della directory e che sono seguite da un solo “/” (ad esempio “X/Y”). Quest’ultima condizione impedisce che un’eventuale directory denominata “X/Y/Z” sia considerata nel list di “X” (va invece considerata quando si effettua il list di “X/Y”).
La Figura 2 mostra la gerarchia imposta da GridFS e la strategia utilizzata per superare la limitazione appena discussa.
Per navigare il file system è necessario introdurre anche il concetto di Parent Directory. Sempre a livello di visualizzazione, dovrà essere inserita una directory fittizia che ha come unico scopo quello di far ritornare la visualizzazione ad un livello superiore (in molti file system questa directory viene indicata con “..”). Questa directory non avrà la necessità di essere memorizzata su GridFS ma solamente di essere presentata all’utente.
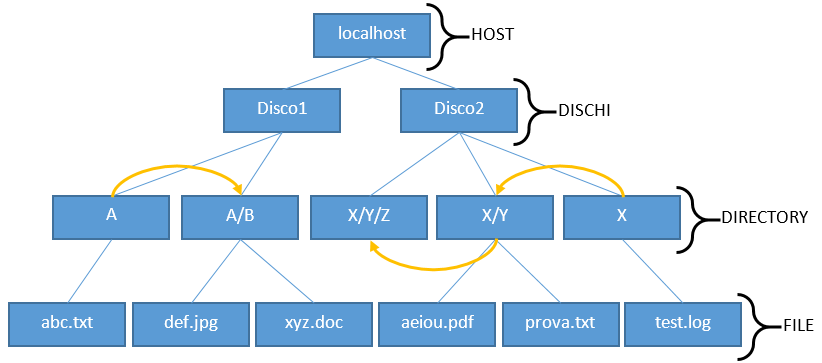
Figura 2 - Gerarchia del File System (in giallo le relazioni “virtuali” tra le directory e le rispettive sotto-directory)
Figura 2 - Gerarchia del File System (in giallo le relazioni “virtuali” tra le directory e le rispettive sotto-directory)
L’utilizzo della funzionalità Replica Set, consente di creare un DBMS distribuito altamente affidabile grazie alla duplicazione dei dati contenuti in esso.
I server MongoDB (avviati tramite il servizio “mongod”) dovranno essere configurati opportunamente.
Nel file di configurazione “mongod.cfg” di ogni server bisognerà abilitare il blocco “replication:” ed aggiungere “replSetName: ” (tutti i server dovranno condividere lo stesso nome del Replica Set ed essere visibili in rete).
A questo punto sarà necessario connettersi ad uno dei server (attraverso la shell “mongo”) ed eseguire il comando “rs.initiate()” che si occupa di inizializzare il Replica Set.
Infine, si dovranno aggiungere gli altri server al Replica Set attraverso il comando “rs.add(“IP:PORTA”)”.
Attraverso un meccanismo di elezione gestito da MongoDB, uno dei server sarà sempre considerato PRIMARY mentre tutti gli altri saranno considerati SECONDARY. Se si desidera forzare una nuova elezione sarà sufficiente utilizzare il comando “rs.stepDown()” sul PRIMARY.
I client dovranno necessariamente comunicare con il PRIMARY per effettuare delle modifiche ai dati (che verranno replicate sui SECONDARY). Quindi, anche se i Replica Set garantiscono la tolleranza ai guasti, non sono sufficienti a garantire la scalabilità orizzontale della rete. Se si desidera ottenere scalabilità orizzontale sarà necessario considerare un’altra funzionalità offerta da MongoDB chiamata Sharding.
L’applicazione Java ha il compito di creare un’interfaccia tra MongoDB GridFS (il server) e l’utente.
L’architettura software più indicata è pertanto la MVC (Model-View-Controller) che garantisce un’adeguata separazione tra l’interfaccia grafica con cui dovrà interagire l’utente e la logica di controllo che dovrà gestire gli input provenienti sia dall’interfaccia grafica che da MongoDB.
L’organizzazione delle classi è la seguente (si veda anche la Figura 3 per consultare le interazioni):
- Model:
- Classe Record: Memorizza le informazioni di un singolo record da visualizzare nella tabella dell’interfaccia grafica.
- View:
- Classe GridFSGUI: Disegna l’interfaccia grafica e cattura gli eventi dovuti all’interazione con l’utente per mezzo delle librerie Java AWT e Swing.
- Classe FileDrop: Si occupa specificatamente di gestire il drag&drop dei file da inserire.
- Controller:
- Classe GridFSController: Gestisce gli eventi provenienti dalla classe GridFSGUI, seleziona i dati da visualizzare per mezzo della classe Record e interagisce con MongoDB utilizzando il [Driver Java] (http://mongodb.github.io/mongo-java-driver/3.8) (versione 3.8.1, inserito tramite Maven).
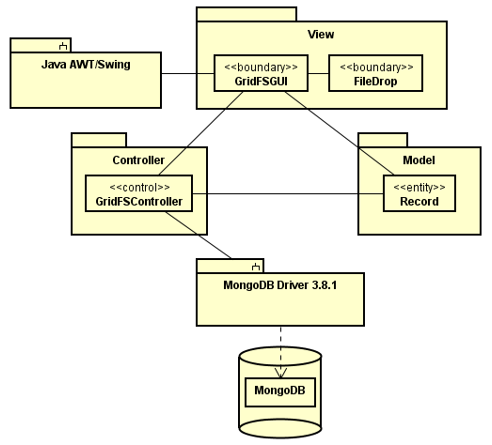
La classe GridFSController gestisce tutte le operazioni tipiche dei File System ossia:
- Upload e Download di file;
- Creazione di directory e dischi;
- Duplicazione di dischi;
- Ridenominazione di file, directory e dischi;
- Eliminazione di file, directory e dischi.
- List dell’host (o Replica Set), dei dischi e delle directory.
In molti casi sono stati implementati metodi separati per ogni tipologia di oggetto poiché per ognuno di essi il Driver offre un diverso interfacciamento.
Dopo aver eseguito l’operazione richiesta, il controller si occupa di aggiornare l’interfaccia grafica ed in particolare la tabella principale che visualizza il list della directory o del disco corrente. Ciascuna riga della tabella viene modellata utilizzando la classe Record.
Per la ridenominazione dei dischi, il Driver non offre nessun metodo e pertanto il metodo di ridenominazione non fa altro che creare una copia del disco con un nuovo nome e cancellare il precedente. Questa procedura inevitabilmente può richiedere molto più tempo di quanto ci si potrebbe aspettare da una ridenominazione.
Per le operazioni di list, si è tenuto conto della gerarchizzazione vista in precedenza. In particolare, nel caso del list delle directory, saranno visualizzati prima i nomi delle directory al livello immediatamente successivo e poi i file presenti nella directory. Per il list dell’host è stata prevista la possibilità di visualizzare anche i database non GridFS presenti nel DBMS ma viene impedita qualsiasi altra operazione su di essi.
Per quanto riguarda la connessione a MongoDB, sono stati implementati due metodi separati che si occupano della connessione ad un singolo host oppure ad un Replica Set (in questo caso il Driver accetta in input un elenco di host appartenenti al Replica Set e si occuperà autonomamente di trovare il PRIMARY a cui connettersi).
Infine è stato implementato un metodo che stampa su file un list completo di tutti i dischi dell’host senza utilizzare la gerarchia tra le directory. Può essere utile per effettuare statistiche o per debug (ad esempio per verificare che la gerarchia visualizzata dal software sia compatibile con i bucket presenti nei database).
L’interfaccia grafica, come in molte interfacce per file system, è incentrata sulla visualizzazione degli oggetti contenuti nella posizione corrente (si veda Figura 4).
Una tabella posizionata al centro visualizza gli oggetti e alcune informazioni utili su di essi. Ogni riga della tabella sarà formata da 4 campi:
- Tipo: DISK, NO_GRIDFS (per Database non GridFS), PARENT_DIR (directory virtuale che avvia il list della directory al livello superiore), DIR e FILE;
- Nome;
- Dimensione: in Byte;
- ID – Numero Elementi: per i file viene visualizzato l’ID (stabilito da MongoDB in fase di inserimento) mentre per le directory e i dischi viene visualizzato il numero di file presenti (NOTA: per le directory il numero di elementi si riferisce ai file direttamente presenti nella directory e non a quelli presenti nelle sotto-directory).
L’operazione di list viene avviata cliccando direttamente sulla riga della tabella nel caso in cui la tipologia sia DISK, DIR o PARENT_DIR (Figura 5). Se invece si sta selezionando un file, viene avviato il download (si aprirà una finestra di tipo File Chooser).
L’operazione di upload viene avviata trascinando il file da caricare all’interno della tabella.
Tutte le altre operazioni vengono avviate cliccando sui rispettivi bottoni presenti sotto la tabella.
Sopra la tabella si trova invece l’area dedicata alla connessione con MongoDB e il bottone che avvia la stampa del report su file. È presente anche una textbox che visualizza il percorso corrente nel formato “IP_HOST:PORTA_HOST>/PATH/”.
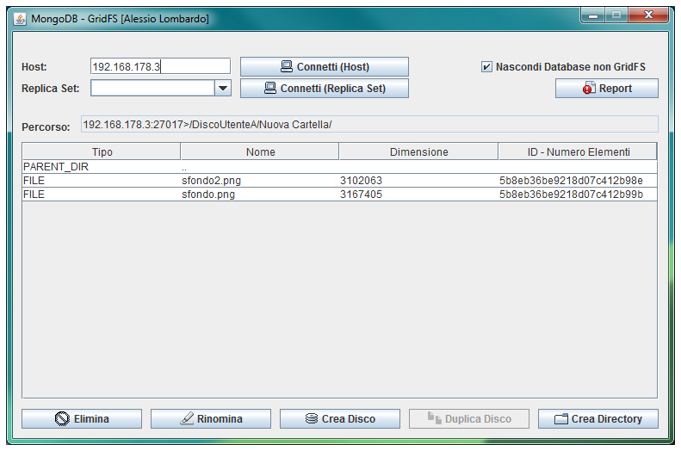
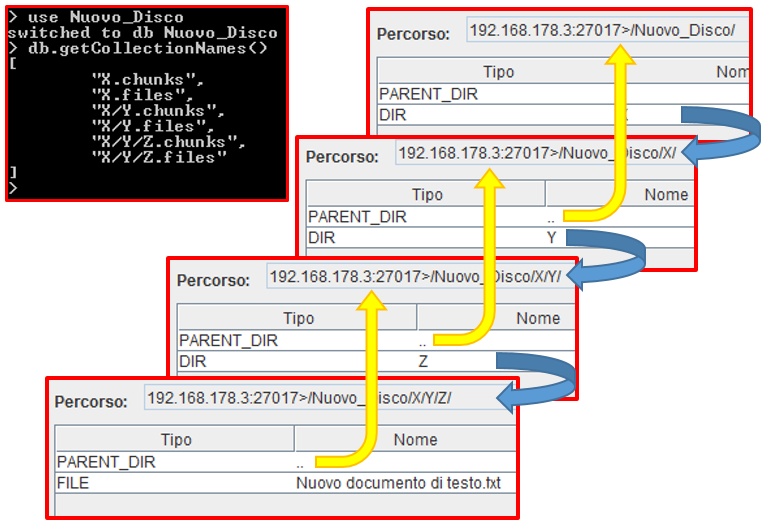
Figura 5 - Gerarchia di directory: confronto tra la memorizzazione su MongoDB e la visualizzazione sul software
Figura 5 - Gerarchia di directory: confronto tra la memorizzazione su MongoDB e la visualizzazione sul software
Il DBMS MongoDB, alla versione 4.0.1, è stato installato su tre macchine connesse in un’unica LAN con le seguenti caratteristiche:
- Windows 7 SP1 x64, Intel i5-2520M 2.50GHz Dual-Core, RAM DDR3 4GB;
- Windows 10 x64, AMD Athlon X2 QL 64 2.10GHz Dual-Core, RAM DDR2 4GB;
- Linux Ubuntu 18.04 x64, Intel i5-2400 3.10GHz Quad-Core, RAM DDR3 4GB.
Su Windows MongoDB è stato installato “come servizio” e senza l’utility MongoDB Compass. Su Linux Ubuntu è stato utile il supporto di questa guida.
Il software è stato testato sulle due macchine Windows.
In fase di scrittura del software, si è provveduto ad effettuare delle operazioni di prova sui singoli host verificandone il corretto funzionamento attraverso la shell “mongo”. In seguito si è costituito un Replica Set composto dai tre host e sono stati effettuati nuovamente dei test riguardanti tutte le operazioni implementate dal software. Nei PC Windows è stato necessario disabilitare il firewall.
Si è verificata la ridondanza dei dati sia disconnettendo alternativamente gli host sia forzando nuove elezioni del PRIMARY attraverso il comando “rs.stepDown()”.
Infine sono stati effettuati alcuni inserimenti di file sul Replica Set e su tre partizioni di un disco formattate rispettivamente in FAT32, NTFS ed Ext4. Nella Tabella 2 sono trascritte le dimensioni dei file inseriti e dello spazio occupato dal disco GridFS del Replica Set e dalle tre partizioni.
La dimensione del database è stata prelevata utilizzando un apposito metodo fornito dal Driver. Bisogna comunque considerare che in questa misura non rientrano le dimensioni degli index (che risiedono in memoria centrale) e dei file necessari al funzionamento di MongoDB.
Lo spazio occupato delle partizioni FAT32 ed NTFS è stato prelevato da Windows (finestra “Proprietà”). Per la partizione Ext4 si è utilizzato il comando “du --block-size=1” su Linux.
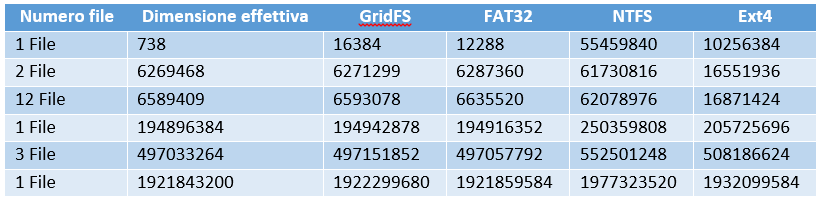
Tabella 2 - Confronto tra dimensioni reali e dimensioni su disco nei File System GridFS, FAT32, NTFS ed Ext4
Tabella 2 - Confronto tra dimensioni reali e dimensioni su disco nei File System GridFS, FAT32, NTFS ed Ext4
Dal grafico in Figura 6 si deduce che lo spazio occupato dal database GridFS inizia ad essere paragonabile alla dimensione effettiva dei file già con pochi MB di dati inseriti.
Ext4 ed NTFS richiedono invece centinaia di MB affinché lo spazio occupato sia paragonabile alla dimensione effettiva dei file.
FAT32 ha prestazioni molto simili a GridFS ma attualmente risulta obsoleto su dischi di grandi dimensioni (vi sono limiti nella dimensione dei file e delle partizioni).
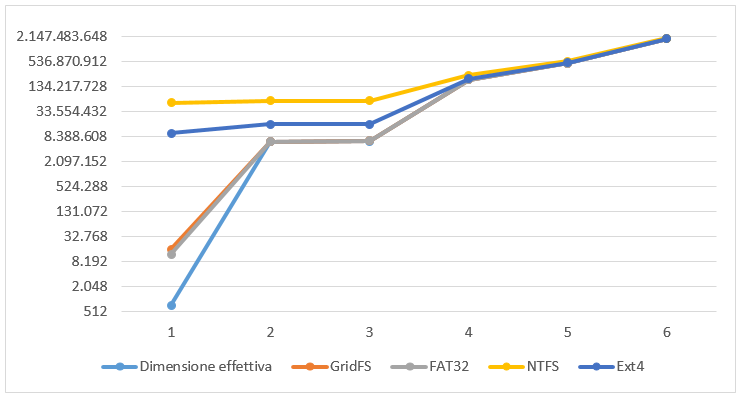
Figura 6 – Grafico in scala logaritmica (base 4) che confronta dimensioni reali e dimensioni su disco (in Byte) nei File System GridFS, FAT32, NTFS ed Ext4.
Figura 6 – Grafico in scala logaritmica (base 4) che confronta dimensioni reali e dimensioni su disco (in Byte) nei File System GridFS, FAT32, NTFS ed Ext4.
Attraverso lo sviluppo del software sono state comprese le potenzialità di MongoDB GridFS e in generale dei file system distribuiti.
L’unico limite di rilievo, ovvero l’assenza delle gerarchie fra directory, è stato superato con successo agendo semplicemente sulla denominazione dei bucket.
Il sistema nel complesso è reattivo durante il normale funzionamento. Quando un host PRIMARY viene disconnesso si evidenziano invece alcuni secondi nel quale è impossibile effettuare operazioni (ciò è dovuto al meccanismo di elezione del nuovo PRIMARY che risulta abbastanza lento).
Si propongono adesso alcune migliorie e nuove funzionalità da implementare nel software:
- Supporto allo Sharding;
- Supporto alle policy di sicurezza (login);
- Supporto ai link (potrebbero essere implementati utilizzando accorgimenti sui nomi dei bucket o dei file, analogamente a quanto fatto per gestire le gerarchie tra directory);
- Ricerca di file e directory;
- Funzionalità taglia, copia e incolla per file e directory;
- Upload e Download di intere directory;
- Utilizzo delle librerie grafiche JavaFX in sostituzione delle librerie AWT/Swing;
- Interfaccia a linea comando per una migliore integrazione con le utility dei sistemi operativi (la shell “mongo” risulta poco versatile per questi scopi).