NADI Shared Task 2020 for Arabic dialect classification site
Arabic has a widely varying collection of dialects. Many of these dialects remain under-studied due to the rarity of resources. The goal of the shared task is to alleviate this bottleneck in the context of fine-grained Arabic dialect identification. Dialect identification is the task of classifying the dialect of the tweet writer given the tweet itself.
We present our model for Arabic dialect classification that ranked fourth in WANLP 2020 leaderboard
By running the train.py file you are able to start the training process.
There are multiple params that can be changed in config_train.txt, a detailed explanation will be provided later on
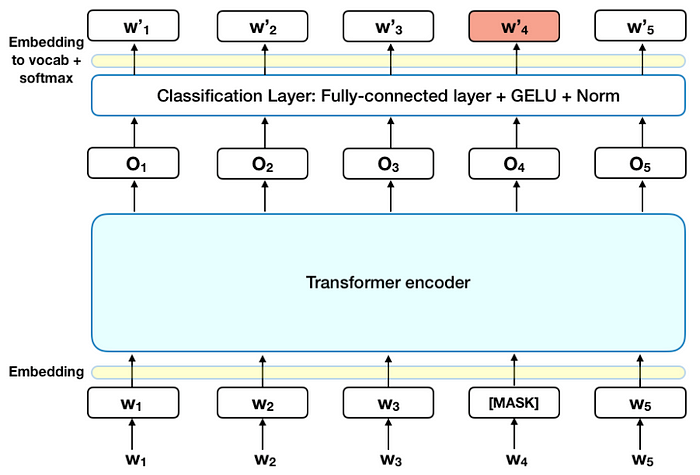
Using pre-trained AraBert, we first proceeded by fine-tuning the model applying masked language modeling on Arabic tweets as shown in the image below. This is also known as domain adaptation.
then we added a classification layer and retrained our fine-tuned model to distinguish different Arabic dialects.
hugging face repo
farasa seg rwdepo repo