Research on profiling of high-performance web applications (primarily WebGL applications).
In order to profile the performance of a web application one would usually use the browsers built-in developer tools. Every once in a while however there comes a time when a developer needs a better understanding of a performance issue in order to solve it. In order to get that understanding the developer needs access and an understanding of the low-level optimisations, de-optimisations and caching techniques in modern browser engines. Due to security restrictions in the browser it is only really possible to get this low-level information from browsers by enabling various flags when launching the browser locally.
Chrome and V8 ship with various built-in tools that help their developers during development of the browser and engine. Luckily we can, as a web developer, leverage these same tools to get a better understanding of what is happening under the hood.
To understand what parts of the application are useful to profile one must have a general understanding of the architecture of the compiler pipeline in modern browser engines like V8. The compiler pipelines behind each browser are similar but not at all the same on a technical level. By looking at the V8 pipeline in general terms we can understand what the core parts of a browser engine is without getting lost in the implementation details.
It is not necessary to understand the intrinsics of each browser engine but it is beneficial as a starting point in understanding what is harming the performance of your application.
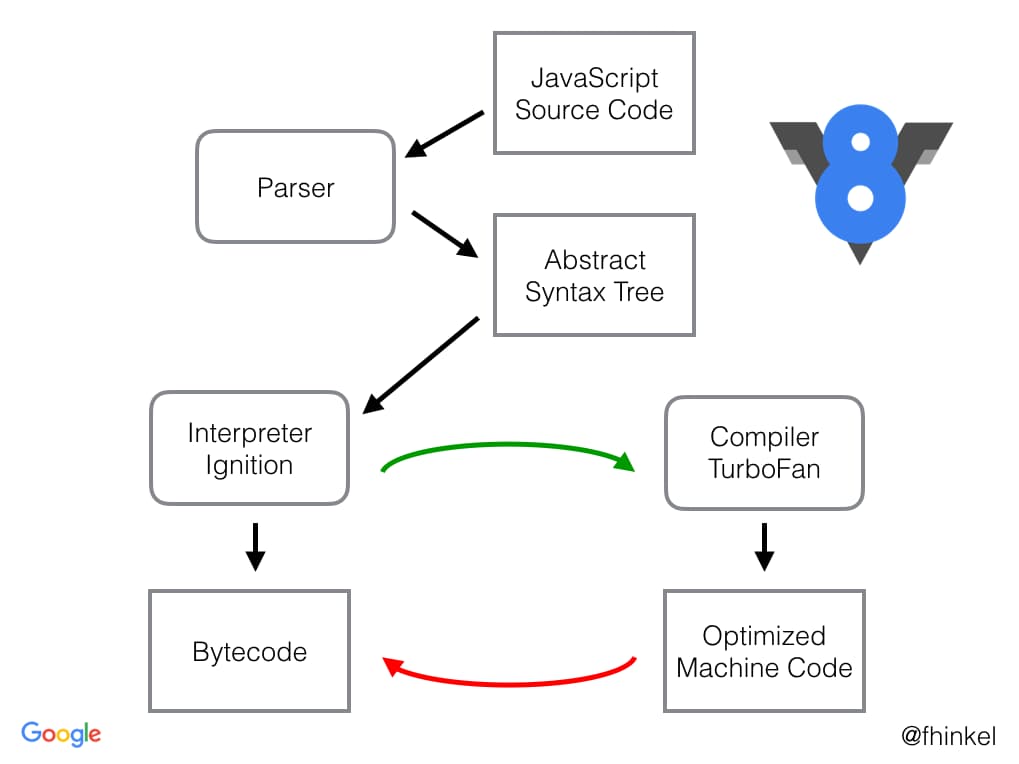
Image source: Franziska Hinkelmann - https://medium.com/dailyjs/understanding-v8s-bytecode-317d46c94775
JavaScript source code is JIT (Just In Time) compiled meaning it is being compiled to machine code as the program is running. Source code is initially just plain text with a mime-type that identifies it as JavaScript code. It must be parsed by a parser in order to be understood as JavaScript code by the browser engine.
The parser generally consists out of a pre-parser and a full-parser. The pre-parser rapidly checks for syntactical and early errors in the program and will throw if it finds any. The full-parser evaluates the scope of variables throughout the program and collects basic type information.
An Abstract Syntax Tree or in short AST is created from the parsed source code.
AST's are data structures widely used in compilers, due to their property of representing the structure of program code. An AST is usually the result of the syntax analysis phase of a compiler, a tree representation of the abstract syntactic structure of source code. Each node of the tree denotes a construct occurring in the source code. It is beneficial to get a good understanding of what AST's are as they are very oftenly used in pre-processors, code generators, minifiers, transpilers, linters and codemods.
The goal of the baseline compiler (Ignition in V8) is to rapidly generate relatively unoptimised machine code (CPU architecture specific bytecode in the case of Ignition) as fast as possible and infer general type information to be used in potential further compilation steps. Whilst running, functions that are called often are marked as hot and are a candidate for further optimisation using the optimising compiler(s).
The optimising compiler (Turbofan in V8) recompiles hot functions using previously collected type information to optimise the generated machine code further. However, in order to make a faster version of the machine code, the optimising compiler has to make some assumptions regarding the shape of the object, namely that they always have the same property names and order. Based on that the compiler can then make further optimisations. If the object shape has been the same throughout the lifetime of the program it is assumed that it will remain that way during future execution. Unfortunately in JavaScript there are no guarantees that this is actually the case meaning that object shapes can change at any stage over time. Due to this lack of guarantees the assumptions of the compiler need to be validated every single time before it runs. If it turns out the assumptions are false the optimising compiler assumes it made the wrong assumptions, trashes the last version of the optimised code and steps back to a de-optimised version where assumptions are still valid. It is therefore very important that you limit the amount of type changes of an object throughout the lifetime of the program in order to keep the highly optimised code produced by the optimising compiler alive. In the worst case scenario the object ends up in de-optimised hell and will never be picked up again to be optimised. Any code that V8 refuses to optimise can also end up in de-optimised hell.
Browser engines are continuously improving their optimisation techniques, especially around new browser features. Browser vendors generally recommend against implementing browser specific hacks to work around de-optimisations however there are specific keywords and patterns you should avoid using:
- Avoid using
eval,argumentsandwith. They cause what is known as aliasing preventing the browser engine from optimising them. - Avoid using arrays with many different types in them.
- Avoid swapping out values in an array with a value of another type.
- Avoid creating holes in arrays by deleting array entries or setting entries to
undefined. - Avoid using
for inas it will include properties that are inherited through the prototype chain. This behavior can lead to unexpected items in your loop and browsers likely deoptimise anything within them.
When profiling and optimising your JavaScript code part of your effort should go out to optimising the parts of the application that are being optimised by the optimising compiler, meaning that these functions are hot, and more importantly which parts of the application are being de-optimised. De-optimisation likely happens because types are changing in hot parts of the code or certain optimisations are not yet implemented by the compiler (such as try catch a few years ago, which has since been fixed). It is important to note that whilst you should pay attention when using these unoptimised implementations you should use them and report to the browser engines that you are using these features. If a certain de-optimisation shows up a lot in heuristics and performance bug reports it is likely to be picked up by the engine maintainers as a priority. Other things to take into account are optimising object property access, maintaining object shapes and understand the power of inline caches (monomorphic, polymorphic, megamorphic). Inline caches are used to memorize information on where to find properties on objects to reduce the number of expensive lookups.
Besides the browser's built-in sampling profilers available in Chrome developer tools and the structural profiler available in chrome://tracing one can start the browser from the command line with flags to enable the tracing of various parts of the web application.
Please note that any traces recorded with the tool will contains all currently opened resources (tabs, extensions, subresources) with the browser. Make sure that Chrome starts without any other resources (other tabs, extensions, profile) active in order to be able to get a relatively clean trace. In order to record a clean trace you should keep the recording to a maximum of 10 seconds, focus on a single activity per recording and leave the computer completely idle for 2 seconds before and after each recording. This will help making the slow process stand out amongst the other recorded data.
The essential point of garbage collection is the ability to manage memory usage by an application. All management of the memory is done by the browser engine, no API is exposed to web developers to control it explicitly. Web developers can however learn how to structure their programs in order to use the garbage collector to their advantage and avoid the generation of garbage.
All variables in a program are part of the object graph and object variables can reference other variables. Allocating variables is done from the young memory pool and is very cheap until the memory pool runs out of memory. Whenever that happens a garbage collection is forced which causes higher latency, dropped frames and thus a major impact on the user experience.
All variables that cannot be reached from the root node are considered as garbage. The job of the garbage collector is to mark-and-sweep or in other words: go through objects that are allocated in memory and determine whether they are dead or alive. If an object is unreachable it is removed from memory and previously allocated memory gets released back to the heap. Generally, e.g. in V8, the object heap is segmented into two parts: the young generation and the old generation. The young generation consists of new space in which new objects are allocated. It allocates fast, frequently collects and collects fast. The old space stores objects that survived enough garbage collector cycles to be promoted to the old generation. It allocates fast, infrequently collects and does slower collection.
The cost of the garbage collection is proportional to the number of live objects. This is due to a copying mechanism that copies over objects that are still alive into a new space. Most of the time newly allocated objects do not survive long enough in order to become old. It is important to understand that each allocation moves you closer to a garbage collection and every collection pauses the execution of your application. It is therefore important in performance critical applications to strive for a static amount of alive objects and prevent allocating new ones whilst running.
In order to limit the amount of objects that have to be garbage collected a developer should take the following aspects into account:
- Avoid allocating new objects or change types of outer scoped (or even global) variables inside of a
hotfunction. - Avoid circular references. A circular reference is formed when two objects reference each other. Memory leaks can occur when the engine and garbage collector fail to identify a circular reference meaning that neither object will ever be destroyed and memory will keep growing over time.
- A possible solution for the object allocation problem in the
young generationis the use of anobject poolthat basically pre-allocates a fixed number of objects ahead of time and keeps them alive by recycling them. This is a relatively common technique that allows you to have more explicit control over your objects lifetime. This however does come with an upfront cost when initializing and filling the pool and a consistent chunk of memory throughout your applications lifetime. An example of an object pool implementation can be found here. - Make use of WeakMaps where possible as they hold "weak" references to key objects, which means that they do not prevent garbage collection in case there would be no other reference to the key object.
- Avoid associating the
deletekeyword in JavaScript with manual memory management. Thedeletekeyword is used to remove properties from objects, not objects or variables as a whole, and is therefore not useful to mark objects ready to be garbage collected. - When profiling make sure to run it in an incognito window in a fresh browser instance without any browser extensions as they share the same heap as the JavaScript program that you are trying to profile.
In the Chrome developer tools panel, in the memory tab, you can find the option to take a heap snapshot which shows the memory distribution among your application's JavaScript objects and related DOM nodes. It is important to note that right before you click the heap snapshot button a major garbage collection is done. Because of this you can assume that everything that V8 assumes to be able to garbage collected has already been cleaned up allowing you to get an idea of what V8 was unable to clean up at the time.

Image source: Google Developers - https://developers.google.com/web/tools/chrome-devtools/memory-problems/
Once you have taken your snapshot you can start inspecting it.
You should ignore everything in parentheses and everything that is dimmed in the heap snapshot. These are various constructors that you do not have explicit control over in your application (such as native methods and global browser methods). The snapshot is ordered by the constructor name and you can filter the heap to find your constructor using the class filter up top. If you record multiple snapshots it is beneficial to compare them to each other. You can do this by opening the dropdown menu left of the class filter and set it to comparison. You can now see the difference between two snapshots. The list will be much shorter and you can see more easily what has changed in memory.

Image source: Google Developers - https://developers.google.com/web/tools/chrome-devtools/memory-problems/
Objects in the heap snapshot with a yellow background are an indicator that there is no active event handle available meaning that these objects will be difficult to clean up as you have probably lost its reference to it. Most likely it is still in the DOM tree but you have lost your JavaScript reference.
Objects with a red background in the heap snapshot are considered objects that have been detached from the DOM tree but their JavaScript reference is being retained. A DOM node can only be garbage collected when there are no references to it from either the page's DOM tree or JavaScript code. A node is said to be detached when it's removed from the DOM tree but some JavaScript still references it. Detached DOM nodes are a common cause of memory leaks. They are only alive because they are part of a yellow node's tree.
In general, you want to focus on the yellow nodes in the heap snapshot. Fix your code so that the yellow node isn't alive for longer than it needs to be, that way you also get rid of the red nodes that are part of the yellow node's tree.
For more information there are excellent entries on the Chrome developer tools blog on memory profiling:
A recommended technique for capturing and analyzing snapshots is to make three captures and do comparisons between them as shown in the following graphic:
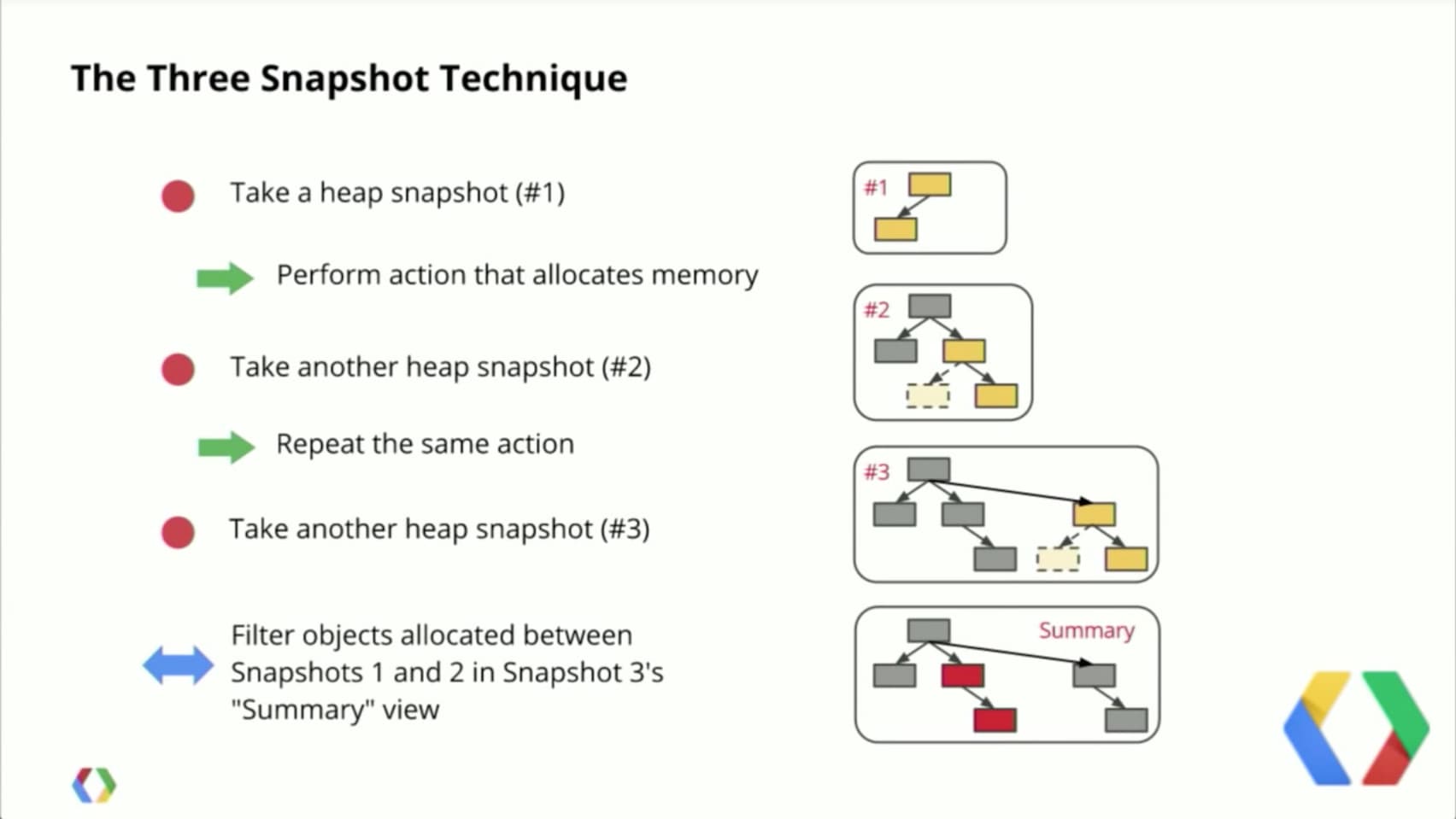
Image source: Google Developers Live - https://www.youtube.com/watch?v=L3ugr9BJqIs
In order to know if you are CPU bound you must profile the CPU. Most of the time it makes sense to keep an eye on real-time CPU usage and only when in doubt capture a CPU trace.
In Chrome there is a useful live CPU usage and runtime performance visualizer available in the performance monitor tab.

More advanced captures over period of time can be done using the performance capture feature available in the performance tab in Chrome. A good tutorial for understanding the runtime performance trace can be found here.

If you are CPU bound when rendering it is likely because of too many draw calls. This is a common problem and the solution is often to combine draw calls to reduce the cost.
There is however a lot more going on than just draw calls. The renderer needs to process and update each object (culling, material, lighting, collision) on every frame tick. The more complex your materials (math, textures) the higher the cost at creation time and the more expensive it is to run at runtime. In WebGL there is a small but significant overhead due to strict validation of the shader code. The underlying graphics driver validates the commands further and creates a command buffer for the hardware. In a browser a lot more is going on than just the WebGL rendering context.
In order to reduce the mesh draw calls one can use the following techniques:
- Combine meshes into a single mesh to reduce the amount of necessary draw calls.
- Reduce the object count (e.g. static meshes, dynamic meshes and mesh particles).
- Reduce the far view distance on your camera's.
- Adjust the field of view of your camera's to be smaller in order to have less objects in the view frustum.
- Reduce the amount of elements per draw call (e.g. combine textures into texture atlases, use LOD models).
- Disable features on a mesh like custom depth, shadow casting and shadow receiving.
- Change light sources to not shadow cast or have a tighter bounding volume (view cone, attenuation radius).
- Use hardware instancing where possible as it reduces the driver overhead per draw call (e.g. mesh particles).
- Reduce the depth of your scene graph.
If you are CPU bound by other parts of your application there is likely some other issue in your codebase.
In order to know if you are GPU bound you must profile the GPU. Most of the time it makes sense to keep an eye on real-time GPU timing queries and when in doubt capture a GPU trace.
The GPU has many processing units working in parallel and it is common to be bound by different units for different parts of the frame. Because of this, it makes sense to look at finding where the GPU cost is going when looking for the GPU bottleneck. Common ways your can be GPU bound are the application being draw call heavy, complex materials, dense triangle meshes and a large view frustum).
In order to know if you are pixel bound one can try varying the viewport resolution. If you see a measurable performance change it likely means that you are bound by something pixel related. Usually it is either texture memory bandwidth (reading and writing) bound or math bound (ALU), but in rare cases, some specific units are saturated (e.g. MRT). If you can lower the memory, or math, on the relevant passes and see a performance difference you know it was bound by the memory bandwidth (or the ALU units).
In general you should look at using the following optimisation techniques:
- Do as much as you can in the vertex shader rather than in the fragment shader because, per rendering pass, fragment shaders run many more times than vertex shaders, any calculation that can be done on the vertices and then just interpolated among fragments is a performance benefit (this interpolation is done "automagically" for you, through the fixed functionality rasterization phase of the WebGL pipeline).
- Reduce the amount of WebGL state changes by caching and mirroring the state on the JavaScript. By diffing the state in JavaScript you can drastically reduce the amount of expensive WebGL state changes.
- Avoid anything that requires synching the CPU and GPU as it is potentially very slow. Cache WebGL getter calls such as
getParameterandgetUniformLocationin JavaScript variables and only programmatically usesetParameterafter making sure you actually need to set the parameter by checking the mirrored WebGL state in JavaScript. - Cull any geometry that won't be visible (octree, BVH, kd-tree, quadtree) through occlusion culling, viewport culling or backface culling.
- Group mesh submissions with the same state in order to prevent unnecessary WebGL state switches.
- Limit the size of the canvas and do not directly use the device's pixel ratio but rather artificially limit it to a point where visual fidelity is acceptable yet performant.
- Turn off the native anti-aliasing option on the canvas element, instead anti-alias once during postprocessing using FXAA, SMAA or similar in the fragment shader. The native implementation is unreliable and very naive.
- Avoid using the native screen resolution retrieved using
window.devicePixelRatio()for your fullscreen canvas as some phones can have a very high density display. Some effects and scenes can often get away with rendering at a lower resolution. - Disable alpha blending and disable the preserving of the drawing buffer when creating the WebGL canvas.
If you are fragment shader bound you can look at the following optimisation techniques:
- Avoid having to resize textures to be a power of two during runtime. This is unnecessary in WebGL2 but it is still highly recommended to use power of two textures for a more efficient memory layout. NPOT textures may be handled noticeable slower and can cause black edging artifacts by mipmap interpolation.
- Avoid using too many uniforms, use
Uniform Buffer ObjectsandUniform Block's where possible (WebGL2). - Reduce the amount of stationary and dynamic lights in your scene. Pre-bake where possible.
- Try to combine lights that have a similar origin.
- Limit the attenuation radius and light cone angle to the minimum needed.
- Use an early Z-pass in order to determine what parts of the scene are actually visible. It allows you to avoid expensive shading operations on pixels that do not contribute to the final image.
- Limit the amount of post-processing steps.
- Disable shadow casting where possible, either per object or per light.
- Reduce the shadow map resolution.
- Make use of the multi-render target extension
WEBGL_draw_bufferswhen using deferred rendering. Be aware that this extension is not available everywhere whereWebGLis available. It fortunately is a part of theWebGL2core spec making it available everywhere where theWebGL2spec is implemented correctly. - Materials with fewer shader instructions and texture lookups run faster.
- Never disable mipmaps if the texture can be seen in a smaller scale to avoid slowdowns due to texture cache misses.
- Make use of GPU compressed textures and lower bitrate texture formats in order to reduce the in-memory GPU footprint.
Often the shadow map rendering is bound by the vertex shader, except if you have very large areas affected by shadows or use translucent materials. Shadow map rendering cost scales with the number of dynamic lights in the scene, number of shadow casting objects in the light frustum and the number of cascades. This is a very common bottleneck.
Highly tessellated meshes, where the wireframe appears as a solid color, can suffer from poor quad utilization. This is because GPUs process triangles in 2x2 pixel blocks and reject pixels outside of the triangle a bit later. This is needed for mip-map computations. For larger triangles, this is not a problem, but if triangles are small or very lengthy the performance can suffer as many pixels are processed but few actually contribute to the image.
If you are vertex shader bound you can look at the following optimisation techniques:
- Verify that the vertex count on your models in reasonable for real-time usage.
- Avoid using too many vertices (use LOD meshes).
- Verify your LOD is setup with aggressive transition ranges. A LOD should use vertex count by at least 2x. To optimise this, check the wireframe, solid colors indicate a problem.
- Avoid using complex world position offsets (morph targets, vertex displacement using textures with poor mip-mapping)
- Avoid tessellation if possible (if necessary be sure to limit the tessellation factor to a reasonable amount). Pretesselated meshes are usually faster.
- Very large meshes can be split up into multiple parts for better view culling.
- Avoid using too many vertex attributes, use
Vertex Array Objectswhere possible (almost always available in WebGL, always available in WebGL2). - Billboards, imposter meshes or skybox textures can be used to efficiently fake detailed geometry when a mesh is far in the distance.
In Chrome there are various ways to profile the GPU:
For tracing an individual WebGL frame in depth without setting up an external debugger I highly recommend using the Chrome extension Spector.js made by the Babylon team at Microsoft. It allows for exporting and importing stack traces generated by Spector, captures the full WebGL state at each step and allows for easy exploration of the vertex and fragment shader. On top of that the project is free, open source and maintained by a professional team instead of an individual.

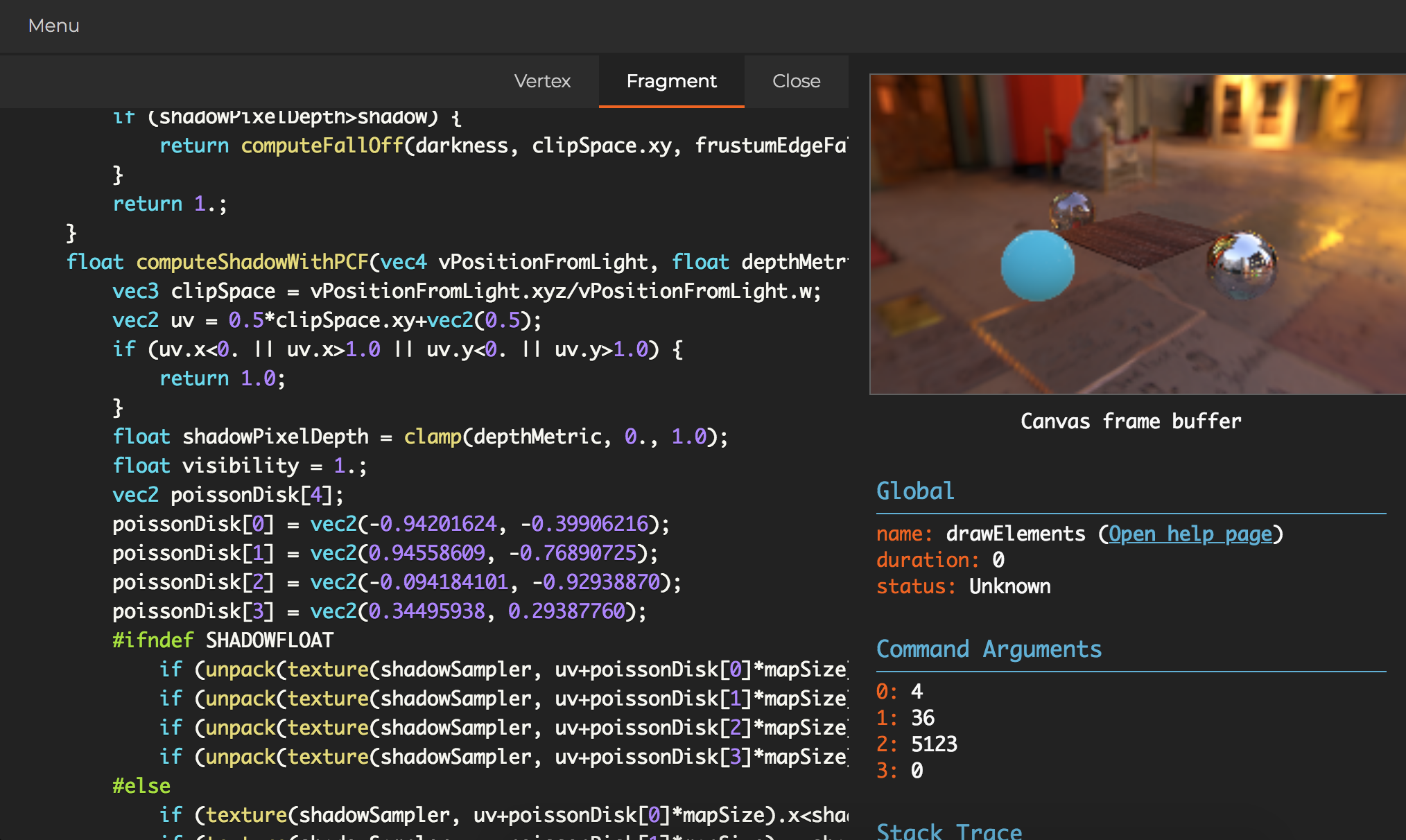
The main advantage of this approach is that it does not require the disabling of the GPU sandbox, like some external debuggers do, and avoids the need of having to install and learn a complex debugger. I would highly recommend this method over using an external debugger if you use Mac OS or if you are not familiar with an alternative external debugger like RenderDoc (Windows, Linux) or APITrace (Windows, Linux, Mac (limited support)). Instructions on how to debug WebGL using APITrace can be found here.
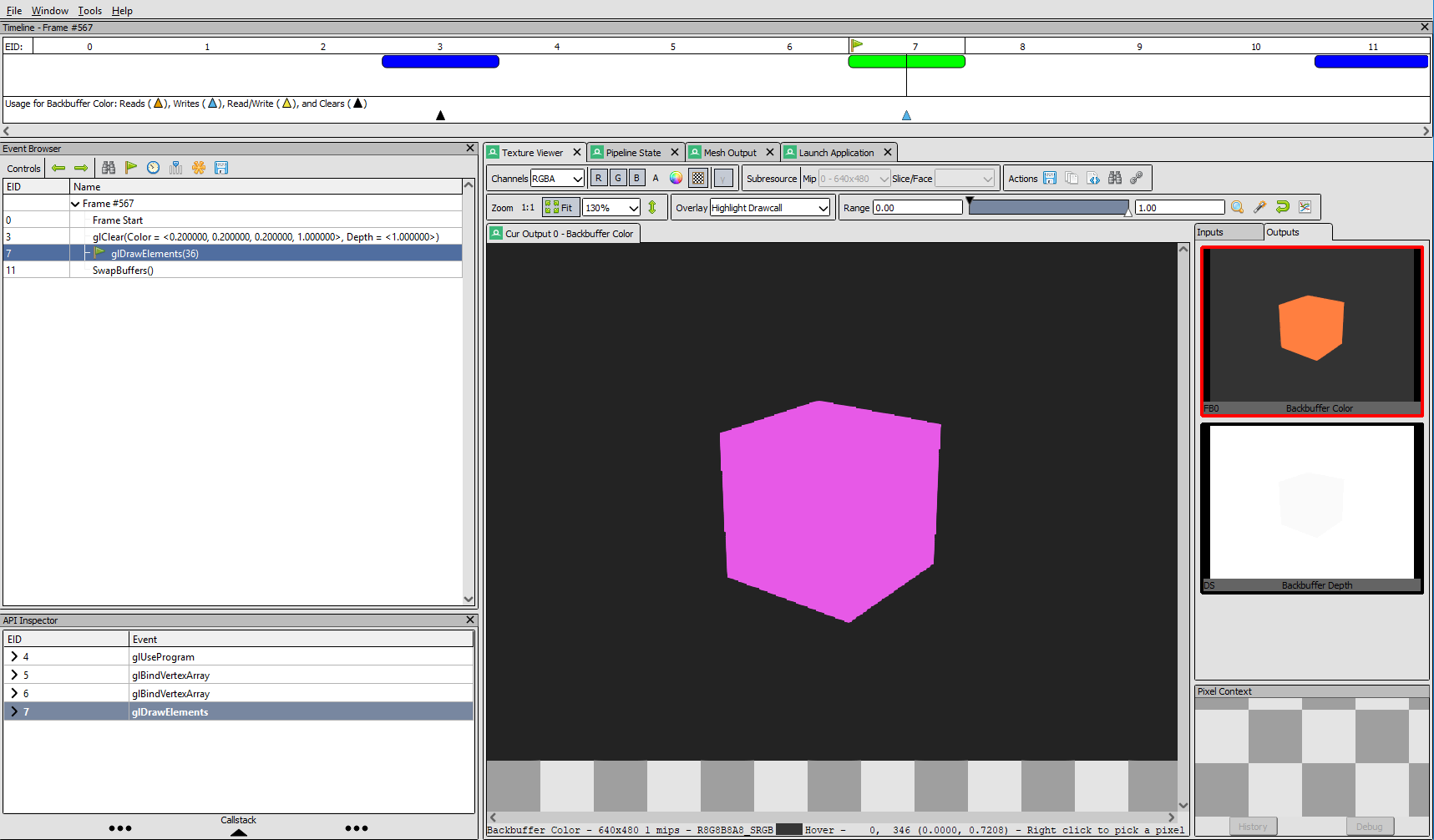
For capturing traces over time one can use the advanced tracing capabilities like MemoryInfra available in chrome://tracing.
A good example for how to understand and work with the captures of it can be found here.
For capturing GPU traces using chrome://tracing I recommend using the rendering preset.


There are also various ways you can integrate profiling into your application.
One can use the WebGL extension EXT_disjoint_timer_query to measure the duration of OpenGL commands submitted to the graphics processor without stalling the rendering pipeline. It makes most sense if this extension is integrated into the WebGL engine that you are using. A good example of a WebGL framework with an integrated profiler is Luma.gl.
One can also wrap the WebGLRenderingContext with a debugging wrapper like the one provided by the Khronos Group to catch invalid WebGL operations and give the errors a bit more context. This comes with a large overhead as every single instruction is traced (and optionally logged to the console so make sure to only optionally include the dependency in development. I have rarely found this method to be useful as it does not capture a single frame clearly and logs everything with the same priority to the console.
To automatically download and setup Chrome Canary on Mac OS using Homebrew you can use:
$ ./scripts/setup_macos.shIn order to install V8 and the D8 shell I recommend following the excellent guide by Kevin Cennis.
In order to be able to properly profile your application the browsers needs to expose more of its internals than usual. One can do this by launching the browser with a set of command line flags.
Included in this repo one can find a script that launches the latest version of Chrome Canary with a temporary user profile in an incognito window without any extensions installed.
Chrome has VSync disabled for unlocked framerates (useful for knowing how much of your frame budget you still have left), more precise memory tracking (necessary for properly tracing your memory usage), remote port debugging, optimisation tracing and de-optimisation tracing (both logged to files).
It is currently only configured for MacOS but I welcome PR's to add support for Windows and Linux.
You can launch the script as follows:
$ ./scripts/run_macos.sh <URL>- Optimising WebGL Applications with Don Olmstead
- CPU profiling in Unreal Engine
- GPU profiling in Unreal Engine
- Performance Guidelines for Artists and Designers
- The Breakpoint Ep. 8: Memory Profiling with Chrome DevTools
- V8 Garbage Collector
- Google I/O 2013 - Accelerating Oz with V8: Follow the Yellow Brick Road to JavaScript Performance
- Franziska Hinkelmann - Performance Profiling for V8 / Script17 (Slides)
- Franziska Hinkelmann - Performance Profiling for V8 / Script17 (Video)
- Franziska Hinkelmann - Performance Profiling for V8 / Script17 (Files)
- V8 profile documentation
- V8 performance notes and resources
- Turbolizer
- The Trace Event Profiling Tool (chrome://tracing)
- Ignition - an interpreter for V8
- A crash course in Just In Time (JIT) compilers
- JavaScript engine fundamentals: Shapes and Inline Caches
- JavaScript Engines: The Good Parts™ - Mathias Bynens & Benedikt Meurer - JSConf EU 2018
- Understanding V8’s Bytecode
- Visualize JavaScript AST's
- Garbage collection in V8, an illustrated guide
- Bailout reasons in V8 (Crankshaft)
- Bailout reasons in V8 (Turbofan)
- Scott Meyers: Cpu Caches and Why You Care