Architecture
Disclaimer: the following code walk-throughs are informal, with live Q&A and assume familiarity with the fundamentals of Tiledb Core as presented in Tiledb Embedded documentation: https://docs.tiledb.com/main/
In these walk-throughs, we discuss the high level flow of the sparse reader when unordered results are requested and duplicates are allowed. This is a very widespread use-case and can be very performant.
Recording no1: https://drive.google.com/file/d/1XU52DMR7s82DwNcFRzIT9bKYHWIs_vGf
Recording no2: https://drive.google.com/file/d/1SxEKyi4u10Ftdr_w0APII8yj1Yvg1U2h
https://drive.google.com/file/d/17I-zKvf8tQUWT1jWv0QTHhIBnbU0SpPj

This is a broad but non-exhaustive ownership graph of the major classes within the TileDB core.
Array: An in-memory representation of a single on-disk TileDB array.
ArraySchema: Defines an array.
Attribute: Defines a single attribute.
Domain: Defines the array domain.
Dimension: Defines a dimension within the array domain.
FragmentMetadata: An in-memory representation of a single on-disk fragment's metadata.
RTree: Contains minimum bounding rectangles (MBRs) for a single fragment.
Context: A session state.
StorageManager: Facilitates all access between the user and the on-disk files.
VFS: The virtual filesystem interface that abstracts IO from the configured backend/filesystem.
Posix: IO interface to a POSIX-compliant filesystem.
Win: IO interface to a Windows filesystem.
S3: IO interface to an S3 bucket.
Azure: IO interface to an Azure Storage Blob.
GCS: IO interface to a Google Cloud Storage Bucket.
Consolidator: Implements the consolidation operations for fragment data, fragment metadata, and array metadata.
Query: Defines and provides state for a single IO query.
Reader: IO state for a read-query.
SubarrayPartioner: Slices a single subarray into smaller subarrays.
Subarray: Defines the bounds of an IO operation within an array.
FilterPipeline: Transforms data between memory and disk during an IO operation, depending on the defined filters within the schema.
Tile: An in-memory representation of an on-disk data tile.
ChunkedBuffer: Organizes tile data into chunks.
Write: IO state for a write-query.

The lowest-level public interface into the TileDB library is through the C API. All other APIs wrap the C API, including the C++ API.
C API: https://github.com/TileDB-Inc/TileDB/tree/dev/tiledb/sm/c_api
C++ API: https://github.com/TileDB-Inc/TileDB/tree/dev/tiledb/sm/cpp_api
Python API: https://github.com/TileDB-Inc/TileDB-Py
R API: https://github.com/TileDB-Inc/TileDB-R
Go API: https://github.com/TileDB-Inc/TileDB-Go
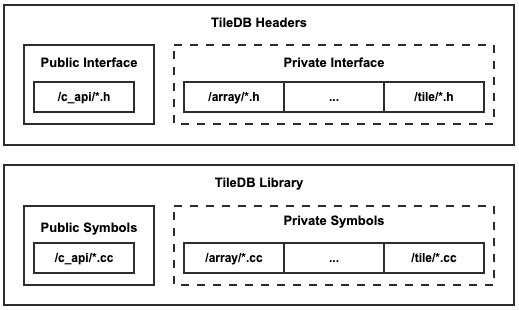
The C API is located in the core repository within the tiledb/sm/c_api directory. When TileDB is built, symbols from the C API implementation have public visibility. All other symbols built in the source, i.e. tiledb/sm/*.cc, have hidden visibility (except for the tiledb/sm/cpp_api/*.cc, more on that later). When TileDB is installed, the C API header files are packaged. All other headers in the source, i.e. tiledb/sm/*.h, are not packaged (except, again, the CPP API headers).

The C API operates on instances of publicly defined structs (currently defined within tiledb/sm/c_api/tiledb_struct_def.h). Most of these struct definitions are simple wrappers around an instance of a private C++ class. The wrapped C++ classes are inaccessible to the end-user because the symbols are hidden. The end-user must operate on objects using the C functions defined in the installed headers.
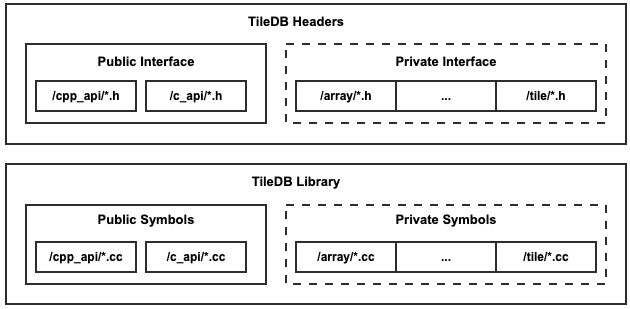
Similar to the C API, the C++ API symbols are exported in the TileDB library. The C++ API headers are also installed.

Although the C++ API implementation has access to the hidden core source like the C API does, it does not directly access it. By convention, the entire C++ API implementation is implemented with the C API. Note that the C++ API interface exists in the tiledb namespace while the hidden, core source exists in the tiledb::sm namespace.

The current on-disk format spec can be found here:
https://github.com/TileDB-Inc/TileDB/blob/dev/format_spec/FORMAT_SPEC.md.
The Array class provides an in-memory representation of a single TileDB array. The ArraySchema class stores the contents of the __array_schema.tdb file. The Domain, Dimension, and Attribute classes represent the sections of the array schema that they are named for. The Metadata class represents the __meta directory and nested files. The FragmentMetadata represents a single __fragment_metadata.tdb file, one per fragment. Tile data (e.g. attr.tdb and attr_var.tdb) is stored within instances of Tile.

The StorageManager class mediates all I/O between the user and the array. This includes both query I/O and array management (creating, opening, closing, and locking). Additionally, it provides state the persists between queries (such as caches and thread pools).
The tile cache is an LRU cache that stores filtered (e.g. compressed) attribute and dimension data. Is it used during a read query. The VFS maintains a read-ahead cache and backend-specific state (for example, an authenticated session to S3/Azure/GCS).
The compute and I/O thread pools are available for use anywhere in the core. The compute thread pool should be used for compute-bound tasks while the I/O thread pool should be used for I/O-bound tasks (such as reading from disk or an S3/Azure/GCS client).
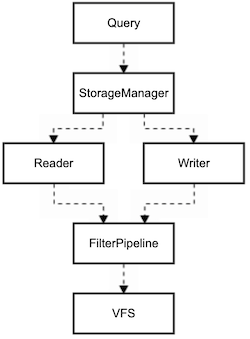
The above is a high-level flow diagram depicting the path of user I/O:
- A user constructs a
Queryobject that defines the type of I/O (read or write) and the subarray to operate on. - The
Queryobject is submitted to theStorageManager. - The
StorageManagerinvokes either aReaderorWriter, depending on the I/O type. - The
FilterPipelineis unfilters data for reads and filters data for writes. - The
VFSperforms the I/O to the configured backend.
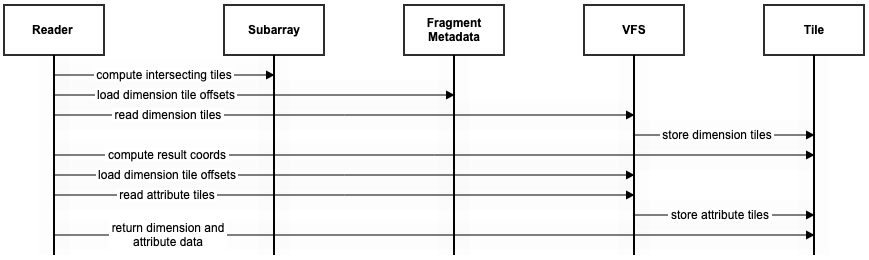
At a high-level, the read path:
- Finds all tiles that intersect the query.
- Reads the coordinate data from dimension tiles.
- Computes the coordinates that intersect the query.
- Reads the attribute data from the attribute tiles.
- Copies intersecting attribute data and their associated coordinates back to the user.
Note that sparse reads rely on using the R-Tree of MBRs to compute tile overlap while dense reads do not. Also note that returning coordinate data to the user is optional for a dense read.

TileDB reads directly user-provided buffers. It is possible that the entire read is too large for the user-provided buffers. When a user submits a query, it is their responsibility to check the query state. If the query is incomplete, the read was successful but could only store a portion of the entire read in their buffers. The user should process the results, and retry the query. The query's internal state will read the next portion of the read that can fit into the buffers.
Internally, when the Reader detects that a read of a given subarray range would overflow the user-provided buffers, it uses an instance of the SubarrayPartitioner class to partition the ranges into smaller subranges. The motivation is that subranges may be small enough to fit into the user-provided buffers. This loops until the ranges are sufficiently partitioned.
TODO
The VFS (virtual filesystem) provides a filesystem-like interface file management and IO. It abstracts one of the six currently-available "backends" (sometimes referred to as "filesystems"). The available backends are: POSIX, Windows, AWS S3, Azure Blob Storage, Google Cloud Storage, and Hadoop Distributed File System.

The read path serves two primary functions:
- Large reads are split into smaller batched reads.
- Modifies small read requests to read-ahead more bytes than requested. After the read, the excess bytes are cached in-memory. Read-ahead buffers are cached by URI in an LRU policy. Note that attribute and dimension tiles are bypassed, because that data is cached in the Storage Manager's tile cache.
If reads are serviceable through the read-ahead cache, no request will be made to the backend.

The write path directly passes the write request to the backend, deferring parallelization, write caching, and write flushing.
TODO
TODO
TODO
TODO
TODO
TODO
TODO
TODO