
This dataset consists of 122,726 high-quality 1024x1024 curated face images. It was created by generating random prompt strings that were sent to multiple "text to image" models (Flux1.pro, Flux1.dev, Flux1.schnell, SDXL, DALL-E 3) and curating the results using a semi-manual process.
The prompts describe various faces with different attributes and conditions to ensure extreme variance and diversity in ethnicities, poses, accessories, jewelry, hairstyles and hair colors, expressions, backgrounds, lighting, and more. Due to our ability to control each of these attributes independently via the text prompt, this dataset exhibits a previously unprecedented degree of variance and diversity among publicly available face datasets along most facial attributes. Additionally, it is free of privacy concerns and licensing issues because all images are synthetically generated.
The SFHQ-T2I dataset features high-quality images, surpassing those of the SFHQ dataset, with most being photorealistic and of high resolution. The dataset is paired with the prompts used to generate each image, allowing for a wide range of applications in text-to-image synthesis, face analysis, and other machine learning tasks.

The dataset can be downloaded from Kaggle via the link: SFHQ-T2I dataset on kaggle
create_face_dataset.py: Script to generate the dataset using various text-to-image APIs (fal, openai, stability)explore_dataset.py: Script for basic exploratory data analysis of the datasetextract_pretrained_features.py: Utility to extract features from pretrained OpenCLIP models for the dataset imagesface_prompt_utils.py: Utilities for automatically generating diverse face promptsmerge_dataset_folder.py: Script to merge multiple dataset foldersfigures/: Folder containing various visualizations of the dataset
- 122,726 high quality 1024x1024 face images
- Paired (text, image) dataset
- Generated using multiple text-to-image models via randomly generated prompts:
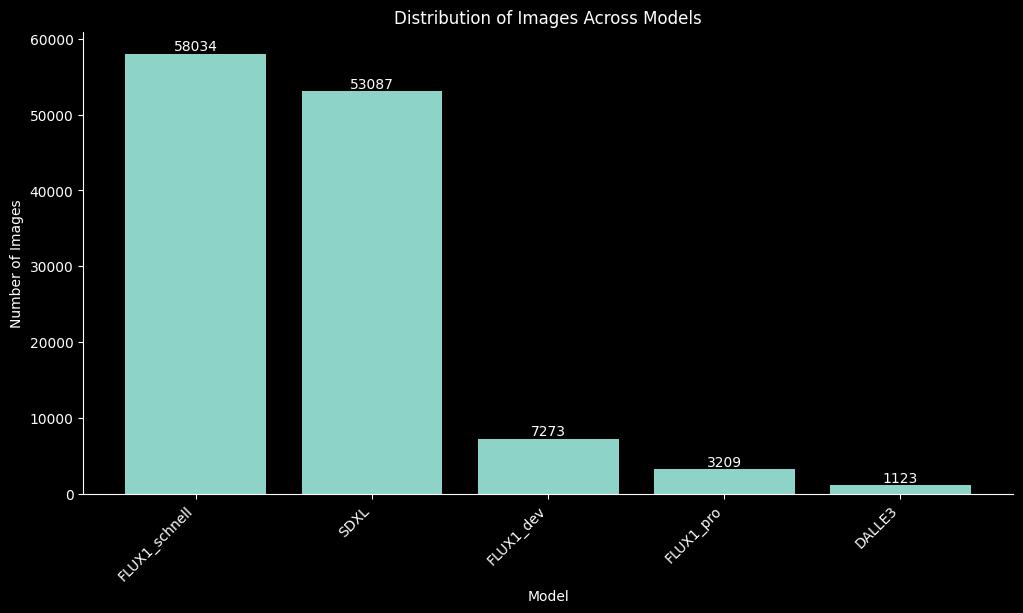
- Flux1.pro (3,209 images)
- Flux1.dev (7,273 images)
- Flux1.schnell (58,034 images)
- SDXL (53,087 images)
- DALL-E 3 (1,123 images)
- Unprecedented variability in various face attributes such as accessories, ethnicity and age, expressions, and more
- CSV file (
SFHQ_T2I_dataset.csv) containing details about each image:- Prompt used to generate the image
- Model used
- Random seed, number of steps and other configuration details specific to each model
The following figures were created by performing textual searches on the dataset using CLIP features
-
accessories:

-
hair color:

-
lighting:

-
expression:
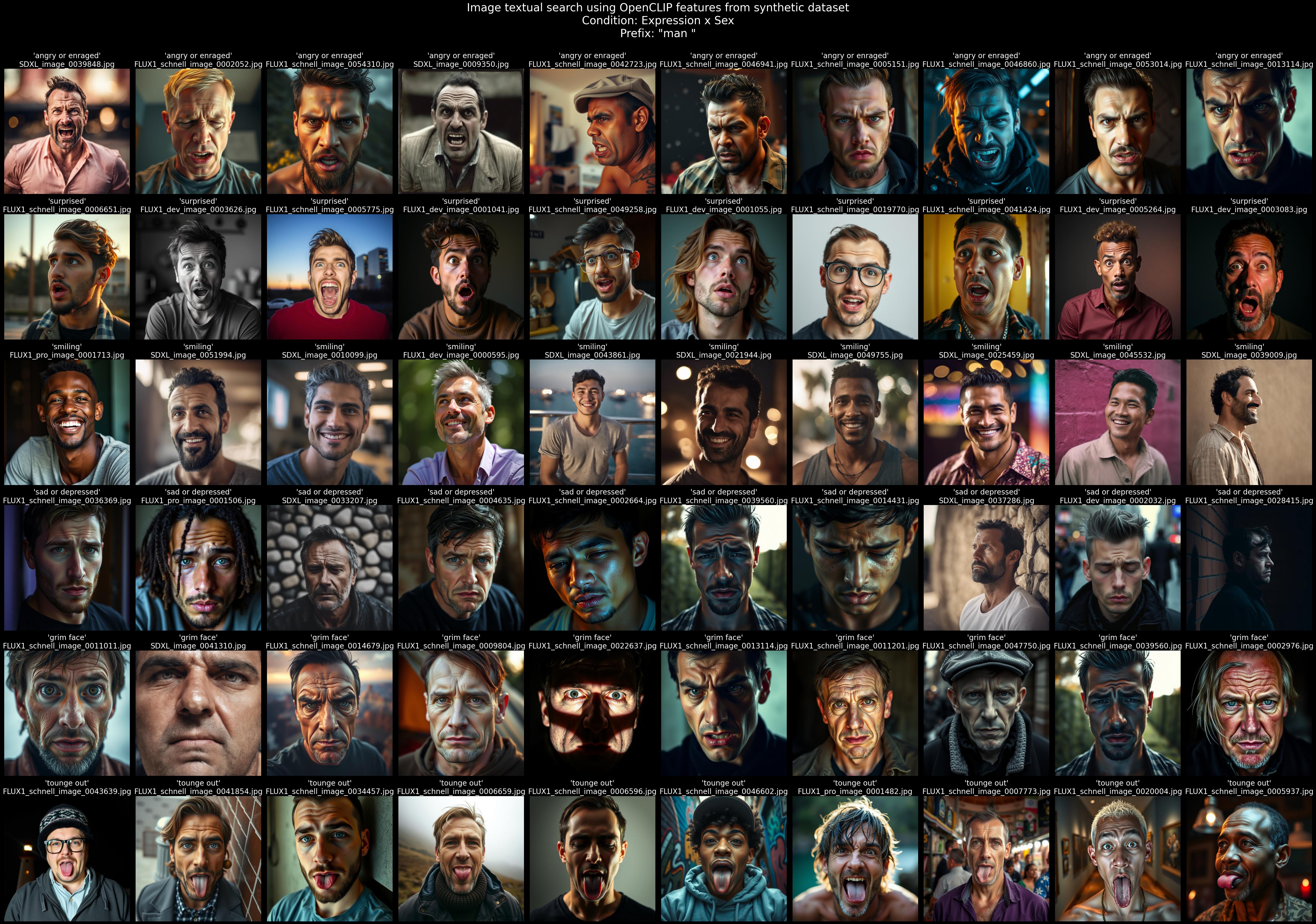
-
age:
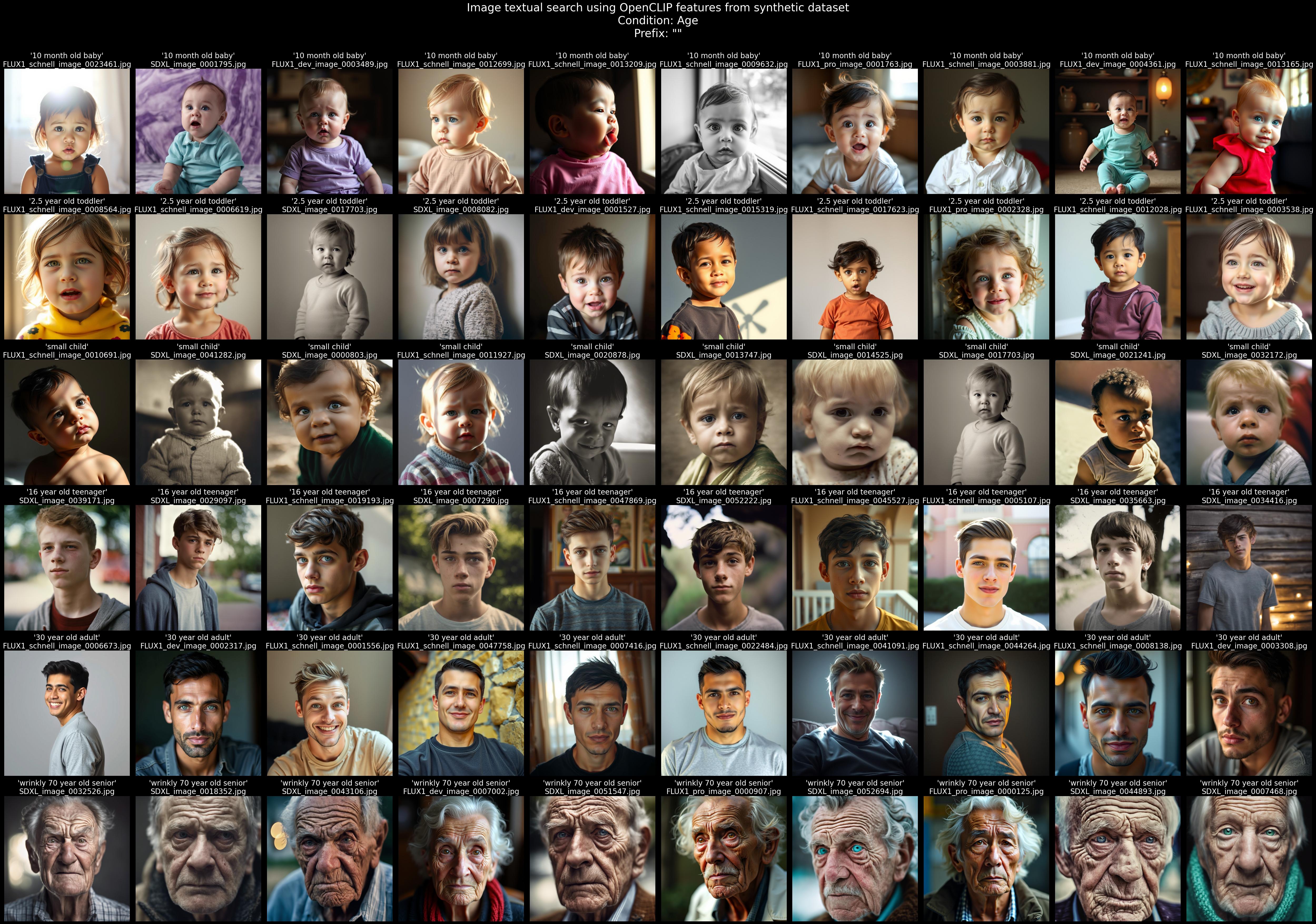
Additional examples of various textual searchers can be found in the figures/ folder.
The dalle images are very bad, this is possibly done on purpose from openai point of view to avoid scandals related to face images. Also, the openai api is changing the prompt you request to its own prompts without the ability to cancel this edit, so we lack even basic control. Therefore, I strongly suggest not to use it. I initially planned to generate much more images from the Dalle-3 model due to its prompt adherence, but there appears to be a specific issue with face images. It is also more expensive than the other options like the Flux models and the results are not as good.
Both Flux1.pro and Flux1.dev are very very good. SDXL and schnell are also good and way cheaper, but they are not as good as the pro and dev models. SDXL has its own unique style, especially in its textures, but its global image structure is sometimes flawed. Schnell is similar to the pro and dev models at the global structure of the image, but it is not as sharp and the textures are not always photorealistic. A small fraction of the generated images appear like 3D models and paintings. I've kept them in the dataset despite not being the main focus of the dataset, because the main goal is increasing entropy.
An example script demonstrating how to access and explore the data can be found in the explore_dataset.py file. This script shows how to load the dataset, visualize the distribution of images across models, plot prompt length distributions, and perform textual searches on the dataset using CLIP features.
The code to generate the random prompts can be found in face_prompt_utils.py. This script creates highly diverse prompts by combining various facial attributes, expressions, accessories, and environmental factors.
You can adjust the following parameters in the __main__ part of the create_face_dataset.py script:
output_db_folder: The directory where images and metadata will be savedsdxl_samples,dalle3_samples,flux1_pro_samples, ...: Number of images to generate for each modelsdxl_config,dalle3_config,flux1_pro_config, ...: Configuration parameters for each model
-
Ensure you have the appropriate API keys set up in the script as described above and set up the number of samples to generate for each model.
-
Run the script:
python create_face_dataset.pyThe script will create a
.envfile with your API keys on the first run. It will then generate images using all three models and save them in the specified output folder along with a metadata CSV file. -
The script generates:
Images in the{output_db_folder}/imagesdirectory
ASFHQ_T2I_dataset.csvfile in theoutput_db_foldercontaining information about each generated image
You'll need API keys for Stability AI, OpenAI, and FAL AI. Here's how to obtain them:
-
FAL AI (for FLUX1.pro):
- Sign up at https://www.fal.ai/
- Generate an API key from your account dashboard
-
Stability AI (for SDXL):
- Sign up at https://platform.stability.ai/
- Navigate to your account dashboard and generate an API key
-
OpenAI (for DALL-E 3):
- Sign up at https://platform.openai.com/
- Go to the API section and create a new API key
-
Install the required packages:
pip install stability-sdk openai fal-client pillow pandas python-dotenv
Once you have your API keys, update the following lines at the beginning of the create_face_dataset.py script with your actual keys:
STABILITY_API_KEY = 'your-stability-ai-api-key'
OPENAI_API_KEY = 'your-openai-api-key'
FAL_API_KEY = 'your-fal-api-key'Since all images in this dataset are synthetically generated, there are no privacy issues or license issues surrounding these images.
If you use this dataset in your research, please cite it as follows:
@misc{david_beniaguev_2024_SFHQ_T2I,
title={Synthetic Faces High Quality - Text 2 Image (SFHQ-T2I) Dataset},
author={David Beniaguev},
year={2024},
url={https://github.com/SelfishGene/SFHQ-T2I-dataset},
publisher={GitHub},
DOI={10.34740/kaggle/dsv/9548853},
}
The SFHQ-T2I dataset provides a large, diverse collection of high-quality synthetic face images paired with their generating prompts. This dataset is unique in its level of variability across multiple facial and environmental attributes, made possible by the use of various state-of-the-art text-to-image models and carefully crafted prompts.
The purpose of this dataset is to provide a rich resource for training and evaluating machine learning models in tasks related to face analysis, generation, and text-to-image synthesis, without the need to worry about privacy or license issues. The dataset may be extended from time to time with additional labels or features, but no promises.
I hope this dataset proves useful. Feel free to use it as you see fit...