Remove Redundant Functions + 60% MD Speedup #98
Conversation
|
/run standalone |
| float miniDeltaLooseTilted[3] = {0.4f, 0.4f, 0.4f}; | ||
| float miniDeltaEndcap[5][15]; | ||
|
|
||
| for (size_t i = 0; i < 5; i++) { |
There was a problem hiding this comment.
This matrix creation code was being run many times, representing a significant portion of the MD creation time it seems like.
|
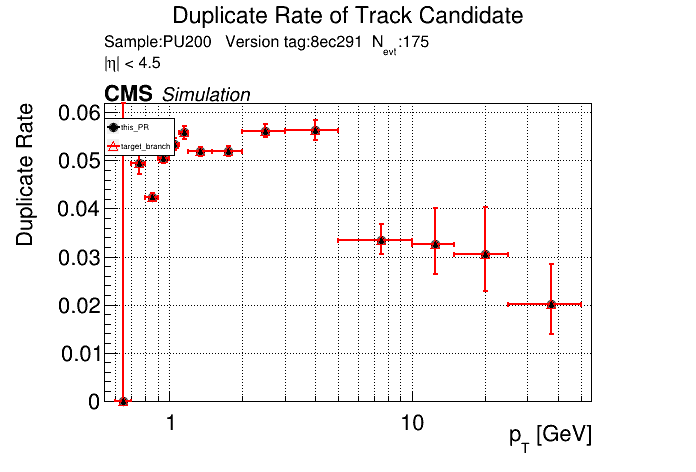
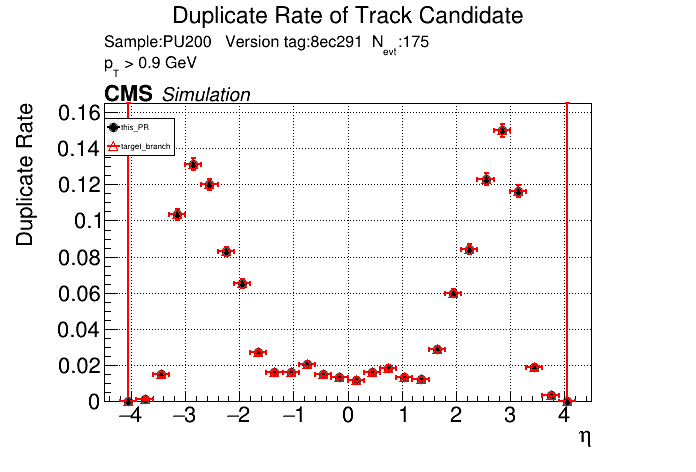
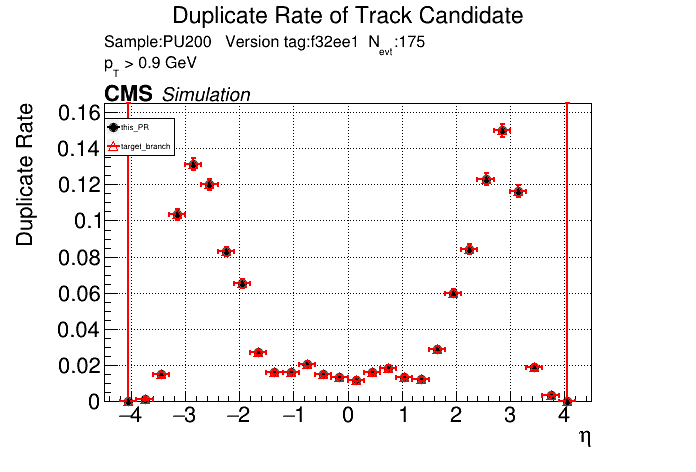
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
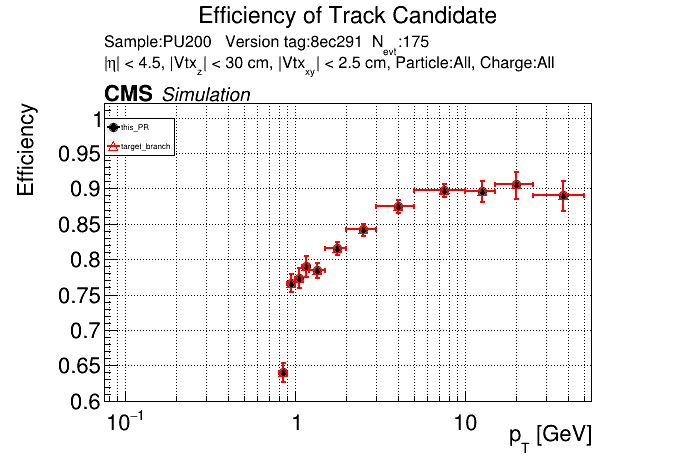
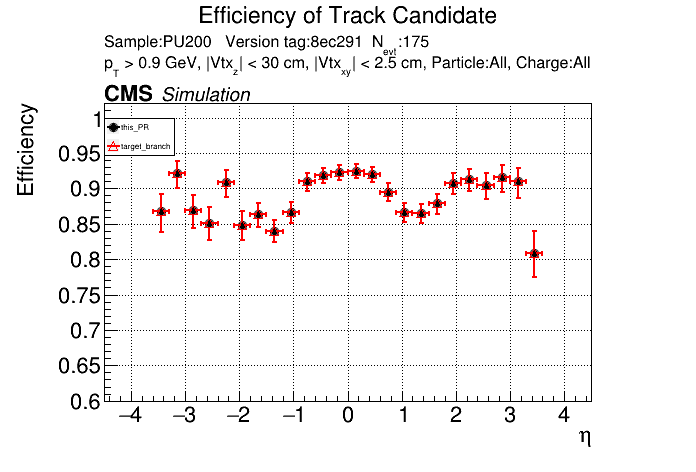
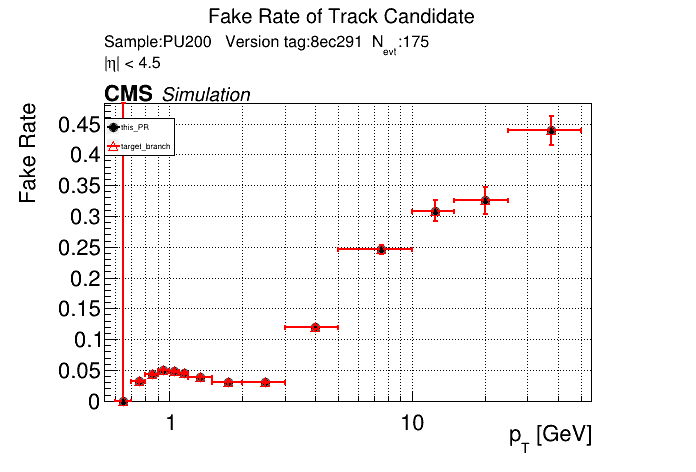
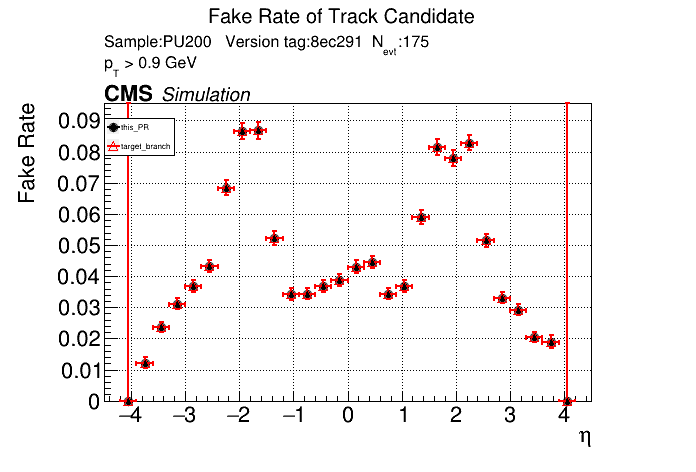
nice find/fix. |
|
apparently this is addressing SegmentLinking/TrackLooper#303 |
|
Indeed, nice catch and clean up. I would even considering adding this to the CMSSW PR (especially if the renaming to adhere to CMSSW naming is real and not an artefact of the rebases). What do you think? @ariostas Is the |
|
The I think there's other PRs by Gavin that should also be included in |
I would be less eager to also push these ones, because:
So I think they would be great for a standalone PR. |
That's true. But Andrea has asked for occupancy tables instead of a bunch of if-else statements, and if we want to fix SDL_INF we'll have to update the data files anyway, so maybe we could just get that out of the way |
|
/run all |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
|
linter check isn't happy here either |
|
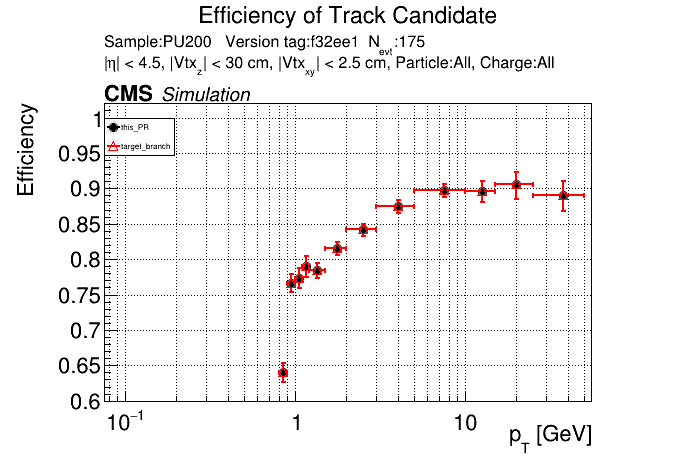
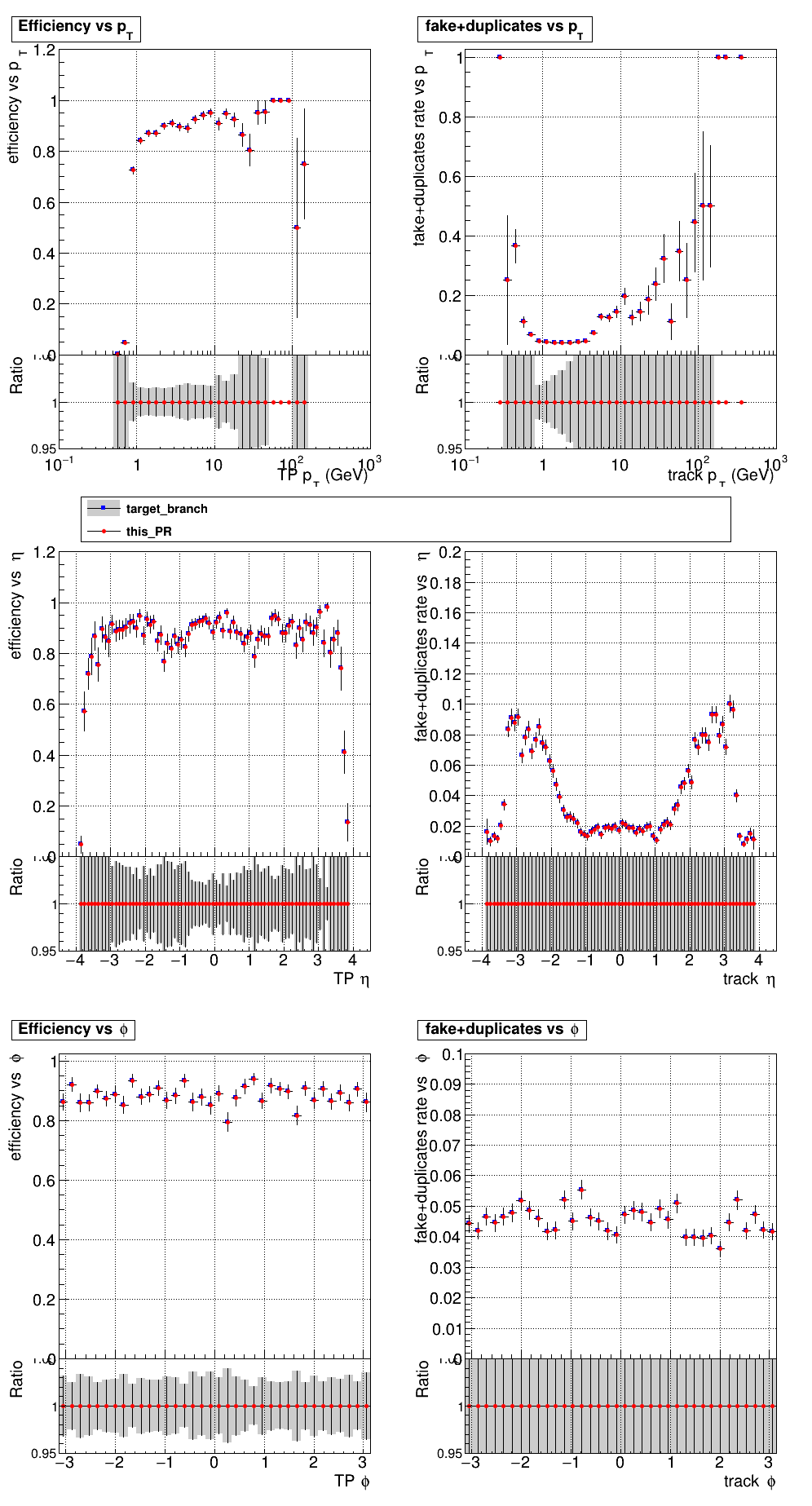
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
@ariostas When I run the code format I see a bunch of suggestions for files not related to this PR: 
|
did you update to the new release or still reused the old release area with a new cmsrel? |
|
Oh no, I haven't updated. Let me do that and try again. |
|
/run all |
|
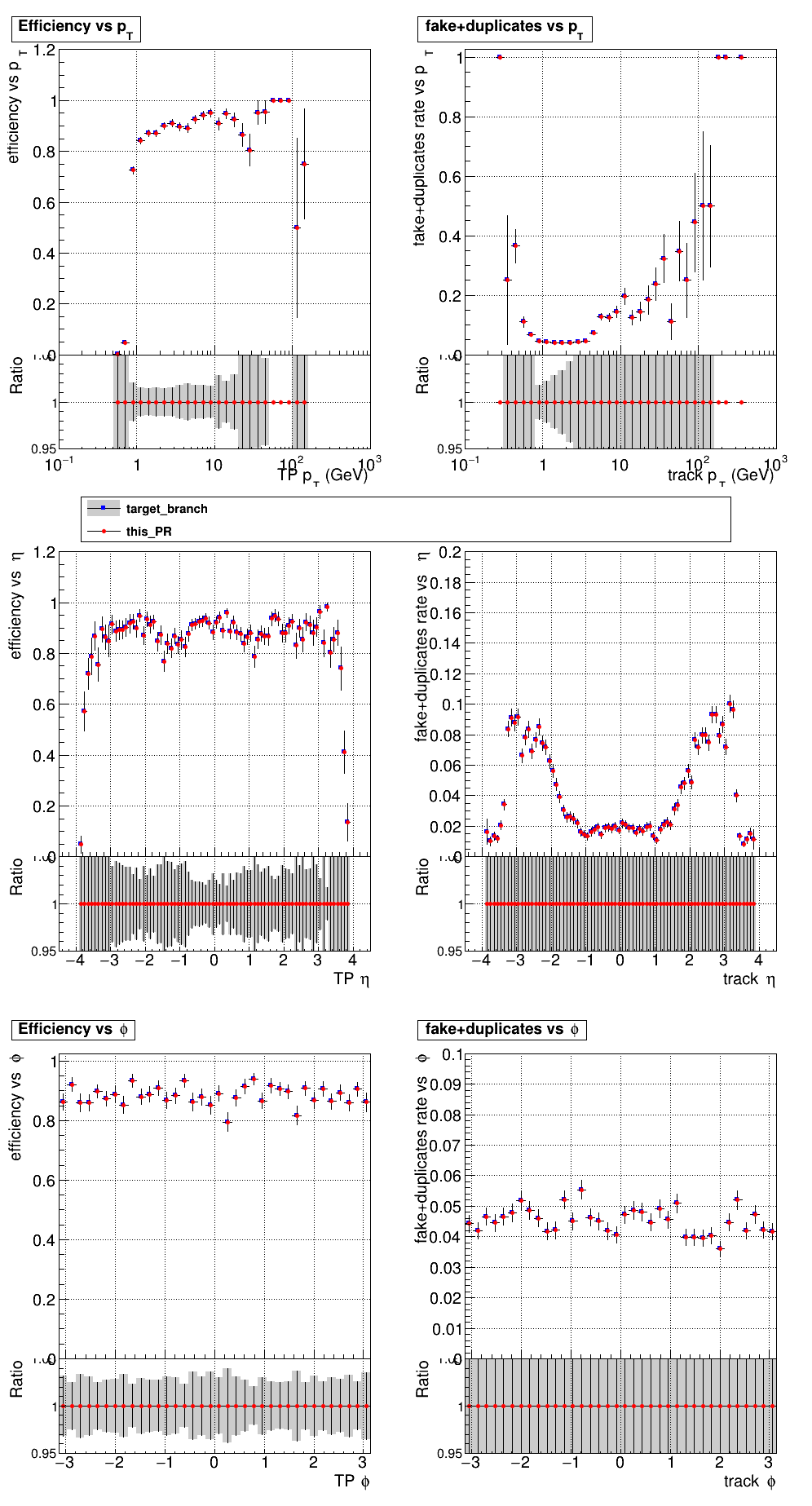
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
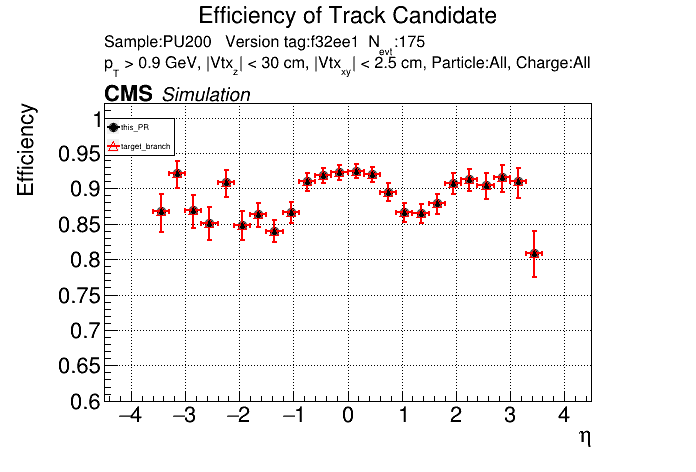
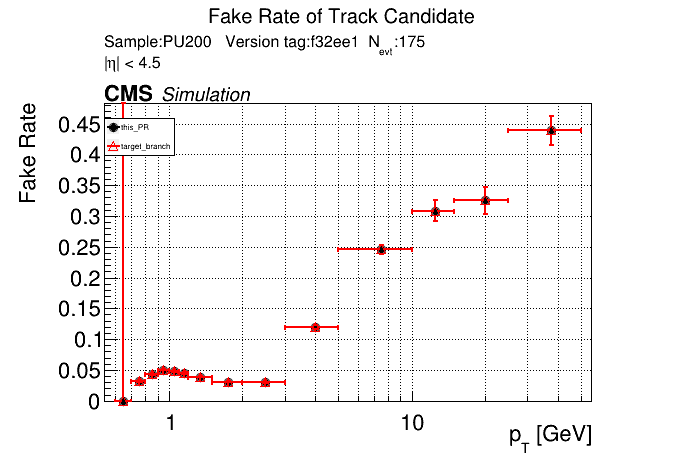
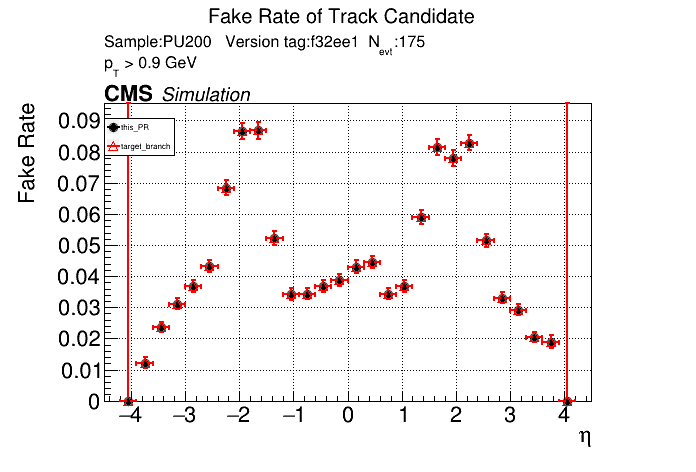
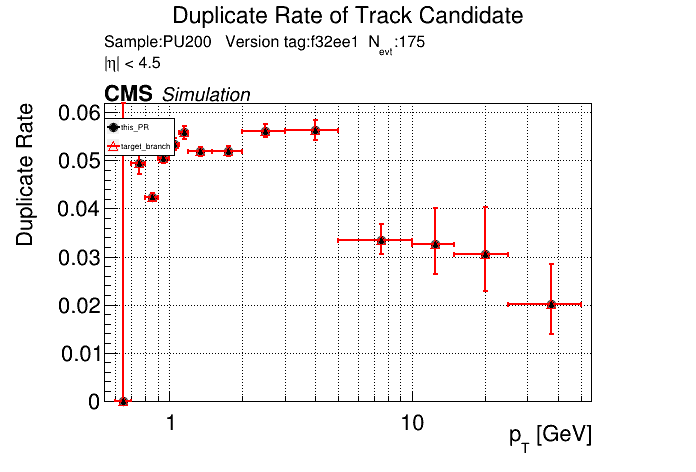
I have the same issue. I'm not sure how to get around it. I think they didn't format all files after clang-format got updated |
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
3000f9b
into
CMSSW_14_1_0_pre3_LST_X_LSTCore_realfiles_batch1_devel
|
the linter complaints are for parts of the files not touched by this PR |
there is practically no change in the CPU backend: MD changes from 326.4 to 323.1; the other run was faster by around 1 s. |
Below is run on the L40.
This PR Timing:


Master Timing:
MD creation time goes from 1.0ms to 0.4ms, meaning that the redundant matrix creation mentioned below represented the majority of the MD creation time on GPU... 😱 @slava77