![]()
![]()
![]()
![]()

What is recommender System?
- Based on previous(past) behaviours, it predicts the likelihood that a user would prefer an item.
- For example, Netflix uses recommendation system. It suggest people new movies according to their past activities that are like watching and voting movies.
- The purpose of recommender systems is recommending new things that are not seen before from people.
- Content-Based recommender system tries to guess the features or behavior of a user given the item’s features, he/she reacts positively to.
- Once, we know the likings of the user we can embed user's choice in an embedding space using the feature vector generated and recommend accordingly.
- Collaborative does not need the features of the items to be given. Every user and item is described by a feature vector or embedding.
- It creates embedding for both users and items on its own. It embeds both users and items in the same embedding space.
- It considers other users’ reactions while recommending a particular user. It notes which items a particular user likes and also the items that the users with behavior and likings like him/her likes, to recommend items to that user.
- It collects user feedbacks on different items and uses them for recommendations.
- Remembering the matrix is not required here. From the matrix, we try to learn how a specific user or an item behaves. We compress the large interaction matrix using dimensional Reduction or using clustering algorithms. In this type, We fit machine learning models and try to predict how many ratings will a user give a product.
- There are several methods:
Clustering algorithms
Matrix Factorization based algorithm
Deep Learning methods
They are mathematical measures which are used to determine how similar is a vector to a given vector.
Similarity metrics used mostly:
- Cosine Similarity: The Cosine angle between the vectors.
- Dot Product: The cosine angle and magnitude of the vectors also matters.
- Euclidian Distance: The elementwise squared distance between two vectors
- Pearson Similarity: It is a coefficient given by:
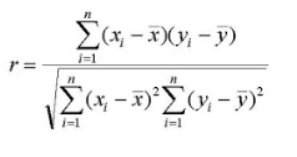
This project aims at finding the multiple ways that our data can recommend books.
Book-Crossing: User review ratings
This dataset Contains 278,858 users (anonymized but with demographic information) providing 1,149,780 ratings (explicit / implicit) about 271,379 books.
| Field | Description |
|---|---|
| User-ID | Book reader's unique user ID |
| ISBN | ISBN of book |
| Book Rating | Book rating by individual user |
| Book Title | Book title |
| Book Author | Book author |
| Publisher | Book publisher |
| Age | Age of user |
| City | City where user is from |
| State | State where user is from |
| Country | Country where user is from |
| Category | Book Category |
| Language | Language of the book |
| Summary | Short summary about the book |
| img_* | Book cover image |
Libraries: NumPy pandas nltk matplotlib sklearn
common_books['index'] = [i for i in range(common_books.shape[0])]
target_cols = ['book_title','book_author','publisher','Category']
common_books['combined_features'] = [' '.join(common_books[target_cols].iloc[i,].values) for i in range(common_books[target_cols].shape[0])]
cv = CountVectorizer()
count_matrix = cv.fit_transform(common_books['combined_features'])
cosine_sim = cosine_similarity(count_matrix)
x_counts_df = pd.DataFrame(count_matrix.toarray())
x_counts_df.columns = cv.get_feature_names()
cosine_data_ = pd.DataFrame(cosine_sim)
cosine_data_.index = common_books.book_title
cosine_data_.columns = common_books.book_title
index = common_books[common_books['book_title'] == book_title]['index'].values[0]
sim_books = list(enumerate(cosine_sim[index]))
sorted_sim_books = sorted(sim_books,key=lambda x:x[1],
reverse=True)[1:6]
books = []
for i in range(len(sorted_sim_books)):
books.append(common_books[common_books['index'] == sorted_sim_books[i][0]]['book_title'].item())
Note: We have separated rare and common books on the basis of number of user ratings.

{kind=link}
cosine_data_["The Da Vinci Code"].sort_values(ascending = False)
book_title
The Da Vinci Code 1.000000
The Catcher in the Rye 0.426401
The Client 0.400892
The King of Torts 0.353553
A Map of the World 0.335410
common_books = common_books.drop_duplicates(subset = ["book_title"])
common_books.reset_index(inplace = True)
common_books['index'] = [i for i in range(common_books.shape[0])]
summary_filtered = []
for i in common_books['Summary']:
i = re.sub("[^a-zA-Z]"," ",i).lower()
i = nltk.word_tokenize(i)
i = [word for word in i if not word in set(stopwords.words("english"))]
i = " ".join(i)
summary_filtered.append(i)
common_books['Summary'] = summary_filtered
cv = CountVectorizer()
count_matrix = cv.fit_transform(common_books['Summary'])
cosine_sim = cosine_similarity(count_matrix)
index = common_books[common_books['book_title'] == book_title]['index'].values[0]
sim_books = list(enumerate(cosine_sim[index]))
sorted_sim_books = sorted(sim_books,key=lambda x:x[1],reverse=True)[1:6]
books = []
for i in range(len(sorted_sim_books)):
books.append(common_books[common_books['index'] == sorted_sim_books[i][0]]['book_title'].item())

user_book_df = common_books.pivot_table(index=['user_id'],
columns=['book_title'],
values='rating')
#print(user_book_df)
book = user_book_df[book_title]
recom_data = pd.DataFrame(user_book_df.corrwith(book). \
sort_values(ascending=False)).reset_index(drop=False)
#print(recom_data)
if book_title in [book for book in recom_data['book_title']]:
recom_data = recom_data.drop(recom_data[recom_data['book_title'] == book_title].index[0])
low_rating = []
for i in recom_data['book_title']:
if df[df['book_title'] == i]['rating'].mean() < 5:
low_rating.append(i)
if recom_data.shape[0] - len(low_rating) > 5:
recom_data = recom_data[~recom_data['book_title'].isin(low_rating)]
recom_data = recom_data[0:5]
recom_data.columns = ['book_title','corr']

user_book_df = common_books.pivot_table(index=['book_title'],
columns=['user_id'],
values='rating').fillna(0)
# creating sparace matrix
user_book_df_matrix = csr_matrix(user_book_df.values)
model_knn = NearestNeighbors(metric="cosine", algorithm="brute")
model_knn.fit(user_book_df_matrix)
book_index= user_book_df.index.to_list().index(book_title)
distances, indices = model_knn.kneighbors(user_book_df.iloc[book_index,:].values.reshape(1,-1), n_neighbors =6)

Results for the book: "Harry Potter and the Order of the Phoenix (Book 5)"

Recommendation Systems
Collaborative filtering
Content based filtering
Similarity Metrics
Book recommendation using cosine similarity
Recommendation systems
Recommender systems tutorial
If you have any feedback, please reach out at [email protected]
I am an AI Enthusiast and Data science & ML practitioner
![]()
![]()
![]()
![]()