Implemention of Value Iteration and Policy Iteration (Gaussian elimination & Iterated Bellman update) along with graphical representation of estimated utility.

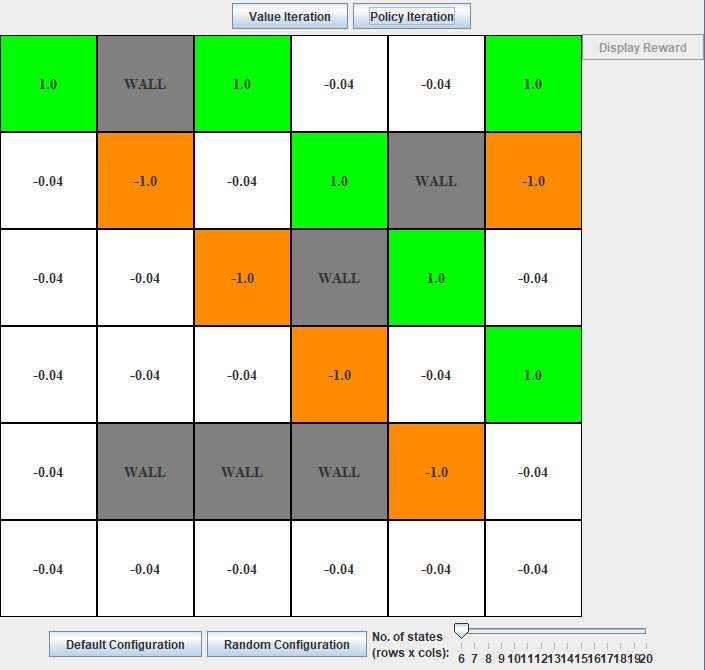
Each of the non-wall squares is defined as a non-terminal state. Green, Brown, White squares has a reward value of 1, -1, -0.04 respectively.
There are four possible actions, Ac = {UP, DOWN, LEFT, RIGHT}, which corresponds to an attempt of moving to the upper square, bottom square, left square, right square respectively from the state. As per the transition model, the probability of moving to the intended square has a 0.8 probability, and 0.1 probability each for either right angle of intended direction. If the action results in moving to a wall, the agent remains in the same square.
A discount factor of 0.99 is used for both Value Iteration and Policy Iteration to compute the MDP.
-
Click on square to change its state
-
Slider on bottom right to change size of maze
- Click on 'Value Iteration' or 'Policy Iteration', the program will generate a plotted graph visualization in a new window.


(We can note that Policy iteration is more efficient as it takes less iteration)
-
Click on 'Display Utility' or 'Display Policy' to switch between displayed information.




- jfreechart (included) - https://github.com/jfree/jfreechart
A compiled Java executable file is included.
- Files
- Import
- Existing Projects into WorkSpace
- Select root directory (Browse to unzipped folder)
- Finish
- Right click on project
- Run As
- Java Application
- Main (default package)
- OK
- Michael Wooldridge (2009), an introduction to MultiAgent Systems (pp. 645-657). John Wiley&Sons