bigdl-llm is a library for running LLM (large language model) on Intel XPU (from Laptop to GPU to Cloud) using INT4/FP4/INT8/FP8 with very low latency1 (for any PyTorch model).
It is built on the excellent work of llama.cpp, bitsandbytes, qlora, gptq, AutoGPTQ, awq, AutoAWQ, vLLM, llama-cpp-python, gptq_for_llama, chatglm.cpp, redpajama.cpp, gptneox.cpp, bloomz.cpp, etc.
- [2023/12]
bigdl-llmnow supports Mixtra-7x8B on both Intel GPU and CPU. - [2023/12]
bigdl-llmnow supports QA-LoRA (see "QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models") - [2023/12]
bigdl-llmnow supports FP8 and FP4 inference on Intel GPU. - [2023/11] Initial support for directly loading GGUF, AWQ and GPTQ models in to
bigdl-llmis available. - [2023/11] Initial support for vLLM continuous batching is availabe on Intel CPU.
- [2023/11] Initial support for vLLM continuous batching is availabe on Intel GPU.
- [2023/10] QLoRA finetuning on Intel CPU is available.
- [2023/10] QLoRA finetuning on Intel GPU is available.
- [2023/09]
bigdl-llmnow supports Intel GPU (including Arc, Flex and MAX) - [2023/09]
bigdl-llmtutorial is released. - [2023/09] Over 30 models have been optimized/verified on
bigdl-llm, including LLaMA/LLaMA2, ChatGLM2/ChatGLM3, Mistral, Falcon, MPT, LLaVA, WizardCoder, Dolly, Whisper, Baichuan/Baichuan2, InternLM, Skywork, QWen/Qwen-VL, Aquila, MOSS, and more; see the complete list here.
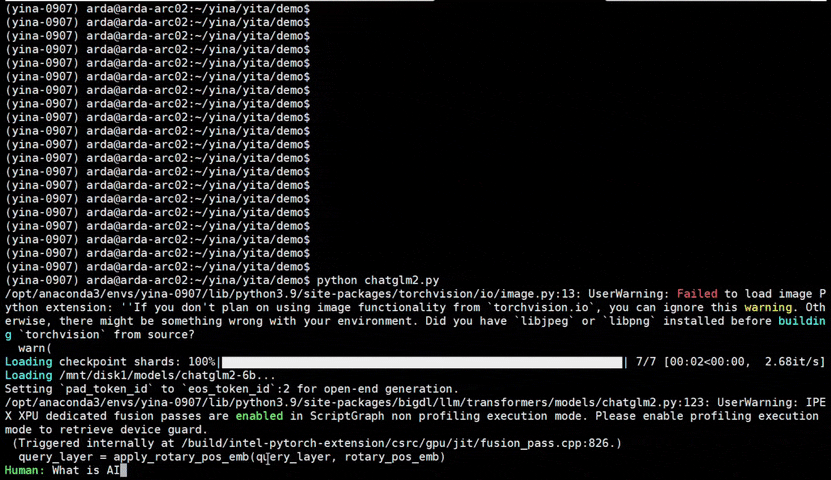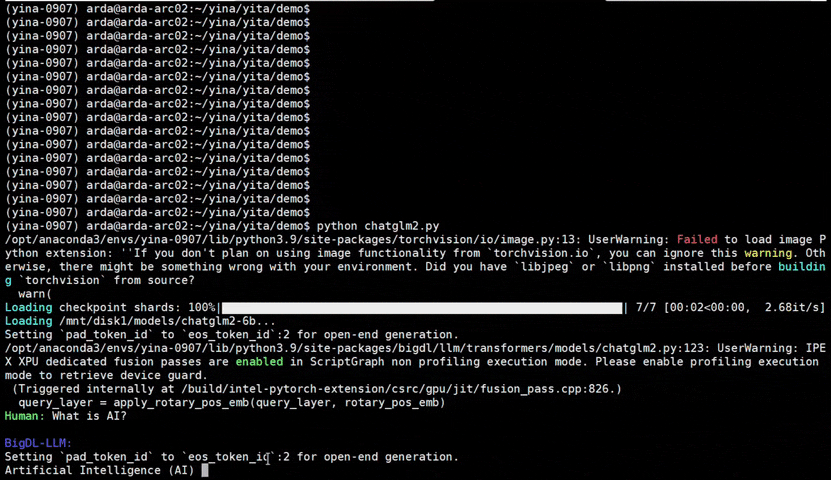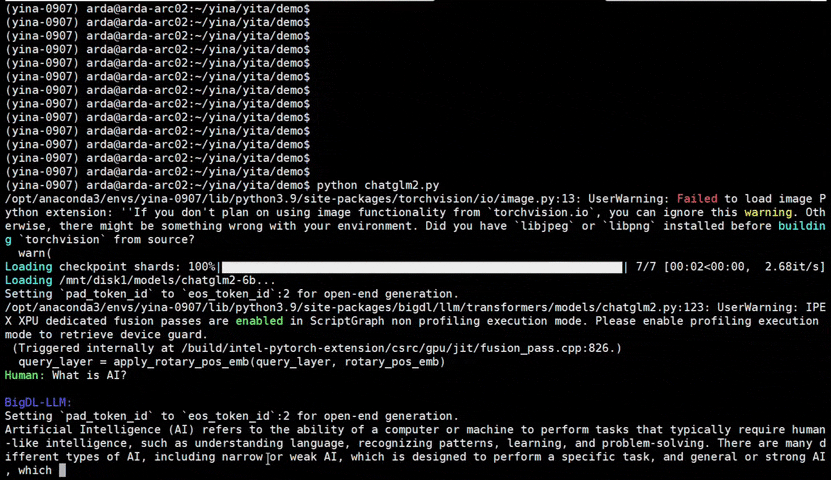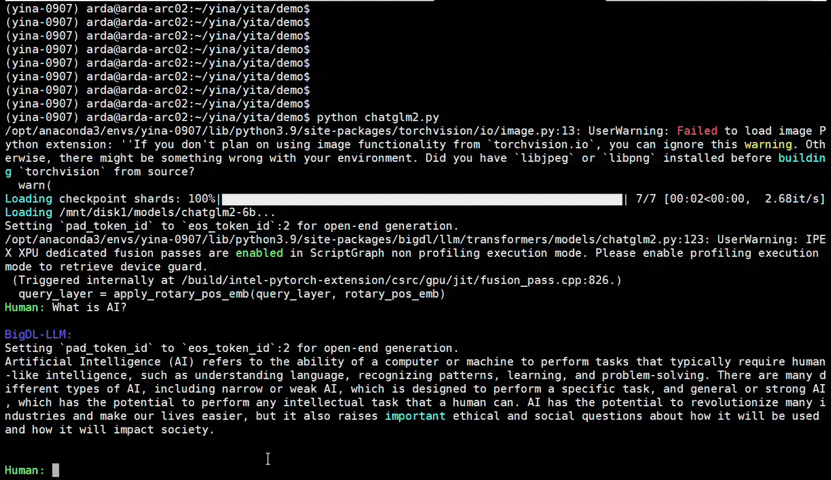
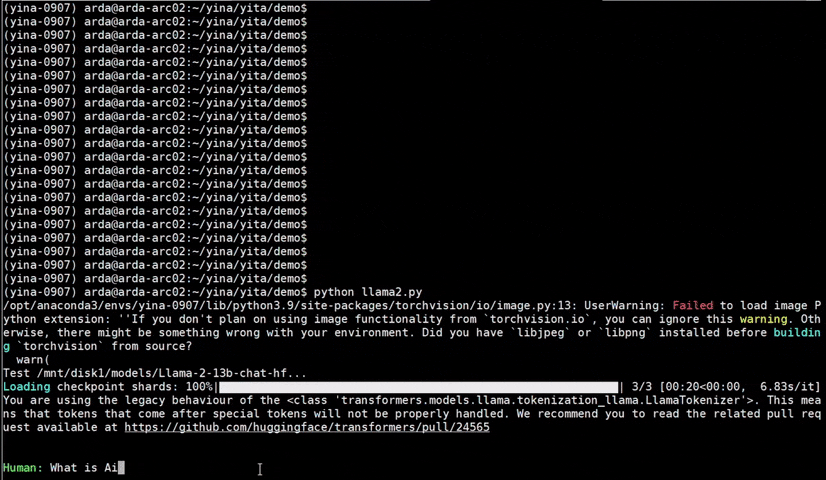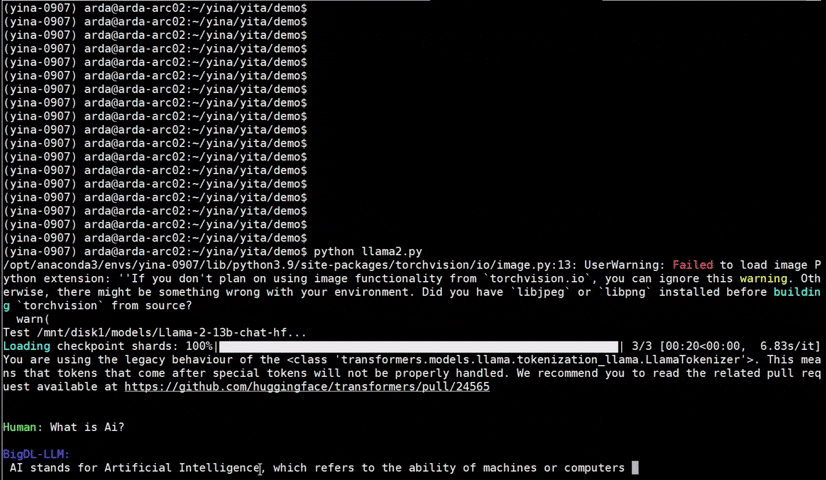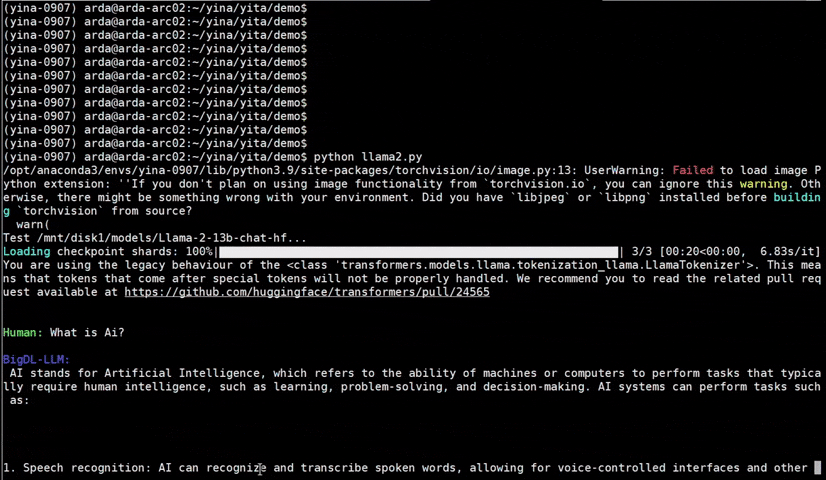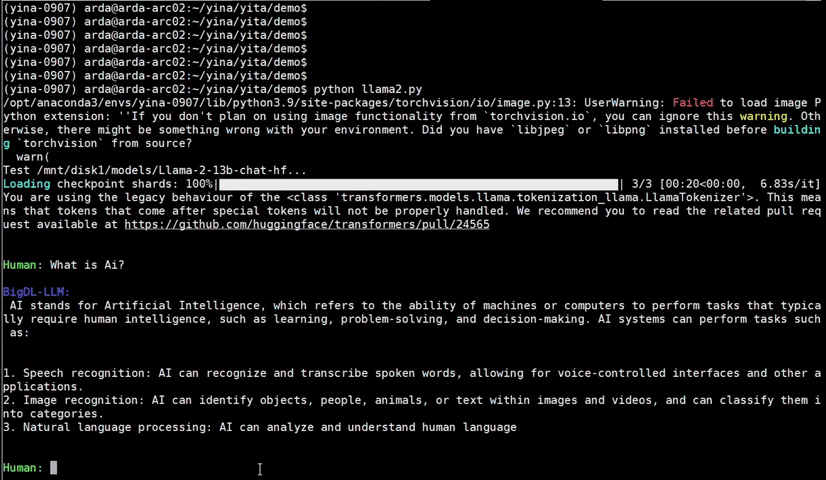
See the optimized performance of chatglm2-6b and llama-2-13b-chat models on 12th Gen Intel Core CPU and Intel Arc GPU below.
| 12th Gen Intel Core CPU | Intel Arc GPU | ||
|
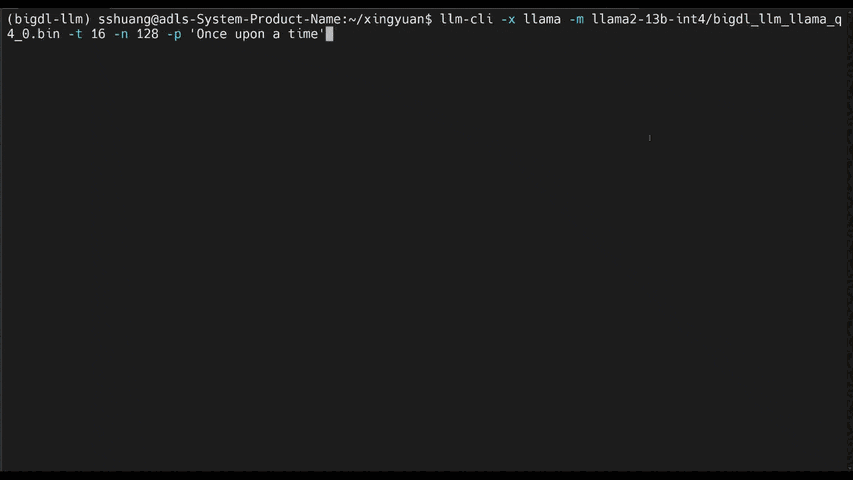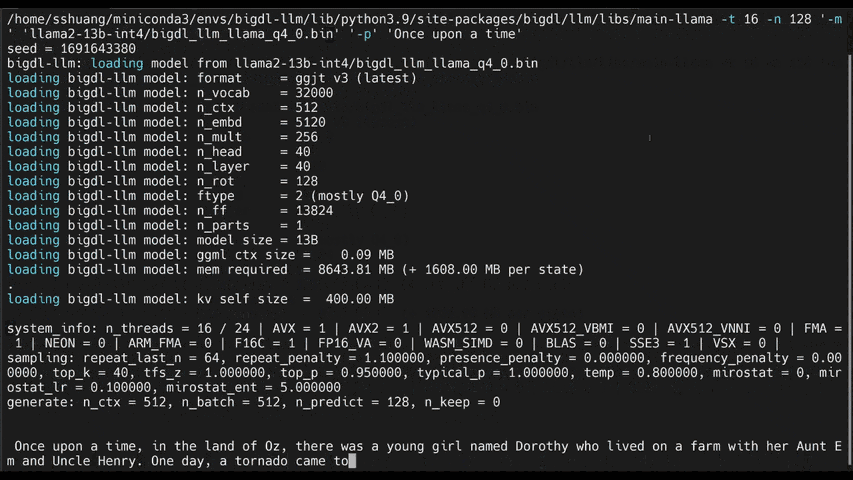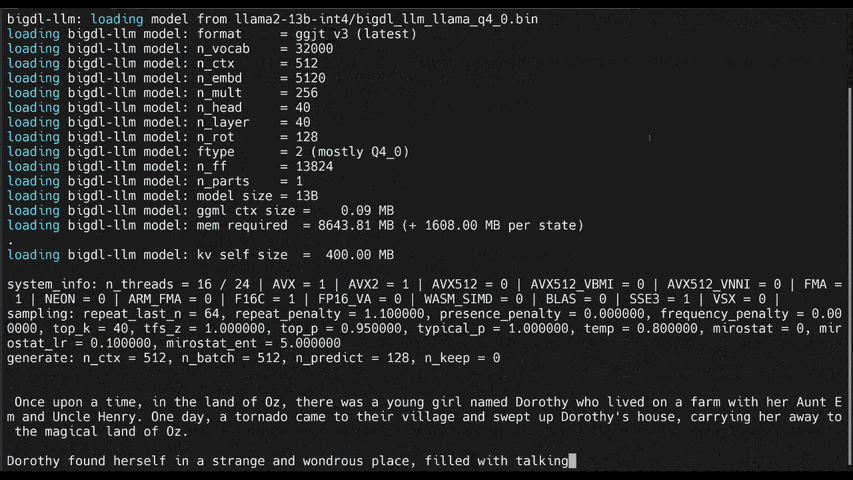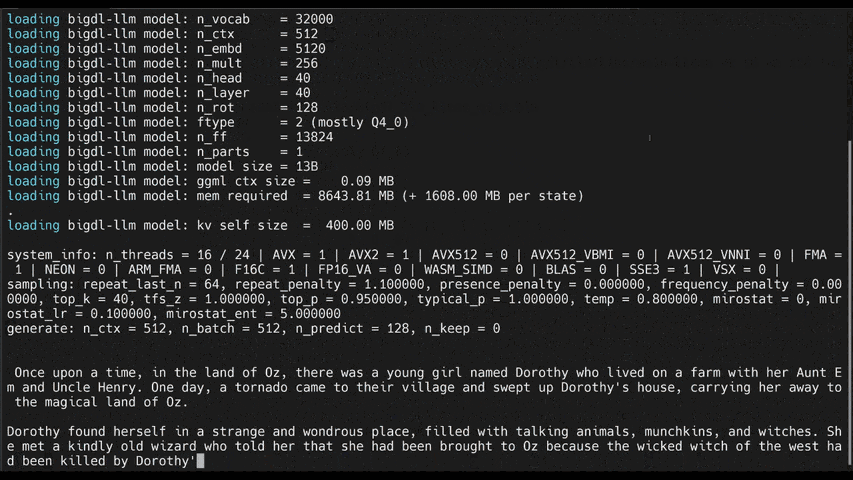
|
|
|
chatglm2-6b |
llama-2-13b-chat |
chatglm2-6b |
llama-2-13b-chat |
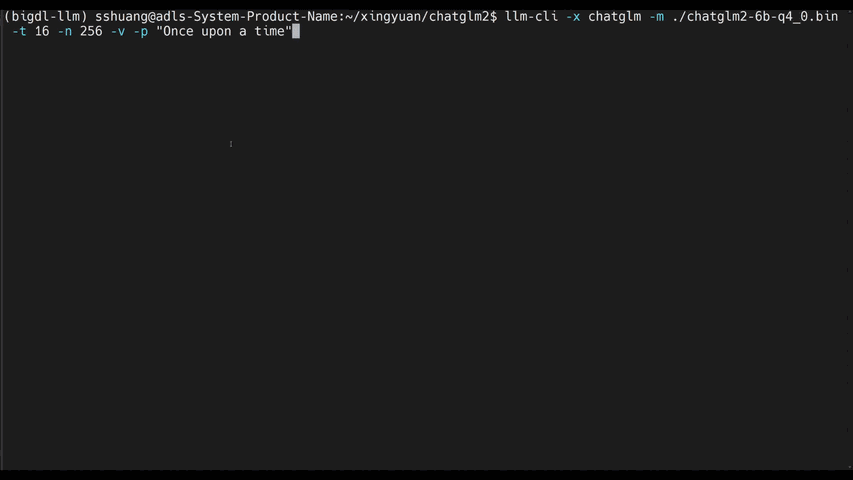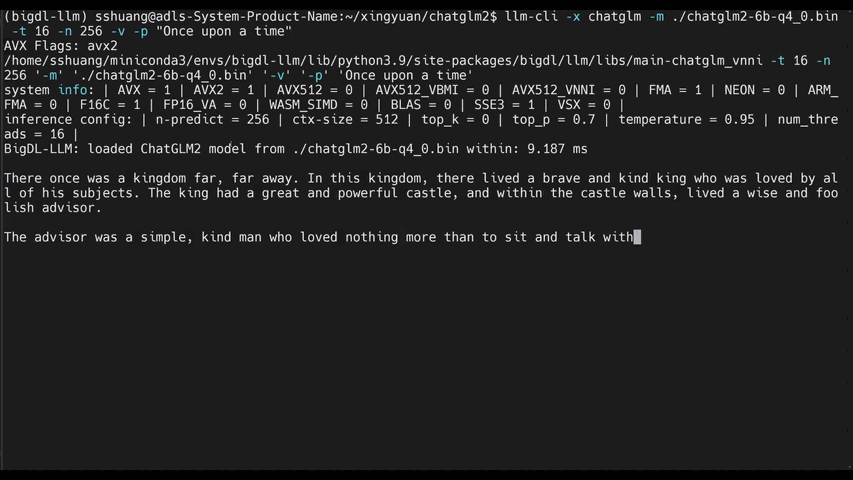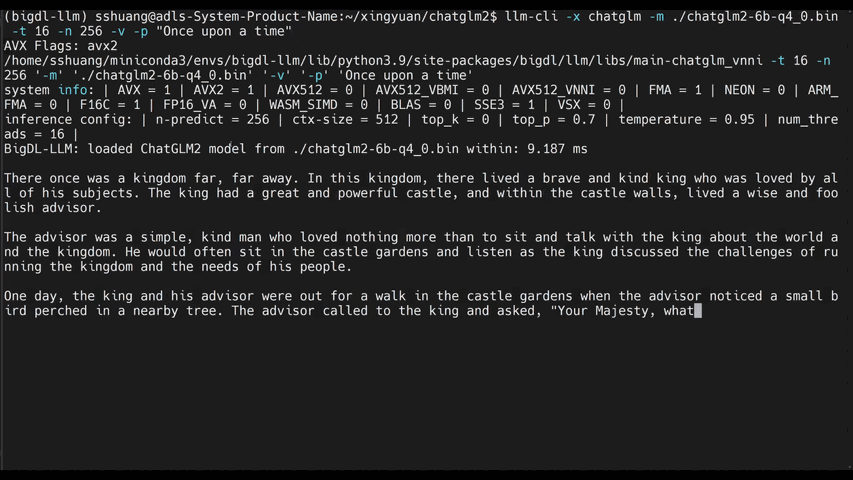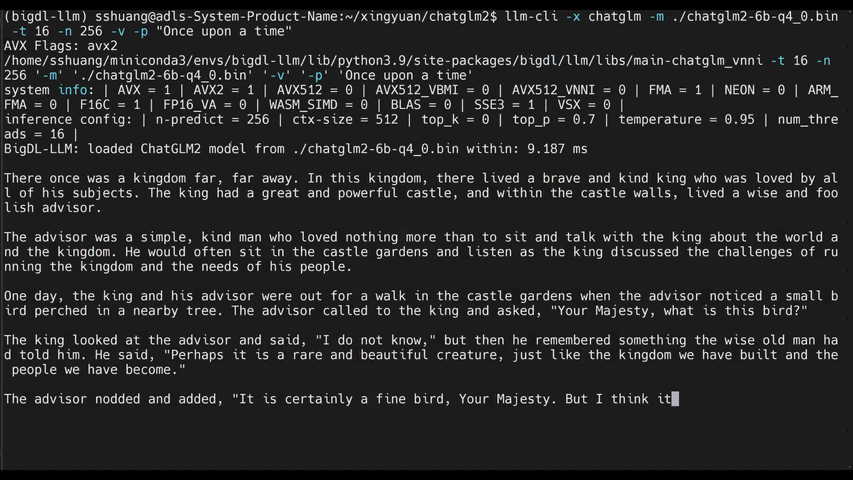
You may install bigdl-llm on Intel CPU as follows:
pip install --pre --upgrade bigdl-llm[all]Note:
bigdl-llmhas been tested on Python 3.9
You may apply INT4 optimizations to any Hugging Face Transformers models as follows.
#load Hugging Face Transformers model with INT4 optimizations
from bigdl.llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
#run the optimized model on CPU
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
input_ids = tokenizer.encode(input_str, ...)
output_ids = model.generate(input_ids, ...)
output = tokenizer.batch_decode(output_ids)See the complete examples here.
You may install bigdl-llm on Intel GPU as follows:
# below command will install intel_extension_for_pytorch==2.0.110+xpu as default
# you can install specific ipex/torch version for your need
pip install --pre --upgrade bigdl-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpuNote:
bigdl-llmhas been tested on Python 3.9
See the GPU installation guide for mode details.
You may apply INT4 optimizations to any Hugging Face Transformers models as follows.
#load Hugging Face Transformers model with INT4 optimizations
from bigdl.llm.transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)
#run the optimized model on Intel GPU
model = model.to('xpu')
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
input_ids = tokenizer.encode(input_str, ...).to('xpu')
output_ids = model.generate(input_ids, ...)
output = tokenizer.batch_decode(output_ids.cpu())See the complete examples here.
After the model is optimized using bigdl-llm, you may save and load the model as follows:
model.save_low_bit(model_path)
new_model = AutoModelForCausalLM.load_low_bit(model_path)See the complete example here.
In addition to INT4, You may apply other low bit optimizations (such as INT8, INT5, NF4, etc.) as follows:
model = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_low_bit="sym_int8")See the complete example here.
Over 20 models have been optimized/verified on bigdl-llm, including LLaMA/LLaMA2, ChatGLM/ChatGLM2, Mistral, Falcon, MPT, Baichuan/Baichuan2, InternLM, QWen and more; see the example list below.
| Model | CPU Example | GPU Example |
|---|---|---|
| LLaMA (such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.) | link1, link2 | link |
| LLaMA 2 | link1, link2 | link1, link2-low GPU memory example |
| ChatGLM | link | |
| ChatGLM2 | link | link |
| ChatGLM3 | link | link |
| Mistral | link | link |
| Mixtral | link | link |
| Falcon | link | link |
| MPT | link | link |
| Dolly-v1 | link | link |
| Dolly-v2 | link | link |
| Replit Code | link | link |
| RedPajama | link1, link2 | |
| Phoenix | link1, link2 | |
| StarCoder | link1, link2 | link |
| Baichuan | link | link |
| Baichuan2 | link | link |
| InternLM | link | link |
| Qwen | link | link |
| Qwen-VL | link | link |
| Aquila | link | link |
| Aquila2 | link | link |
| MOSS | link | |
| Whisper | link | link |
| Phi-1_5 | link | link |
| Flan-t5 | link | link |
| LLaVA | link | link |
| CodeLlama | link | link |
| Skywork | link | |
| InternLM-XComposer | link | |
| WizardCoder-Python | link | |
| CodeShell | link | |
| Fuyu | link | |
| Distil-Whisper | link | link |
| Yi | link | link |
| BlueLM | link | link |
For more details, please refer to the bigdl-llm Document, Readme, Tutorial and API Doc.
BigDL seamlessly scales your data analytics & AI applications from laptop to cloud, with the following libraries:
-
LLM: Low-bit (INT3/INT4/INT5/INT8) large language model library for Intel CPU/GPU
-
Orca: Distributed Big Data & AI (TF & PyTorch) Pipeline on Spark and Ray
-
Nano: Transparent Acceleration of Tensorflow & PyTorch Programs on Intel CPU/GPU
-
DLlib: “Equivalent of Spark MLlib” for Deep Learning
-
Chronos: Scalable Time Series Analysis using AutoML
-
Friesian: End-to-End Recommendation Systems
-
PPML: Secure Big Data and AI (with SGX/TDX Hardware Security)
For more information, you may read the docs.
flowchart TD;
Feature1{{HW Secured Big Data & AI?}};
Feature1-- No -->Feature2{{Python vs. Scala/Java?}};
Feature1-- "Yes" -->ReferPPML([<em><strong>PPML</strong></em>]);
Feature2-- Python -->Feature3{{What type of application?}};
Feature2-- Scala/Java -->ReferDLlib([<em><strong>DLlib</strong></em>]);
Feature3-- "Large Language Model" -->ReferLLM([<em><strong>LLM</strong></em>]);
Feature3-- "Big Data + AI (TF/PyTorch)" -->ReferOrca([<em><strong>Orca</strong></em>]);
Feature3-- Accelerate TensorFlow / PyTorch -->ReferNano([<em><strong>Nano</strong></em>]);
Feature3-- DL for Spark MLlib -->ReferDLlib2([<em><strong>DLlib</strong></em>]);
Feature3-- High Level App Framework -->Feature4{{Domain?}};
Feature4-- Time Series -->ReferChronos([<em><strong>Chronos</strong></em>]);
Feature4-- Recommender System -->ReferFriesian([<em><strong>Friesian</strong></em>]);
click ReferLLM "https://github.com/intel-analytics/bigdl/tree/main/python/llm"
click ReferNano "https://github.com/intel-analytics/bigdl#nano"
click ReferOrca "https://github.com/intel-analytics/bigdl#orca"
click ReferDLlib "https://github.com/intel-analytics/bigdl#dllib"
click ReferDLlib2 "https://github.com/intel-analytics/bigdl#dllib"
click ReferChronos "https://github.com/intel-analytics/bigdl#chronos"
click ReferFriesian "https://github.com/intel-analytics/bigdl#friesian"
click ReferPPML "https://github.com/intel-analytics/bigdl#ppml"
classDef ReferStyle1 fill:#5099ce,stroke:#5099ce;
classDef Feature fill:#FFF,stroke:#08409c,stroke-width:1px;
class ReferLLM,ReferNano,ReferOrca,ReferDLlib,ReferDLlib2,ReferChronos,ReferFriesian,ReferPPML ReferStyle1;
class Feature1,Feature2,Feature3,Feature4,Feature5,Feature6,Feature7 Feature;
-
To install BigDL, we recommend using conda environment:
conda create -n my_env conda activate my_env pip install bigdl
To install latest nightly build, use
pip install --pre --upgrade bigdl; see Python and Scala user guide for more details. -
To install each individual library, such as Chronos, use
pip install bigdl-chronos; see the document website for more details.
-
The Orca library seamlessly scales out your single node TensorFlow, PyTorch or OpenVINO programs across large clusters (so as to process distributed Big Data).
Show Orca example
You can build end-to-end, distributed data processing & AI programs using Orca in 4 simple steps:
# 1. Initilize Orca Context (to run your program on K8s, YARN or local laptop) from bigdl.orca import init_orca_context, OrcaContext sc = init_orca_context(cluster_mode="k8s", cores=4, memory="10g", num_nodes=2) # 2. Perform distribtued data processing (supporting Spark DataFrames, # TensorFlow Dataset, PyTorch DataLoader, Ray Dataset, Pandas, Pillow, etc.) spark = OrcaContext.get_spark_session() df = spark.read.parquet(file_path) df = df.withColumn('label', df.label-1) ... # 3. Build deep learning models using standard framework APIs # (supporting TensorFlow, PyTorch, Keras, OpenVino, etc.) from tensorflow import keras ... model = keras.models.Model(inputs=[user, item], outputs=predictions) model.compile(...) # 4. Use Orca Estimator for distributed training/inference from bigdl.orca.learn.tf.estimator import Estimator est = Estimator.from_keras(keras_model=model) est.fit(data=df, feature_cols=['user', 'item'], label_cols=['label'], ...)
See Orca user guide, as well as TensorFlow and PyTorch quickstarts, for more details.
-
In addition, you can also run standard Ray programs on Spark cluster using RayOnSpark in Orca.
Show RayOnSpark example
You can not only run Ray program on Spark cluster, but also write Ray code inline with Spark code (so as to process the in-memory Spark RDDs or DataFrames) using RayOnSpark in Orca.
# 1. Initilize Orca Context (to run your program on K8s, YARN or local laptop) from bigdl.orca import init_orca_context, OrcaContext sc = init_orca_context(cluster_mode="yarn", cores=4, memory="10g", num_nodes=2, init_ray_on_spark=True) # 2. Distribtued data processing using Spark spark = OrcaContext.get_spark_session() df = spark.read.parquet(file_path).withColumn(...) # 3. Convert Spark DataFrame to Ray Dataset from bigdl.orca.data import spark_df_to_ray_dataset dataset = spark_df_to_ray_dataset(df) # 4. Use Ray to operate on Ray Datasets import ray @ray.remote def consume(data) -> int: num_batches = 0 for batch in data.iter_batches(batch_size=10): num_batches += 1 return num_batches print(ray.get(consume.remote(dataset)))
See RayOnSpark user guide and quickstart for more details.
You can transparently accelerate your TensorFlow or PyTorch programs on your laptop or server using Nano. With minimum code changes, Nano automatically applies modern CPU optimizations (e.g., SIMD, multiprocessing, low precision, etc.) to standard TensorFlow and PyTorch code, with up-to 10x speedup.
Show Nano inference example
You can automatically optimize a trained PyTorch model for inference or deployment using Nano:
model = ResNet18().load_state_dict(...)
train_dataloader = ...
val_dataloader = ...
def accuracy (pred, target):
...
from bigdl.nano.pytorch import InferenceOptimizer
optimizer = InferenceOptimizer()
optimizer.optimize(model,
training_data=train_dataloader,
validation_data=val_dataloader,
metric=accuracy)
new_model, config = optimizer.get_best_model()
optimizer.summary()The output of optimizer.summary() will be something like:
-------------------------------- ---------------------- -------------- ----------------------
| method | status | latency(ms) | metric value |
-------------------------------- ---------------------- -------------- ----------------------
| original | successful | 45.145 | 0.975 |
| bf16 | successful | 27.549 | 0.975 |
| static_int8 | successful | 11.339 | 0.975 |
| jit_fp32_ipex | successful | 40.618 | 0.975* |
| jit_fp32_ipex_channels_last | successful | 19.247 | 0.975* |
| jit_bf16_ipex | successful | 10.149 | 0.975 |
| jit_bf16_ipex_channels_last | successful | 9.782 | 0.975 |
| openvino_fp32 | successful | 22.721 | 0.975* |
| openvino_int8 | successful | 5.846 | 0.962 |
| onnxruntime_fp32 | successful | 20.838 | 0.975* |
| onnxruntime_int8_qlinear | successful | 7.123 | 0.981 |
-------------------------------- ---------------------- -------------- ----------------------
* means we assume the metric value of the traced model does not change, so we don't recompute metric value to save time.
Optimization cost 60.8s in total.
Show Nano Training example
You may easily accelerate PyTorch training (e.g., IPEX, BF16, Multi-Instance Training, etc.) using Nano:
model = ResNet18()
optimizer = torch.optim.SGD(...)
train_loader = ...
val_loader = ...
from bigdl.nano.pytorch import TorchNano
# Define your training loop inside `TorchNano.train`
class Trainer(TorchNano):
def train(self):
# call `setup` to prepare for model, optimizer(s) and dataloader(s) for accelerated training
model, optimizer, (train_loader, val_loader) = self.setup(model, optimizer,
train_loader, val_loader)
for epoch in range(num_epochs):
model.train()
for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
# replace the loss.backward() with self.backward(loss)
loss = loss_fuc(output, target)
self.backward(loss)
optimizer.step()
# Accelerated training (IPEX, BF16 and Multi-Instance Training)
Trainer(use_ipex=True, precision='bf16', num_processes=2).train()See Nano user guide and tutotial for more details.
With DLlib, you can write distributed deep learning applications as standard (Scala or Python) Spark programs, using the same Spark DataFrames and ML Pipeline APIs.
Show DLlib Scala example
You can build distributed deep learning applications for Spark using DLlib Scala APIs in 3 simple steps:
// 1. Call `initNNContext` at the beginning of the code:
import com.intel.analytics.bigdl.dllib.NNContext
val sc = NNContext.initNNContext()
// 2. Define the deep learning model using Keras-style API in DLlib:
import com.intel.analytics.bigdl.dllib.keras.layers._
import com.intel.analytics.bigdl.dllib.keras.Model
val input = Input[Float](inputShape = Shape(10))
val dense = Dense[Float](12).inputs(input)
val output = Activation[Float]("softmax").inputs(dense)
val model = Model(input, output)
// 3. Use `NNEstimator` to train/predict/evaluate the model using Spark DataFrame and ML pipeline APIs
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.feature.MinMaxScaler
import org.apache.spark.ml.Pipeline
import com.intel.analytics.bigdl.dllib.nnframes.NNEstimator
import com.intel.analytics.bigdl.dllib.nn.CrossEntropyCriterion
import com.intel.analytics.bigdl.dllib.optim.Adam
val spark = SparkSession.builder().getOrCreate()
val trainDF = spark.read.parquet("train_data")
val validationDF = spark.read.parquet("val_data")
val scaler = new MinMaxScaler().setInputCol("in").setOutputCol("value")
val estimator = NNEstimator(model, CrossEntropyCriterion())
.setBatchSize(128).setOptimMethod(new Adam()).setMaxEpoch(5)
val pipeline = new Pipeline().setStages(Array(scaler, estimator))
val pipelineModel = pipeline.fit(trainDF)
val predictions = pipelineModel.transform(validationDF)Show DLlib Python example
You can build distributed deep learning applications for Spark using DLlib Python APIs in 3 simple steps:
# 1. Call `init_nncontext` at the beginning of the code:
from bigdl.dllib.nncontext import init_nncontext
sc = init_nncontext()
# 2. Define the deep learning model using Keras-style API in DLlib:
from bigdl.dllib.keras.layers import Input, Dense, Activation
from bigdl.dllib.keras.models import Model
input = Input(shape=(10,))
dense = Dense(12)(input)
output = Activation("softmax")(dense)
model = Model(input, output)
# 3. Use `NNEstimator` to train/predict/evaluate the model using Spark DataFrame and ML pipeline APIs
from pyspark.sql import SparkSession
from pyspark.ml.feature import MinMaxScaler
from pyspark.ml import Pipeline
from bigdl.dllib.nnframes import NNEstimator
from bigdl.dllib.nn.criterion import CrossEntropyCriterion
from bigdl.dllib.optim.optimizer import Adam
spark = SparkSession.builder.getOrCreate()
train_df = spark.read.parquet("train_data")
validation_df = spark.read.parquet("val_data")
scaler = MinMaxScaler().setInputCol("in").setOutputCol("value")
estimator = NNEstimator(model, CrossEntropyCriterion())\
.setBatchSize(128)\
.setOptimMethod(Adam())\
.setMaxEpoch(5)
pipeline = Pipeline(stages=[scaler, estimator])
pipelineModel = pipeline.fit(train_df)
predictions = pipelineModel.transform(validation_df)See DLlib NNFrames and Keras API user guides for more details.
The Chronos library makes it easy to build fast, accurate and scalable time series analysis applications (with AutoML).
Show Chronos example
You can train a time series forecaster using Chronos in 3 simple steps:
from bigdl.chronos.forecaster import TCNForecaster
from bigdl.chronos.data.repo_dataset import get_public_dataset
# 1. Process time series data using `TSDataset`
tsdata_train, tsdata_val, tsdata_test = get_public_dataset(name='nyc_taxi')
for tsdata in [tsdata_train, tsdata_val, tsdata_test]:
data.roll(lookback=100, horizon=1)
# 2. Create a `TCNForecaster` (automatically configured based on train_data)
forecaster = TCNForecaster.from_tsdataset(train_data)
# 3. Train the forecaster for prediction
forecaster.fit(train_data)
pred = forecaster.predict(test_data)To apply AutoML, use AutoTSEstimator instead of normal forecasters.
# Create and fit an `AutoTSEstimator`
from bigdl.chronos.autots import AutoTSEstimator
autotsest = AutoTSEstimator(model="tcn", future_seq_len=10)
tsppl = autotsest.fit(data=tsdata_train, validation_data=tsdata_val)
pred = tsppl.predict(tsdata_test)See Chronos user guide and quick start for more details.
The Friesian library makes it easy to build end-to-end, large-scale recommedation system (including offline feature transformation and traning, near-line feature and model update, and online serving pipeline).
See Freisian readme for more details.
BigDL PPML provides a hardware (Intel SGX) protected Trusted Cluster Environment for running distributed Big Data & AI applications (in a secure fashion on private or public cloud).
See PPML user guide and tutorial for more details.
If you've found BigDL useful for your project, you may cite our papers as follows:
- BigDL 2.0: Seamless Scaling of AI Pipelines from Laptops to Distributed Cluster
@INPROCEEDINGS{9880257, title={BigDL 2.0: Seamless Scaling of AI Pipelines from Laptops to Distributed Cluster}, author={Dai, Jason Jinquan and Ding, Ding and Shi, Dongjie and Huang, Shengsheng and Wang, Jiao and Qiu, Xin and Huang, Kai and Song, Guoqiong and Wang, Yang and Gong, Qiyuan and Song, Jiaming and Yu, Shan and Zheng, Le and Chen, Yina and Deng, Junwei and Song, Ge}, booktitle={2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2022}, pages={21407-21414}, doi={10.1109/CVPR52688.2022.02076} }
- BigDL: A Distributed Deep Learning Framework for Big Data
@INPROCEEDINGS{10.1145/3357223.3362707, title = {BigDL: A Distributed Deep Learning Framework for Big Data}, author = {Dai, Jason Jinquan and Wang, Yiheng and Qiu, Xin and Ding, Ding and Zhang, Yao and Wang, Yanzhang and Jia, Xianyan and Zhang, Cherry Li and Wan, Yan and Li, Zhichao and Wang, Jiao and Huang, Shengsheng and Wu, Zhongyuan and Wang, Yang and Yang, Yuhao and She, Bowen and Shi, Dongjie and Lu, Qi and Huang, Kai and Song, Guoqiong}, booktitle = {Proceedings of the ACM Symposium on Cloud Computing (SoCC)}, year = {2019}, pages = {50–60}, doi = {10.1145/3357223.3362707} }
Footnotes
-
Performance varies by use, configuration and other factors.
bigdl-llmmay not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. ↩