![]()
Qawafi قوافي is a platform for Arabic poetry analyasis. The main idea is to create a tool that is able to analyze a given poem or list of baits by providing the following functionalities:
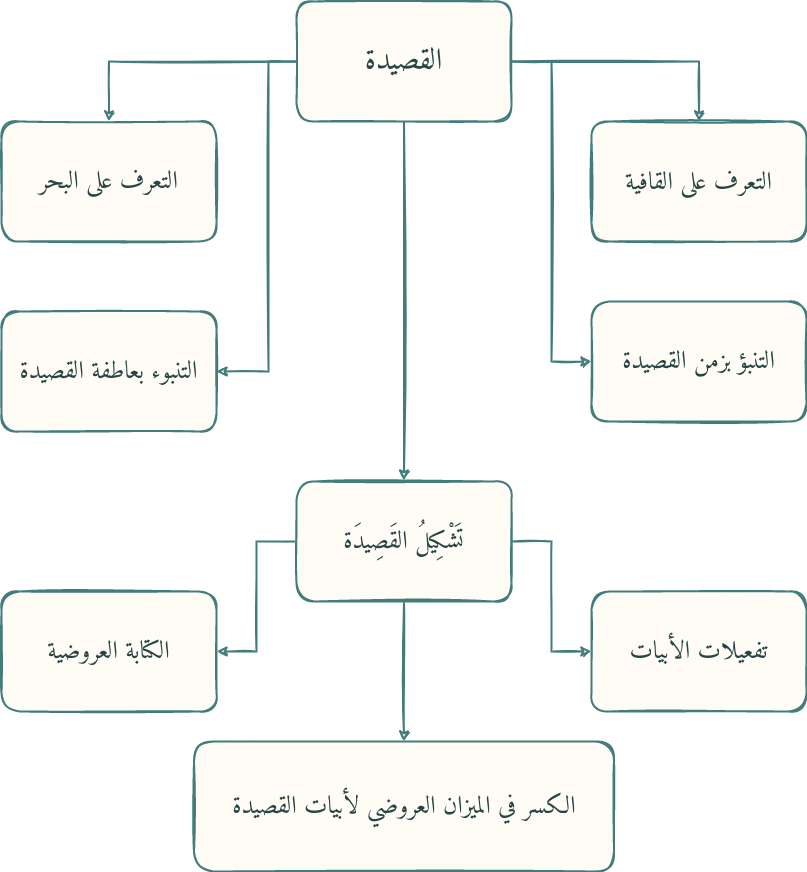
- Extract Arudi Style الكتابة العروضية
- Extract the closest bait to a given bait
- Extract the tafeelat تفعيلات
- Extract the meter بحر
- Extract the qafiyah قافية
- Extract the era and theme of a given poem
- Diacritize a given bait
We use deep learning for meter classification, theme and era classification. For closest bait we used our pretrained embeddings to find the closest bait using cosine similarity.
For most of the tasks in qawafi, we trainined on ashaar, a dataset colleccted from 5 well-known Arabic poetry websites. The datatset is uploaded to Huggingface Datasets Hub. The dataset can be downloaded as:
# pip install datasets
import datasets
ashaar = datasets.load_dataset('arbml/ashaar')
ashaarashaar is collected from mainly six online sources. There are other sources but with limited contribution to the dataset. These sources are:
- www.aldiwan.net
- www.poetry.dctabudhabi.ae
- www.poetsgate.com
- www.aldiwanalarabi.com
- www.adab.com
- www.diwany.org
| metric | value |
|---|---|
| number of poems | 254,630 |
| number of baits | 3,857,429 |
| number of poets | 7,167 |
qawafi implements the arudi rules related to tafeelat (تفعيلات). These rules include all the special cases related to each tafeela. As an example, we will work on Fawlon (فعولن) tafeela.
# to avoid the pain of paths, add qawafi_server to your python path
# in the current working directory of qawafi, do:
import sys
sys.path.append('qawafi_server/bohour')
# bohour should be in your path now.
from qawafi_server.bohour.tafeela import Fawlon
fawlon = Fawlon()
fawlon.allowed_zehafs
# >> [bohour.zehaf.Qabadh, bohour.zehaf.Thalm, bohour.zehaf.Tharm]
fawlon.fawlon.all_zehaf_tafeela_forms()
# >> [فعولنْ, فعول, عولنْ, عول]
# for the 0/1 pattern
fawlon.pattern_int
# >> 11010
# to be arabic friendly :)
fawlon.name
# >> 'فعولنْ'As meters (بحر الشعر) are constructed from tafeelat, we can build up meters with high flexibility specifiing the allowed special cases for each tafeela subjected to the constrains of that bahr. Consider the following example on kamel meter (بحر الكامل):
# continuing from the previous session
from bohour.bahr import Kamel
kamel = Kamel()
# this gives all the possible related bahrs to this bahr, like majzoo and mashtoor, etc.
kamel.sub_bahrs
# >> (bohour.bahr.KamelMajzoo,)
# this gives all the special cases related to this bahr at the end of each of each shatr
# this has been implemented as a mapping as follows
kamel.arod_dharbs_map
"""
>>>
{
bohour.zehaf.NoZehafNorEllah: (
bohour.zehaf.NoZehafNorEllah,
bohour.zehaf.Edmaar,
bohour.zehaf.Qataa,
bohour.zehaf.QataaAndEdmaar,
bohour.zehaf.HathathAndEdmaar
),
bohour.zehaf.Edmaar: (
bohour.zehaf.NoZehafNorEllah,
bohour.zehaf.Edmaar,
bohour.zehaf.Qataa,
bohour.zehaf.QataaAndEdmaar,
bohour.zehaf.HathathAndEdmaar
),
bohour.zehaf.Hathath: (bohour.zehaf.Hathath, bohour.zehaf.HathathAndEdmaar)
}
"""
# to show all the possible combinations of tafeelat of this bahr:
kamel.all_combinations
# >>
"""
((متفاعلنْ, متفاعلنْ, متفاعلنْ), (متفاعلنْ, متفاعلنْ, متفاعلنْ)),
((متفاعلنْ, متفاعلنْ, متفاعلنْ), (متفاعلنْ, متفاعلنْ, متْفاعلنْ)),
((متفاعلنْ, متفاعلنْ, متفاعلنْ), (متفاعلنْ, متفاعلنْ, متفاعلْ)),
((متفاعلنْ, متفاعلنْ, متفاعلنْ), (متفاعلنْ, متفاعلنْ, متْفاعلْ)),
((متفاعلنْ, متفاعلنْ, متفاعلنْ), (متفاعلنْ, متفاعلنْ, متْفا)),
... etc
"""
# to show the 0/1 combinations of the previous tafeelat:
kamel.all_combinations_patterns
# >> #
"""
'111011011101101110110111011011101101110110',
'111011011101101110110111011011101101010110',
'11101101110110111011011101101110110111010',
'11101101110110111011011101101110110101010',
'111011011101101110110111011011101101010',
'111011011101101110110111011010101101110110',
'111011011101101110110111011010101101010110',
'11101101110110111011011101101010110111010',
... etc
"""We collected and built a dataset of these tafeelat along with their patterns for the purpose of writing the comparing the arudi style to find out the broken places in the verse (البيت).
This resource is engineered to be easy to build with, customize and work on for eager developers to work on Arabic arud, the science of Arabic poetry.
A large dataset for meter classification. You can find the link in drive. The dataset contains
- train.txt : full dataset for training
- train50K.txt : max 50K baits for each class
- labels.txt : the label names for each class
The dataset could also be imported from huggingface
from datasets import load_dataset
dataset = load_dataset("Zaid/metrecv2", "train_all")
# or the smaller one
dataset = load_dataset("Zaid/metrecv2", "train_50k")We use the following notebooks for training
| Name | Notebook |
|---|---|
| Train meter classification models using Transformer |
|
| Train Era classification using Bidirectional GRUs. |
|
| Train Theme classification using Bidirectional GRUs. |
|
| Train the embedding model |
|
| Train the Diacratiziation model |
|
You can find all the pretrained models here.
You can test our modules using the following notebook
.
You can use the following code snippet to analyze a given diacritized input inside baits_input.txt
from qawafi_server.bait_analysis import BaitAnalysis
analysis = BaitAnalysis()
output = analysis.analyze(read_from_path='baits_input.txt', override_tashkeel=True)Sample output
{'arudi_style' : [['ألاليت شعري هل أبيتنن ليلتن بجنب لغضى أزجلقلاص ننواجيا',
'1101011010101101011011011010110101011010110110']],
'closest_baits' : [[('ألاليت شعري هل أبيتن ليلة # بجنب الغضى أزجي القِلاص '
'النواجيا',
[0.38896721601486206])]],
'closest_patterns': [('1101011010101101011011011010110101011010110110',
1.0,
'فعولنْ مفاعيلنْ فعولنْ مفاعلنْ # فعولنْ مفاعيلنْ '
'فعولنْ مفاعلنْ')],
'diacritized' : ['أَلَالَيْتُ شِعْرِي هَلْ أَبِيتَنَّ لَيْلَةً # بِجَنْبِ '
'الْغَضَى أَزْجِي الْقِلَاصَ النَّوَاجِيَا'],
'era' : ['العصر الحديث', 'العصر العثماني'],
'meter' : 'الطويل',
'qafiyah' : ('ي',
'قافية بحرف الروي: ي ، زاد لها الوصل بإشباع رويها زاد لها '
'التأسيس'),
'theme' : ['قصيدة رومنسيه', 'قصيدة شوق', 'قصيدة غزل']}
We first trained a CBHG model on Tashkeela then finetuned it on Ashaar. To use the model first clone the directory https://github.com/zaidalyafeai/Arabic_Diacritization
from predict import DiacritizationTester
tester = DiacritizationTester('config/test.yml', 'cbhg')
tester.infer("لا تعذل المشتاق في أشواقه حتى يكون حشاك في أحشائه")Gives the output لا تَعْذَلُ الْمُشْتَاقَ فِي أَشْوَاقِهِ حَتَّى يَكُونَ حَشَاكَ فِي أَحْشَائِهِ
You can use the notebook
to test more.
We developed an iOS app that interacts with the server
default.mp4
├── Bohour_iOS # iOS app
|
├── qawafi_server # qawafi server for extracting main analysis
|
├── shakkelha_server # server for diacritization fork of https://github.com/AliOsm/shakkelha
│
├── Notebooks
│ ├── theme.ipynb # theme classification training
│ ├── era.ipynb # era classification training
│ ├── meter.ipynb # meter classification training
│ └── embedding.ipynb # embedding training
├── demo.ipynb # main demo notebook
│
├── diac_inference.ipynb # diacritization inference
│
├── demo_requirements.txt # requirements to run demo.ipynb
│
└── README.md
@misc{qawafi2022,
author = {Zaid Alyafeai, Maged Saeed AlShaibani, Omar Hammad},
title = {Qawafi: Arabic Poetry Analysis Using Deep Learning and Knowledge Based Methods.},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/ARBML/qawafi}}
}