Stable Diffusion XL or SDXL is the latest image generation model that is tailored towards more photorealistic outputs with more detailed imagery and composition compared to previous Stable Diffusion models, including Stable Diffusion 2.1.
With Stable Diffusion XL you can now make more realistic images with improved face generation, produce legible text within images, and create more aesthetically pleasing art using shorter prompts.
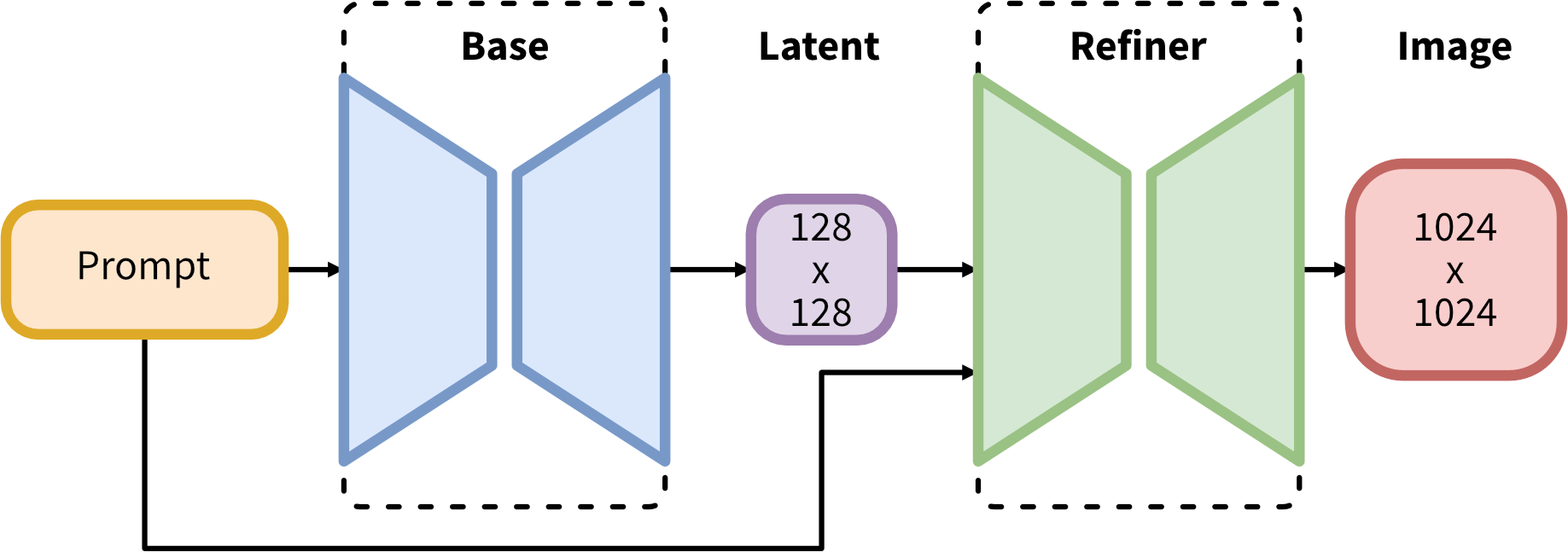
SDXL consists of an ensemble of experts pipeline for latent diffusion: In the first step, the base model is used to generate (noisy) latents, which are then further processed with a refinement model specialized for the final denoising steps. Note that the base model can be used as a standalone module or in a two-stage pipeline as follows: First, the base model is used to generate latents of the desired output size. In the second step, we use a specialized high-resolution model and apply a technique called SDEdit( also known as "image to image") to the latents generated in the first step, using the same prompt.
Compared to previous versions of Stable Diffusion, SDXL leverages a three times larger UNet backbone: The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder. The authors design multiple novel conditioning schemes and train SDXL on multiple aspect ratios and also introduce a refinement model that is used to improve the visual fidelity of samples generated by SDXL using a post-hoc image-to-image technique. The testing of SDXL shows drastically improved performance compared to the previous versions of Stable Diffusion and achieves results competitive with those of black-box state-of-the-art image generators.
In this tutorial, we consider how to run the SDXL model using OpenVINO.
We will use a pre-trained model from the Hugging Face Diffusers library. To simplify the user experience, the Hugging Face Optimum Intel library is used to convert the models to OpenVINO™ IR format.
The notebook provides a simple interface that allows communication with a model using text instruction. In this demonstration user can provide input instructions and the model generates an image.
The image below illustrates the provided user instruction and generated image example.

Note: Some demonstrated models can require at least 64GB RAM for conversion and running.
The tutorial consists of the following steps:
- Install prerequisites
- Download the Stable Diffusion XL Base model from a public source using the OpenVINO integration with Hugging Face Optimum.
- Run Text2Image generation pipeline using Stable Diffusion XL base
- Run Image2Image generation pipeline using Stable Diffusion XL base
- Download and convert the Stable Diffusion XL Refiner model from a public source using the OpenVINO integration with Hugging Face Optimum.
- Run 2-stages Stable Diffusion XL pipeline
If you have not installed all required dependencies, follow the Installation Guide.