本月在工作之余,参加了“京东杯2019第六届泰达创新创业挑战赛-用户对品类下店铺的购买预测”,半个多月的时间,最终成绩a榜第五,b榜第七,在这进行总结,把整个建模过程进行记录。
对于电商来说,好的用户画像一直是双赢地事,一方面能更好地为客户服务,带来更好地消费浏览体验,另一方面给平台带来更多地收益,包括用户停留时长以及转换为用户购买。而这个过程中,算法能有很多实际地应用场景。 该问题中,出题方提供了来自用户、商家、商品等多方面数据信息,包括商家和商品自身的内容信息、评论信息以及用户与之丰富的互动行为。我们需要通过数据挖掘技术和机器学习算法,构建用户购买商家中相关品类的预测模型,输出用户和店铺、品类的匹配结果,为精准营销提供高质量的目标群体。
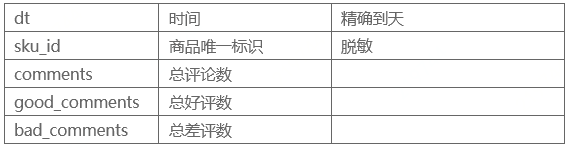
提供2018-02-01到2018-04-15用户集合U中的用户,对商品集合S中部分商品的行为、评价、用户数据。
提供 2018-04-16 到 2018-04-22 预测用户U对哪些品类和店铺有购买,用户对品类下的店铺只会购买一次。
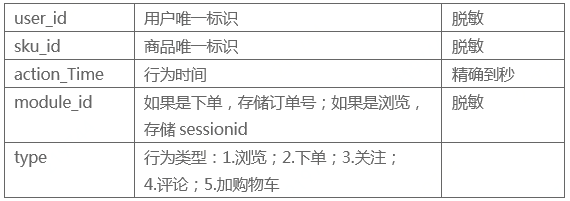
- 按照传统的比赛建模思路:数据清洗,构建样本,特征工程后使用LightGBM(Xgboost)树模下进行二分类预测。关键是样本+特征。
- 针对每一个用户,构建一条行为序列,采用序列建模思路。使用RNNs类方法。(学习门槛较高,希望这方面有理解和实际经验的同学指导下)

可以看到数据在2月波动比较大,因为在收到春节以及春节前的年货大促影响。之后二月底到三月之后数据开始稳定。 同时327和328两天,浏览数据出现异常,不知道具体缘由。在做特征的时候需要注意。
.png)
- 蓝色表示每天的产生下单的购买数。可以发现每天的数量是稳定的。(尽管略微下降)
- B040?表示那天有行为的用户的每天的下单样本数。可以发现的是存在大量的用户是缺少历史行为的。召回率存在上限。
.png)
- 当天产生行为后,未来会购买的概率随着时间递减。符合经验。
.png)
- 蓝色为4月8日行为用户的的未来七天下单分布。橘色和绿色分别表示为最后行为日期为4月7日和4月6日的用户在未来七天的下单分布。可以看到递减迅速。所以在本场景下最终预测时直接拿最后一天(0415)的样本进行预测就取得了最优的结果。
用户对用户行为的探讨,分为三类进行建模。
- 第一类用户,发现存在只有type==2操作行为的,这部分考虑通过规则来提取,最后汇入结果看收益,当前规则 最后七天存在两次购物行为。
- 第二类用户,有过加购物车行为的用户。在0408-0415时间段
- 第三类用户为总量用户除去前两类用户。
.png)
.png)
在建模过程中发现,第二类用户的购买转化率是最高的。只拿该部分建模可以进入前二十。第一类用户可以用规则覆盖(比如最近七天存在两次以及两次以上的购物行为等)。
- 从时间序列角度出发,该场景数据本平稳,但是受节假日影响早期存在波动。
- 数据缺失奇怪.怀疑 是主办方故意挖的坑。主要是两点。一是327,328两天浏览数据显著缺失异常。二是加入购物车行为只有408-415期间内存在。所以在数据选取时保守出发。
- 部分用户的行为,在其他表中找不到关联。该部分数据都认为脏数据处理。
- 用户-品类-最后行为时间-标签
- 日期-用户-商品sku-标签(商品 决定了 品类和标签)
- 日期-用户-品类-商店-标签
- 日期-用户-品类-标签 -> 用户-品类-商店-标签
- 前面都是按天构建样本,是否可以按照时间段构建样本,想到这一点的时候已经在比赛末期,试错成本较高,故放弃。
本次比赛最后选择 最直观的 日期-用户-品类-商店-标签 构建样本,并且在 该样本的基础上构建特征。该部分详情可以参考下一节的特征工程介绍。 其中对标签的定义是: 该用户在该日期的未来3天对该品类在该商店是否产生购买。 用4月8日到4月12日构建训练样本。 4月13日到4月15日构建测试样本。具体的生成逻辑为:
samples = jdata_action.groupby(['user_id','cate','shop_id','action_date'])\
.size().reset_index()[['user_id','cate','shop_id','action_date']]
# 获得样本 三天内有购买
def get_samples(dat,dat2):
sample = samples[samples.action_date==dat]
target = jdata_action[(jdata_action.type==2) & (jdata_action.action_date>dat)& (jdata_action.action_date<=dat2)].groupby(['user_id','cate','shop_id']).size().reset_index().rename(columns={0:'flag'})
sample = pd.merge(sample,target,on=['user_id','cate','shop_id'],how='left')
sample = sample.fillna(0)
sample['flag'] = sample.flag.map(lambda x: 1 if x>=1 else 0)
return sample样本构建在本场景中对效果影响非常的大。这里给出一些我对样本构建的思考。
- 样本的标签需要符合实际业务。这里是预测未来七天的购买情况。但真实构建样本过程中,我们不一定确定未来七天有购买的是正样本。我们可以灵活地选择,可以选择三天四天,甚至可以未来一天购买的才算正样本。 因为七天只是体现出一个购买意愿问题。
- 样本的粒度非常重要。比如该问题中需要解决的 用户-品类-商店-标签 对是基本的样本。但是实际构建过程中,我们可以训练 用户-商品-标签 对,然后自然而然地获得 用户-品类-商店-标签。 我们也可以做一个 用户-品类-标签 为样本的模型,然后再做 品类-商店-标签 为样本的模型,分层次构建样本以及建模。
- 不同层次的样本粒度,也会影响特征工程的构建。所以模型建立的过程都是一环扣一环,各关节息息相关的。
- 用户基础特征:用户注册年份,用户注册天数,年龄,性别,用户等级,城市等级,用户的地点(省份,城市,城镇)
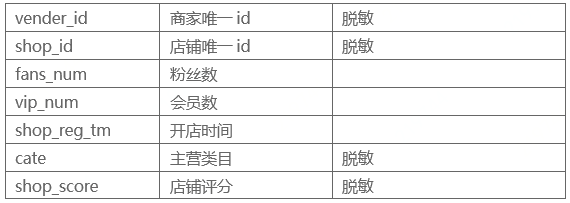
- 商店基础特征:粉丝数,会员数,商店评分,商店注册年份和天数
- 这里简单的应用了行为占比来统计转化率。并且认为加购物车,关注,评论等行为是购买意愿的体现,所以做了各行为的占比率视为转化率。从用户,品类,商品等粒度进行统计,并且交叉计算。 转化率计算脚本:为了更好地表示比例,进行了简单地平滑操作
# 获得历史上的单特征转化率数
def get_Conversion1_rate(self, date, cols, change_type):
tmp = self.jdata_action[self.jdata_action.action_date < date]
mean_rate = sum(tmp.type == change_type) * 1.0 / sum(tmp.type == 1)
data = pd.merge(
tmp[tmp.type == 1].groupby(cols).size().reset_index().rename(columns={0: cols + '_action1_counts'}), \
tmp[tmp.type == change_type].groupby(cols).size().reset_index().rename(
columns={0: cols + '_action2_counts'}), on=cols, how='left')
data = data.fillna(0)
data[cols + '_action1_counts'] = data[cols + '_action1_counts'].map(lambda x: x + 1000)
data[cols + '_action2_counts'] = data[cols + '_action2_counts'].map(lambda x: x + 1000 * mean_rate)
data[cols + '_' + str(change_type) + '_coversion_rate'] = data[cols + '_action2_counts'] * 1.0 / data[
cols + '_action1_counts']
return data[[cols, cols + '_' + str(change_type) + '_coversion_rate']]
# 获得历史上的交叉特征转化率
def get_Conversion2_rate(self,date, cols1, cols2, change_type):
tmp = self.jdata_action[self.jdata_action.action_date < date]
mean_rate = sum(tmp.type == change_type) * 1.0 / sum(tmp.type == 1)
data = pd.merge(tmp[tmp.type == 1].groupby([cols1, cols2]).size().reset_index().rename(
columns={0: cols1 + "_" + cols2 + '_action1_counts'}), \
tmp[tmp.type == change_type].groupby([cols1, cols2]).size().reset_index().rename(
columns={0: cols1 + "_" + cols2 + '_action2_counts'}), on=[cols1, cols2], how='left')
data = data.fillna(0)
data[cols1 + "_" + cols2 + '_action1_counts'] = data[cols1 + "_" + cols2 + '_action1_counts'].map(lambda x: x + 500)
data[cols1 + "_" + cols2 + '_action2_counts'] = data[cols1 + "_" + cols2 + '_action2_counts'].map(lambda x: x + 500 * mean_rate)
data[cols1 + "_" + cols2 + '_' + str(change_type) + '_coversion_rate'] = data[cols1 + "_" + cols2 + '_action2_counts'] * 1.0 / \
data[cols1 + "_" + cols2 + '_action1_counts']
return data[[cols1, cols2, cols1 + "_" + cols2 + '_' + str(change_type) + '_coversion_rate']]- 从用户,品类,商店三维度统计历史上(1,3,7,21天的行为统计特征)
- 对上诉三个维度进行交叉,用户-品类,用户-商店,品类-商店,用户-品类-商店 等维度构造历史行为统计特征。这些是最主要的特征(从效果和特征数上都是主要的,共有500多维的统计特征)
数量很多,举例说明: user_action1_skus_7day:用户在七天内浏览的商品(sku)数量 cate_action2_shops_7day:该品类七天内在几家商店被购买 user_cate_action5_counts_3day:用户三天内将该品类(cate)加入购物车的数量
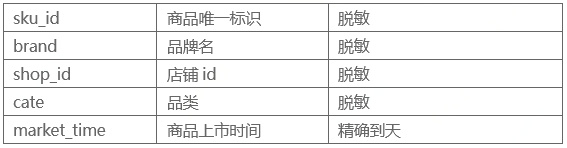
因为评论数据的粒度是sku,也就是商品,所以需要汇总到品类(cate)粒度或者商店(shop)粒度后使用,作为对品类的描述或者对该商店的描述。
- 该商店的评论数,好评数,差评数,好评率(平滑),差评率(平滑)
- 该品类的评论数,好评数,差评数,好评率(平滑),差评率(平滑)
- 该商店中该品类的评论数,好评数,差评数,好评率(平滑),差评率(平滑)
用来描述一些需要统计的店铺静态特征,比如:
- shop_cate_own_sku:该商店该品类下的商品数量。
- cate_own_skus:该品类下的商品数
- 该商店下的品类数,该品类被几家商店购买等。
时间特征不是样本时间,我只采用了一周的数据构建样本,所以没有加入日期进行刻画。 这里的时间特征是刻画行为频率的。主要通过天粒度的行为平均间隔,最短间隔以及间隔方差等来刻画。 以及用户某种行为,或者品类被行为的 最近时间,最远时间等。
用来刻画程度。 比如用户最喜欢逛的商店,某商店最热门的品类。 用户浏览的商店中,某家商店占比多少。 诸如此类。
参赛者提交的结果文件中包含对所有用户购买意向的预测结果。对每一个用户的预测结果包括两方面:
(1)该用户2018-04-16到2018-04-22是否对品类有购买,提交的结果文件中仅包含预测为下单的用户和品类(预测为未下单的用户和品类无须在结果中出现)。评测时将对提交结果中重复的“用户-品类”做排重处理,若预测正确,则评测算法中置label=1,不正确label=0。
(2)如果用户对品类有购买,还需要预测对该品类下哪个店铺有购买,若店铺预测正确,则评测算法中置pred=1,不正确pred=0。
对于参赛者提交的结果文件,按如下公式计算得分:score=0.4_F11_+0.6_F12_
此处的F1值定义为:

- 该评价指标是f1的变形。该类指标需要注意的是召回率和准确率的Trade-Off。
- 模型效果达到一定程度后,相对来说,高召回意味着低准确,高准确必然面临低召回。可以根据业务进行调整。比如想优惠更大群用户,就可以高召回下发放优惠券。
- 可以通过三次提交破解出 真实的样本数量,然后计算出每次提交的召回率和准确率。
具体破解如下:
- 提交版本1,数量为n,获得f1_score1
- 提交版本2,数量为m,获得f1_score2
- 需要注意,前两个版本没有交集,则合并两个提交版本组成新的版本3,数量为n+m,获得f1_socre3 这里我们获得了三个方程,然后可以求解出三个未知数:版本1正确数,版本2正确数,线上验证集总数 当然,破解方法不算建模本身,但是对评价指标进行更深入的理解是有必要的。
- 在建模过程中,发现不同用户之间的行为是不一样的。所以就面临一个决策:用特征来刻画用户,区分他们地行为, 还是根据行为不同先对用户群体进行分群,然后针对每个群体进行建模。 这里给出我的一点经验:那种显著区分的群体,就是各群体的其他特征有其明显分布特色的,当混在一起时分布容易打情况下,分群建模更加直观且易于理解,效果也不一定更差。当然不分群建模的话,在数据量上有天然的优势。
- 样本的定义非常重要? 如何构建合适的样本,有经验的同学可以在评论区给与下指导。
- 相同样本定义的情况下,特征工程决定了最终的效果。强特(类似规则)能抓住显著样本(高分段),大量的补充特征(弱特)通过模型能够挖掘出长尾特征。
- 切记!!时间序列问题的交叉验证防止穿越问题!!!
- LightGBM:https://lightgbm.readthedocs.io/en/latest/
- 比赛链接:https://jdata.jd.com/html/detail.html?id=8
- github代码文档:https://github.com/vinklibrary/jdata_code
- 数据链接: