Click-through rate (CTR) prediction is one of the fundamental tasks for online advertising and recommendation. Although a vanilla MLP is shown inefficient in learning high-order feature interactions, we found that a two-stream MLP model (DualMLP) that simply combines two well-tuned MLP networks can achieve surprisingly good performance. Based on this observation, we further propose feature selection and interaction aggregation layers that can be easily plugged in to build an enhanced two-stream MLP model, namely FinalMLP. We envision that the simple yet effective FinalMLP model could serve as a new strong baseline for future developments of two-stream CTR models.
Kelong Mao, Jieming Zhu, Liangcai Su, Guohao Cai, Yuru Li, Zhenhua Dong. FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction, in AAAI 2023.
Two-stream models (e.g., DeepFM, DCN) have been widely used for CTR prediction, where two streams are combined to capture complementarty feature interactions. FinalMLP is an enhanced two-stream MLP model that integrates stream-specific feature selection and stream-level interaction aggregation layers.
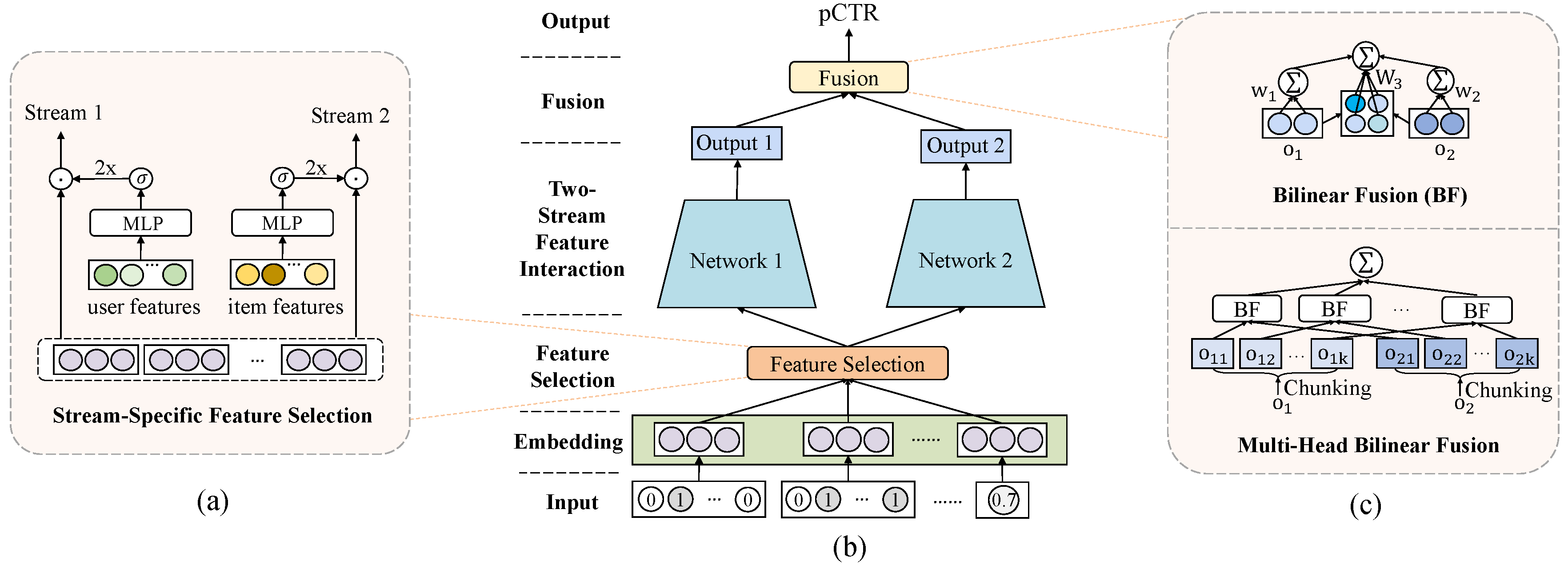
Key components:
-
Stream-specific feature gating: We perform feature gating from different views via conditioning on learnable parameters, user features, or item features, which produces global, user-specific, or item-specific feature importance weights, respectively.
$$\mathbf{g_1} = {Gate}_1(\mathbf{x_1}), ~~~ \mathbf{g_2} = {Gate}_2(\mathbf{x_2})$$ $$\mathbf{h_1} = 2\sigma (\mathbf{g_1})\odot \mathbf{e}, ~~~ \mathbf{h_2} = 2\sigma(\mathbf{g_2})\odot\mathbf{e}$$ -
Stream-level interaction aggregation: We propose an interaction aggregation layer to fuse the stream outputs with multi-head bilinear fusion.
$$BF(\mathbf{o}_1, \mathbf{o}_2) = b + \mathbf{w}_1^{T}\mathbf{o}_1 + \mathbf{w}_2^{T}\mathbf{o}_2 + \mathbf{o}_1^{T}\mathbf{W}_3\mathbf{o}_2$$ $$\hat{y} = \sigma(\sum_{j=1}^{k}{BF}(\mathbf{o_{1j}}, \mathbf{o_{2j}}))$$
We have tested FinalMLP with the following requirements.
python: 3.6/3.7
pytorch: 1.0/1.11
fuxictr: 2.0.1The dataset_config.yaml file contains all the dataset settings as follows.
| Params | Type | Default | Description |
|---|---|---|---|
| data_root | str | the root directory to load and save data data | |
| data_format | str | input data format, "h5", "csv", or "tfrecord" supported | |
| train_data | str | None | training data path |
| valid_data | str | None | validation data path |
| test_data | str | None | test data path |
| min_categr_count | int | 1 | min count to filter category features, |
| feature_cols | list | a list of features with the following dict keys | |
| feature_cols::name | str|list | feature column name in csv. A list is allowed in which the features have the same feature type and will be expanded accordingly. | |
| feature_cols::active | bool | whether to use the feature | |
| feature_cols::dtype | str | the input data dtype, "int"|"str" | |
| feature_cols::type | str | feature type "numeric"|"categorical"|"sequence"|"meta" | |
| label_col | dict | specify label column | |
| label_col::name | str | label column name in csv | |
| label_col::dtype | str | label data dtype |
The model_config.yaml file contains all the model hyper-parameters as follows.
| Params | Type | Default | Description |
|---|---|---|---|
| model | str | "FinalMLP" | model name, which should be same with model class name |
| dataset_id | str | "TBD" | dataset_id to be determined |
| loss | str | "binary_crossentropy" | loss function |
| metrics | list | ['logloss', 'AUC'] | a list of metrics for evaluation |
| task | str | "binary_classification" | task type supported: "regression", "binary_classification" |
| optimizer | str | "adam" | optimizer used for training |
| learning_rate | float | 1.0e-3 | learning rate |
| embedding_regularizer | float|str | 0 | regularization weight for embedding matrix: L2 regularization is applied by default. Other optional examples: "l2(1.e-3)", "l1(1.e-3)", "l1_l2(1.e-3, 1.e-3)". |
| net_regularizer | float|str | 0 | regularization weight for network parameters: L2 regularization is applied by default. Other optional examples: "l2(1.e-3)", "l1(1.e-3)", "l1_l2(1.e-3, 1.e-3)". |
| batch_size | int | 10000 | batch size, usually a large number for CTR prediction task |
| embedding_dim | int | 32 | embedding dimension of features. Note that field-wise embedding_dim can be specified in feature_specs. |
| mlp1_hidden_units | list | [64, 64, 64] | hidden units in MLP1 |
| mlp1_hidden_activations | str|list | "relu" | activation function in MLP1. Particularly, layer-wise activations can be specified as a list, e.g., ["relu", "leakyrelu", "sigmoid"] |
| mlp2_hidden_units | list | [64, 64, 64] | hidden units in MLP2 |
| mlp2_hidden_activations | str | "relu" | activation function in MLP2. Particularly, layer-wise activations can be specified as a list, e.g., ["relu", "leakyrelu", "sigmoid"] |
| mlp1_dropout | float | 0 | dropout rate in MLP1 |
| mlp2_dropout | float | 0 | dropout rate in MLP2 |
| mlp1_batch_norm | bool | False | whether using BN in MLP1 |
| mlp2_batch_norm | bool | False | whether using BN in MLP2 |
| use_fs | bool | True | whether using feature selection |
| fs_hidden_units | list | [64] | hidden units of fs gates |
| fs1_context | list | [] | conditional features for feature gating in stream 1 |
| fs2_context | list | [] | conditional features for feature gating in stream 2 |
| num_heads | int | 1 | number of heads used for bilinear fusion |
| epochs | int | 100 | the max number of epochs for training, which can early stop via monitor metrics. |
| shuffle | bool | True | whether shuffle the data samples for each epoch of training |
| seed | int | 2021 | the random seed used for reproducibility |
| monitor | str|dict | 'AUC' | the monitor metrics for early stopping. It supports a single metric, e.g., "AUC". It also supports multiple metrics using a dict, e.g., {"AUC": 2, "logloss": -1} means 2*AUC - logloss. |
| monitor_mode | str | 'max' | "max" means that the higher the better, while "min" denotes that the lower the better. |
| model_root | str | './checkpoints/' | the dir to save model checkpoints and running logs |
| early_stop_patience | int | 2 | training is stopped when monitor metric fails to become better for early_stop_patience=2consective evaluation intervals. |
| save_best_only | bool | True | whether to save the best model checkpoint only |
| eval_steps | int|None | None | evaluate the model on validation data every eval_steps. By default, None means evaluation every epoch. |
The evaluation results on AUC:
| Model | Criteo | Avazu | MovieLens | Frappe |
|---|---|---|---|---|
| DCN | 81.39 | 76.47 | 96.87 | 98.39 |
| AutoInt+ | 81.39 | 76.45 | 96.92 | 98.48 |
| AFN+ | 81.43 | 76.48 | 96.42 | 98.26 |
| MaskNet | 81.39 | 76.49 | 96.87 | 98.43 |
| DCNv2 | 81.42 | 76.54 | 96.91 | 98.45 |
| EDCN | 81.47 | 76.52 | 96.71 | 98.50 |
| DualMLP | 81.42 | 76.57 | 96.98 | 98.47 |
| FinalMLP | 81.49 | 76.66 | 97.20 | 98.61 |
For reproducing the results, please refer to https://github.com/reczoo/RecZoo/tree/main/ranking/ctr/FinalMLP