# Please use 'ms-swift>=2.2' or the main branch.
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'Model link:
- glm4v-9b-chat: https://modelscope.cn/models/ZhipuAI/glm-4v-9b/summary
Inference glm4v-9b-chat:
# Experimental environment: A100
# 30GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type glm4v-9b-chatOutput: (supports passing local path or URL)
"""
<<< Describe this image.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
This is an image of a close-up of a kitten's face. The kitten has a fluffy coat with a mix of grey, white, and brown patches. The fur appears soft and well-groomed, with a gradient of colors that gives the appearance of a watercolor painting. The kitten's ears are perky and pointed, with a light brown inner coloring that matches the fur on its face.
The kitten's eyes are the most striking feature of this image. They are large, round, and a vivid blue, with a hint of green at the edges. The irises are clear and bright, and the pupils are slightly dilated, giving the eyes a lively and attentive look. The white fur around the eyes is well-defined, with a few whisker tufts poking out from the corners.
The kitten's nose is small and pink, with a slightly upturned tip, which is common in many breeds. The whiskers are long and white, and they are spread out symmetrically around the nose and mouth area. The mouth is closed, and the kitten's expression is one of curiosity or alertness.
The background is blurred, with a soft focus on what appears to be a green surface, possibly a plant or a blurred background element that doesn't detract from the kitten's features. The lighting in the image is gentle, with a warm tone that enhances the softness of the kitten's fur and the sparkle in its eyes.
--------------------------------------------------
<<< clear
<<< How many sheep are in the picture?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
There are four sheep in the picture.
--------------------------------------------------
<<< clear
<<< What is the calculation result?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png
The calculation result of 1452 + 45304 is 46756.
--------------------------------------------------
<<< clear
<<< Write a poem based on the content of the picture.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png
In twilight's gentle descent, a boat drifts on glassy waves,
A lone figure stands, a sentinel, amidst the quiet maze.
The forest whispers through the trees, a symphony so serene,
As stars begin to twinkle, painting the sky with specks of meren.
The lantern's soft glow dances on the water's surface fair,
A beacon in the night, a promise of a haven near.
The boat, an ancient vessel, carries tales untold,
Of journeys past and futures bright, a silent witness to the fold.
The air is filled with mystery, the whispers of the wind,
As the boat glides through the night, a dream upon the tide.
The stars above, a celestial ballet, a dance of light and shade,
As the boat carries on its way, through the night, afloat and free.
"""Example images are shown below:
cat:

animal:

math:
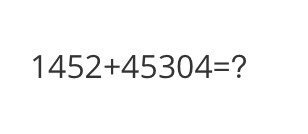
poem:

Single-sample inference
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.glm4v_9b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, _ = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which city is the farthest?'
images = images
gen = inference_stream(model, template, query, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, _ in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
"""
query: How far is it from each city?
response: The distance from each city to the next one is as follows:
1. From Mata to Yangjiang: 62 kilometers
2. From Yangjiang to Guangzhou: 293 kilometers
So, the total distance from Mata to Guangzhou is 62 kilometers (to Yangjiang) plus 293 kilometers (from Yangjiang to Guangzhou), which equals 355 kilometers.
query: Which city is the farthest?
response: The city that is the farthest away from the current location, as indicated on the road sign, is Guangzhou. It is 293 kilometers away.
"""Example image is shown below:
road:

Fine-tuning multimodal large models usually uses custom datasets. Here is a demo that can be run directly:
# Experimental environment: A100
# 40GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type glm4v-9b-chat \
--dataset coco-en-2-mini \
# DDP
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 swift sft \
--model_type glm4v-9b-chat \
--dataset coco-en-2-mini \
--ddp_find_unused_parameters true \Custom datasets support json, jsonl formats. Here is an example of a custom dataset:
(Supports multi-turn dialogue, but each conversation can only include one image. Support local file paths or URLs for input)
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response1"], ["query2", "response2"]], "images": ["image_path"]}Direct inference:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/glm4v-9b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \merge-lora and inference:
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/glm4v-9b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/glm4v-9b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true