

pyclustertend is a python package specialized in cluster tendency. Cluster tendency consist to assess if clustering algorithms are relevant for a dataset.
Three methods for assessing cluster tendency are currently implemented and one additional method based on metrics obtained with a KMeans estimator :
-
Hopkins Statistics
-
VAT
-
iVAT
-
Metric based method (silhouette, calinksi, davies bouldin)
pip install pyclustertend >>>from sklearn import datasets
>>>from pyclustertend import hopkins
>>>from sklearn.preprocessing import scale
>>>X = scale(datasets.load_iris().data)
>>>hopkins(X,150)
0.18950453452838564 >>>from sklearn import datasets
>>>from pyclustertend import vat
>>>from sklearn.preprocessing import scale
>>>X = scale(datasets.load_iris().data)
>>>vat(X)
>>>from sklearn import datasets
>>>from pyclustertend import ivat
>>>from sklearn.preprocessing import scale
>>>X = scale(datasets.load_iris().data)
>>>ivat(X)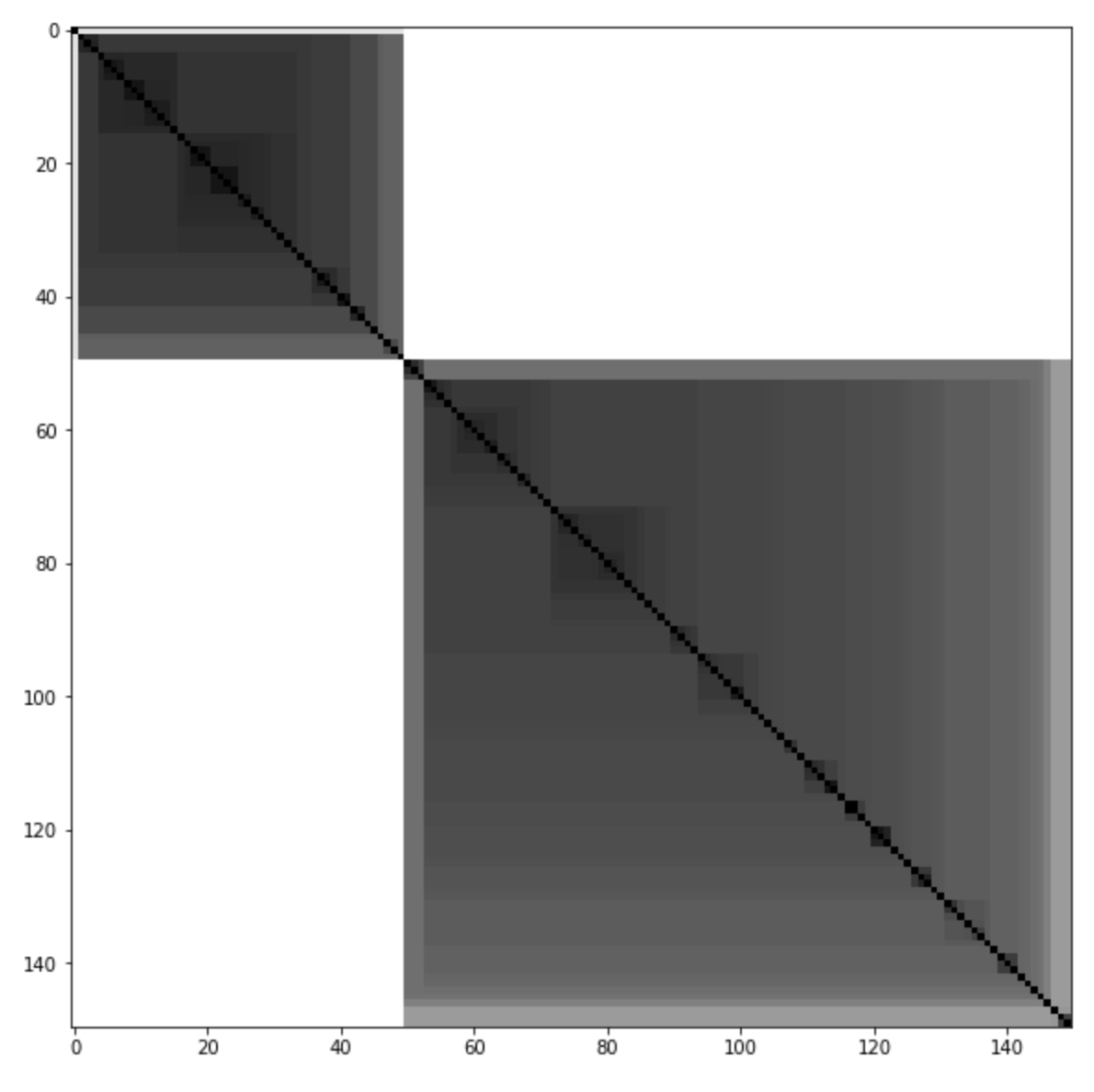
The main article used to develop this package is available here :
It's preferable to scale the data before using hopkins or vat algorithm as they use distance between observations. Moreover, vat and ivat algorithms do not really fit to massive databases. For the user, a first solution is to sample the data before using those algorithms. As for the maintainer of this implementation, it could be useful to represent the dissimalirity matrix in a smarter way to decrease the time complexity.