Normalization可理解为归一化、标准化或者规范化, 广泛应用于诸多领域. 整体来讲, Normalization扮演着对数据分布重新调整的角色. 在图像处理领域, 不同形式的归一化可以改变图像的灰度、对比度信息;在机器学习和神经网络中, Normalization可用于对数据去相关, 加速模型训练, 提高模型的泛化能力.
- Normalization(min-max)
- Standardization
- ZCA Whitening
- Global Contrast Normalization(GCN)
- Local Contrast Normalization(LCN)
- Local Response Normalization(LRN)
- Batch Normalization
- Layer Normalizaiton
- Instance Normalization https://github.com/DmitryUlyanov/texture_nets
- Group Normalization
- Switchable Normalization https://github.com/switchablenorms/Switchable-Normalization
深度神经网络模型训练之难众所周知, 其中一个重要的现象就是 Internal Covariate Shift. Batch Norm 大法自 2015 年由Google 提出之后, 就成为深度学习必备之神器. 自 BN 之后, Layer Norm / Weight Norm / Cosine Norm 等也横空出世.
归一化层, 目前主要有这几个方法, Batch Normalization(2015年)、Layer Normalization(2016年)、Instance Normalization(2017年)、Group Normalization(2018年)、Switchable Normalization(2018年)
将输入的图像shape记为[N, C, H, W], 这几个方法主要的区别就是在,
- batchNorm是在batch上, 对NHW做归一化, 对小batchsize效果不好;
- layerNorm在通道方向上, 对CHW归一化, 主要对RNN作用明显;
- instanceNorm在图像像素上, 对HW做归一化, 用在风格化迁移;
- GroupNorm将channel分组, 然后再做归一化;
- SwitchableNorm是将BN、LN、IN结合, 赋予权重, 让网络自己去学习归一化层应该使用什么方法.

BatchNorm:batch方向做归一化,
算N*H*W的均值LayerNorm:channel方向做归一化, 算
C*H*W的均值InstanceNorm:一个channel内做归一化, 算
H*W的均值GroupNorm:将channel方向分group, 然后每个group内做归一化, 算
(C//G)*H*W的均值从左到右是BN, LN, IN, GN.
众所周知, 深度网络中的数据维度一般是[N, C, H, W]或者[N, H, W, C]格式, N是batch size, H/W是feature的高/宽, C是feature的channel, 压缩H/W至一个维度, 其三维的表示如上图, 假设单个方格的长度是1, 那么其表示的是[6, 6, *, * ]
要注意这里的channel不能单纯的理解为图形的RGB,对于卷积后的图像的特征图,也有所谓channel的概念,就是feature map的层数.所以可以不止三层.

尽管随机梯度下降法对于训练深度网络简单高效, 但是它有个毛病, 就是需要我们人为的去选择参数, 比如学习率、参数初始化、权重衰减系数、Dropout比例等. 这些参数的选择对训练结果至关重要, 以至于我们很多时间都浪费在这些的调参上. 那么学完这篇文献之后, 你可以不需要那么刻意的慢慢调整参数. BN算法(Batch Normalization)其强大之处如下:
-
你可以选择比较大的初始学习率, 让你的训练速度飙涨. 以前还需要慢慢调整学习率, 甚至在网络训练到一半的时候, 还需要想着学习率进一步调小的比例选择多少比较合适, 现在我们可以采用初始很大的学习率, 然后学习率的衰减速度也很大, 因为这个算法收敛很快. 当然这个算法即使你选择了较小的学习率, 也比以前的收敛速度快, 因为它具有快速训练收敛的特性;
-
你再也不用去理会过拟合中dropout、L2正则项参数的选择问题, 采用BN算法后, 你可以移除这两项了参数, 或者可以选择更小的L2正则约束参数了, 因为BN具有提高网络泛化能力的特性;
-
再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法, 搞视觉的估计比较熟悉), 因为BN本身就是一个归一化网络层;
-
可以把训练数据彻底打乱(防止每批训练的时候, 某一个样本都经常被挑选到, 文献说这个可以提高1%的精度, 这句话我也是百思不得其解啊).
开始讲解算法前, 先来思考一个问题:我们知道在神经网络训练开始前, 都要对输入数据做一个归一化处理, 那么具体为什么需要归一化呢?归一化后有什么好处呢?
原因在于神经网络学习过程本质就是为了学习数据分布, 一旦训练数据与测试数据的分布不同, 那么网络的泛化能力也大大降低;另外一方面, 一旦每批训练数据的分布各不相同(batch 梯度下降), 那么网络就要在每次迭代都去学习适应不同的分布, 这样将会大大降低网络的训练速度, 这也正是为什么我们需要对数据都要做一个归一化预处理的原因.
对于深度网络的训练是一个复杂的过程, 只要网络的前面几层发生微小的改变, 那么后面几层就会被累积放大下去. 一旦网络某一层的输入数据的分布发生改变, 那么这一层网络就需要去适应学习这个新的数据分布, 所以如果训练过程中, 训练数据的分布一直在发生变化, 那么将会影响网络的训练速度.
我们知道网络一旦train起来, 那么参数就要发生更新, 除了输入层的数据外(因为输入层数据, 我们已经人为的为每个样本归一化), 后面网络每一层的输入数据分布是一直在发生变化的, 因为在训练的时候, 前面层训练参数的更新将导致后面层输入数据分布的变化.
以网络第二层为例:网络的第二层输入, 是由第一层的参数和input计算得到的, 而第一层的参数在整个训练过程中一直在变化, 因此必然会引起后面每一层输入数据分布的改变.
我们把网络中间层在训练过程中, 数据分布的改变称之为:“Internal Covariate Shift”.
Paper所提出的算法, 就是要解决在训练过程中, 中间层数据分布发生改变的情况.
就像激活函数层、卷积层、全连接层、池化层一样, BN(Batch Normalization)也属于网络的一层. 在前面我们提到网络除了输出层外, 其它层因为低层网络在训练的时候更新了参数, 而引起后面层输入数据分布的变化. 这个时候我们可能就会想, 如果在每一层输入的时候, 再加个预处理操作那该有多好啊, 比如网络第三层输入数据X3(X3表示网络第三层的输入数据)把它归一化至:均值0、方差为1, 然后再输入第三层计算, 这样我们就可以解决前面所提到的“Internal Covariate Shift”的问题了.
所以batch normalization就是强行将数据拉回到均值为0, 方差为1的正太分布上, 这样不仅数据分布一致, 而且避免发生梯度消失.
此外, internal corvariate shift和covariate shift是两回事, 前者是网络内部, 后者是针对输入数据, 比如我们在训练数据前做归一化等预处理操作.
而事实上, paper的算法本质原理就是这样:在网络的每一层输入的时候, 又插入了一个归一化层, 也就是先做一个归一化处理, 然后再进入网络的下一层. 不过文献归一化层, 可不像我们想象的那么简单, 它是一个可学习、有参数的网络层.
既然说到数据预处理, 下面就先来复习一下最强的预处理方法:白化.
说到神经网络输入数据预处理, 最好的算法莫过于白化预处理.
然而白化计算量太大了, 很不划算, 还有就是白化不是处处可微的, 所以在深度学习中, 其实很少用到白化.
经过白化预处理后, 数据满足条件:
- 特征之间的相关性降低, 这个就相当于pca;
- 数据均值、标准差归一化, 也就是使得每一维特征均值为0, 标准差为1.
如果数据特征维数比较大, 要进行PCA, 也就是实现白化的第1个要求, 是需要计算特征向量, 计算量非常大, 于是为了简化计算, 作者忽略了第1个要求, 仅仅使用了下面的公式进行预处理, 也就是近似白化预处理:
需要注意的是, 我们训练过程中采用batch 随机梯度下降, 上面的$E(x^{(k)})$指的是每一批训练数据神经元$x^{(k)}$的平均值;然后分母就是每一批数据神经元$x^{(k)}$激活度的一个标准差了.

其实如果是仅仅使用上面的归一化公式, 对网络某一层A的输出数据做归一化, 然后送入网络下一层B, 这样是会影响到本层网络A所学习到的特征的.
打个比方, 比如我网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧, 你强制把它给我归一化处理、标准差也限制在了1, 把数据变换成分布于s函数的中间部分, 这样就相当于我这一层网络所学习到的特征分布被你搞坏了, 这可怎么办?于是文献使出了一招惊天地泣鬼神的招式:变换重构, 引入了可学习参数γ、β, 这就是算法关键之处:

每一个神经元$x^{(k)}$都会有一对这样的参数γ、β.
这样其实当:

是可以恢复出原始的某一层所学到的特征的. 因此我们引入了这个可学习重构参数γ、β, 让我们的网络可以学习恢复出原始网络所要学习的特征分布.
最后Batch Normalization网络层的前向传导过程公式就是:(公式中m指的是mini-batch size)

- 沿着通道计算每个batch的均值$u$
- 沿着通道计算每个batch的方差$σ^2$
- 对$x$做归一化,
$x’=(x-u)/\sqrt{(σ^2+ε)}$ - 加入缩放和平移变量$γ$和$β$ ,归一化后的值,
$y=γx’+β$
加入缩放平移变量的原因是:
保证每一次数据经过归一化后还保留原有学习来的特征, 同时又能完成归一化操作, 加速训练.
这两个参数是用来学习的参数.
通过上面的学习, 我们知道BN层是对于每个神经元做归一化处理, 甚至只需要对某一个神经元进行归一化, 而不是对一整层网络的神经元进行归一化.
既然BN是对单个神经元的运算, 那么在CNN中卷积层上要怎么搞?假如某一层卷积层有6个特征图, 每个特征图的大小是100×100, 这样就相当于这一层网络有6×100×100个神经元(特征), 如果采用BN, 就会有6×100×100个参数γ、β, 这样岂不是太恐怖了.
因此卷积层上的BN使用, 其实也是使用了类似权值共享的策略, 把一整张特征图当做一个神经元进行处理.
卷积神经网络经过卷积后得到的是一系列的特征图, 如果min-batch sizes为m, 那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q), m为min-batch sizes, f为特征图个数, p、q分别为特征图的宽高.
在cnn中我们可以把每个特征图看成是一个特征处理(一个神经元), 因此在使用Batch Normalization, mini-batch size 的大小就是:m×p×q, 于是对于每个特征图都只有一对可学习参数:γ、β. 说白了吧, 这就是相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差, 然后对这个特征图神经元做归一化.
下面是来自于keras卷积层的BN实现一小段主要源码:
input_shape = self.input_shape
reduction_axes = list(range(len(input_shape)))
del reduction_axes[self.axis]
broadcast_shape = [1] * len(input_shape)
broadcast_shape[self.axis] = input_shape[self.axis]
if train:
# 计算均值
m = K.mean(X, axis=reduction_axes)
brodcast_m = K.reshape(m, broadcast_shape)
# 计算标准差(这之中使用了参数epsilon
std = K.mean(K.square(X - brodcast_m) + self.epsilon, axis=reduction_axes)
std = K.sqrt(std)
brodcast_std = K.reshape(std, broadcast_shape)
# 动量方式滑动更新策略
mean_update = self.momentum * self.running_mean + (1-self.momentum) * m
std_update = self.momentum * self.running_std + (1-self.momentum) * std
self.updates = [(self.running_mean, mean_update),
(self.running_std, std_update)]
# 计算归一化值
X_normed = (X - brodcast_m) / (brodcast_std + self.epsilon)
else:
# 可以认为是测试阶段
brodcast_m = K.reshape(self.running_mean, broadcast_shape)
brodcast_std = K.reshape(self.running_std, broadcast_shape)
X_normed = ((X - brodcast_m) / (brodcast_std + self.epsilon))
out = K.reshape(self.gamma, broadcast_shape) * X_normed + K.reshape(self.beta, broadcast_shape)可能学完了上面的算法, 你只是知道它的一个训练过程, 一个网络一旦训练完了, 就没有了min-batch这个概念了.
测试阶段我们一般只输入一个测试样本, 看看结果而已. 因此测试样本, 前向传导的时候, 上面的均值u、标准差σ 要哪里来?其实网络一旦训练完毕, 参数都是固定的, 这个时候即使是每批训练样本进入网络, 那么BN层计算的均值u、和标准差都是固定不变的. 我们可以采用这些数值来作为测试样本所需要的均值、标准差, 于是最后测试阶段的u和σ 计算公式如下:

上面简单理解就是:对于均值来说直接计算所有batch

x_normed = (x - bn_param['running_mean']) / np.sqrt(bn_param['running_var'] + eps)
# 变换重构
out = gamma * x_normed + beta
# 实际上这里就是一个直接的求解归一化后变换重构根据文献说, BN可以应用于一个神经网络的任何神经元上. 文献主要是把BN变换, 置于网络激活函数层的前面. 在没有采用BN的时候, 激活函数层是这样的:$z=g(Wu+b)$
也就是我们希望一个激活函数, 比如s型函数s(x)的自变量x是经过BN处理后的结果. 因此前向传导的计算公式就应该是:$ z=g(BN(Wu+b)) $
其实因为偏置参数b经过BN层后其实是没有用的, 最后也会被均值归一化, 当然BN层后面还有个β参数作为偏置项, 所以b这个参数就可以不用了. 因此最后把BN层+激活函数层就变成了:$z=g(BN(Wu))$


相关的代码:
x, gamma, beta, x_normed, sample_mean, sample_var, eps = cache
# 罗列计算
# dout实际上就是dl/dy
# 对于beta, gamma求导, 实际上是一个特征有一个beta, gamma, 这导致求导是多个分支相加
dbeta = np.sum(dout, axis=0)
dgamma = np.sum(dout * x_normed, axis=0)
# 先计算出对归一化的x偏导
dx_normed = dout * gamma.reshape([1, -1])
# dy/dx有三条路径, 一条是对归一化公式里的x, 另外就是对均值里的和标准差里的x
# dl/dvar
dvar = -0.5 * np.sum(dx_normed * (x - sample_mean), axis=0) * \
((sample_var + eps)**(-1.5))
# dl/dmean
dmean = -np.sum(dx_normed / np.sqrt(sample_var + eps), axis=0) \
- 2 * dvar / x.shape[0] * np.sum(x - sample_mean, axis=0)
# dl/dx
dx = dx_normed / np.sqrt(sample_var + eps) + 2 * dvar * (x - sample_mean) / \
x.shape[0] + dmean / x.shape[0]
batch normalization存在以下缺点:
- 对batchsize的大小比较敏感, 由于每次计算均值和方差是在一个batch上, 所以如果batchsize太小, 则计算的均值、方差不足以代表整个数据分布;
- BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息, 对于对一个固定深度的前向神经网络(DNN, CNN)使用BN, 很方便;但对于RNN来说, sequence的长度是不一致的, 换句话说RNN的深度不是固定的, 不同的time-step需要保存不同的statics特征, 可能存在一个特殊sequence比其他sequence长很多, 这样training时, 计算很麻烦. (参考于https://blog.csdn.net/lqfarmer/article/details/71439314)

与BN不同, LN是针对深度网络的某一层的所有神经元的输入按以下公式进行 normalize 操作.

where H denotes the number of hidden units in a layer
-
LN中同层神经元输入拥有相同的均值和方差, 不同的输入样本有不同的均值和方差;
-
BN中则针对不同神经元输入计算均值和方差, 同一个batch中的输入拥有相同的均值和方差.
所以, LN不依赖于batch的大小和输入sequence的深度, 因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作.
LN用于RNN效果比较明显, 但是在CNN上, 不如BN.
def ln(x, b, s):
_eps = 1e-5
output = (x - x.mean(1)[:,None]) / tensor.sqrt((x.var(1)[:,None] + _eps))
output = s[None, :] * output + b[None,:]
return output用在四维图像上,
def Layernorm(x, gamma, beta):
# x_shape:[B, C, H, W]
results = 0.
eps = 1e-5
x_mean = np.mean(x, axis=(1, 2, 3), keepdims=True)
x_var = np.var(x, axis=(1, 2, 3), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
return resultsBN注重对每个batch进行归一化, 保证数据分布一致, 因为判别模型中结果取决于数据整体分布.
但是图像风格化中, 生成结果主要依赖于某个图像实例, 所以对整个batch归一化不适合图像风格化中, 因而对HW做归一化. 可以加速模型收敛, 并且保持每个图像实例之间的独立.

def Instancenorm(x, gamma, beta):
# x_shape:[B, C, H, W]
results = 0.
eps = 1e-5
x_mean = np.mean(x, axis=(2, 3), keepdims=True)
x_var = np.var(x, axis=(2, 3), keepdims=True)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
return results主要是针对Batch Normalization对小batchsize效果差, GN将channel方向分group, 然后每个group内做归一化, 算(C//G)×H×W的均值, 这样与batchsize无关, 不受其约束.


def GroupNorm(x, gamma, beta, G=16):
# x_shape:[B, C, H, W]
results = 0.
eps = 1e-5
x = np.reshape(x, (x.shape[0], G, x.shape[1]/16, x.shape[2], x.shape[3]))
x_mean = np.mean(x, axis=(2, 3, 4), keepdims=True)
x_var = np.var(x, axis=(2, 3, 4), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
return results本篇论文作者认为,
- 第一, 归一化虽然提高模型泛化能力, 然而归一化层的操作是人工设计的. 在实际应用中, 解决不同的问题原则上需要设计不同的归一化操作, 并没有一个通用的归一化方法能够解决所有应用问题;
- 第二, 一个深度神经网络往往包含几十个归一化层, 通常这些归一化层都使用同样的归一化操作, 因为手工为每一个归一化层设计操作需要进行大量的实验.
因此作者提出**自适配归一化方法——Switchable Normalization(SN)**来解决上述问题. 与强化学习不同, SN使用可微分学习, 为一个深度网络中的每一个归一化层确定合适的归一化操作.



def SwitchableNorm(x, gamma, beta, w_mean, w_var):
# x_shape:[B, C, H, W]
results = 0.
eps = 1e-5
mean_in = np.mean(x, axis=(2, 3), keepdims=True)
var_in = np.var(x, axis=(2, 3), keepdims=True)
mean_ln = np.mean(x, axis=(1, 2, 3), keepdims=True)
var_ln = np.var(x, axis=(1, 2, 3), keepdims=True)
mean_bn = np.mean(x, axis=(0, 2, 3), keepdims=True)
var_bn = np.var(x, axis=(0, 2, 3), keepdims=True)
mean = w_mean[0] * mean_in + w_mean[1] * mean_ln + w_mean[2] * mean_bn
var = w_var[0] * var_in + w_var[1] * var_ln + w_var[2] * var_bn
x_normalized = (x - mean) / np.sqrt(var + eps)
results = gamma * x_normalized + beta
return results

-
为什么需要 Normalization
——深度学习中的 Internal Covariate Shift 问题及其影响
-
Normalization 的通用框架与基本思想
——从主流 Normalization 方法中提炼出的抽象框架
-
主流 Normalization 方法梳理
——结合上述框架, 将 BatchNorm / LayerNorm / WeightNorm / CosineNorm 对号入座, 各种方法之间的异同水落石出.
-
Normalization 为什么会有效?
——从参数和数据的伸缩不变性探讨Normalization有效的深层原因.
机器学习界的炼丹师们最喜欢的数据有什么特点?窃以为, 莫过于“独立同分布”了, 即independent and identically distributed, 简称为 i.i.d.
独立同分布并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上, 而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好的模型),但独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力, 已经是一个共识.
因此, 在把数据喂给机器学习模型之前, “白化(whitening)”是一个重要的数据预处理步骤. 白化一般包含两个目的:
- 去除特征之间的相关性 —> 独立;
- 使得所有特征具有相同的均值和方差 —> 同分布.
白化最典型的方法就是PCA, 可以参考阅读 PCAWhitening.
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是, 深度神经网络涉及到很多层的叠加, 而每一层的参数更新会导致上层的输入数据分布发生变化, 通过层层叠加, 高层的输入分布变化会非常剧烈, 这就使得高层需要不断去重新适应底层的参数更新. 为了训好模型, 我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略.
Google 将这一现象总结为 Internal Covariate Shift, 简称 ICS. 什么是 ICS 呢?@魏秀参在一个回答中做出了一个很好的解释:
大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”. 如果不一致, 那么就出现了新的机器学习问题, 如 transfer learning / domain adaptation 等. 而 covariate shift 就是分布不一致假设之下的一个分支问题, 它是指源空间和目标空间的条件概率是一致的, 但是其边缘概率不同, 即:对所有
,
但是
大家细想便会发现, 的确, 对于神经网络的各层输出, 由于它们经过了层内操作作用, 其分布显然与各层对应的输入信号分布不同, 而且差异会随着网络深度增大而增大, 可是它们所能“指示”的样本标记(label)仍然是不变的, 这便符合了covariate shift的定义. 由于是对层间信号的分析, 也即是“internal”的来由.
简而言之, 每个神经元的输入数据不再是“独立同分布”.
其一, 上层参数需要不断适应新的输入数据分布, 降低学习速度.
其二, 下层输入的变化可能趋向于变大或者变小, 导致上层落入饱和区, 使得学习过早停止.
其三, 每层的更新都会影响到其它层, 因此每层的参数更新策略需要尽可能的谨慎.
我们以神经网络中的一个普通神经元为例. 神经元接收一组输入向量
通过某种运算后, 输出一个标量值:
由于 ICS 问题的存在 的分布可能相差很大. 要解决独立同分布的问题, “理论正确”的方法就是对每一层的数据都进行白化操作. 然而标准的白化操作代价高昂, 特别是我们还希望白化操作是可微的, 保证白化操作可以通过反向传播来更新梯度.
因此, 以 BN 为代表的 Normalization 方法退而求其次, 进行了简化的白化操作. 基本思想是:在将 送给神经元之前, 先对其做平移和伸缩变换, 将
的分布规范化成在固定区间范围的标准分布.
通用变换框架就如下所示:
我们来看看这个公式中的各个参数.
-
是平移参数(shift parameter),
是缩放参数(scale parameter). 通过这两个参数进行 shift 和 scale 变换:
得到的数据符合均值为 0、方差为 1 的标准分布.
-
是再平移参数(re-shift parameter),
是再缩放参数(re-scale parameter). 将 上一步得到的
进一步变换为:
最终得到的数据符合均值为 、方差为
的分布.
第一步都已经得到了标准分布, 第二步怎么又给变走了?
答案是——为了保证模型的表达能力不因为规范化而下降.
我们可以看到, 第一步的变换将输入数据限制到了一个全局统一的确定范围(均值为 0、方差为 1). 下层神经元可能很努力地在学习, 但不论其如何变化, 其输出的结果在交给上层神经元进行处理之前, 将被粗暴地重新调整到这一固定范围.
为了尊重底层神经网络的学习结果, 我们将规范化后的数据进行再平移和再缩放, 使得每个神经元对应的输入范围是针对该神经元量身定制的一个确定范围(均值为 、方差为
). rescale 和 reshift 的参数都是可学习的, 这就使得 Normalization 层可以学习如何去尊重底层的学习结果.
除了充分利用底层学习的能力, 另一方面的重要意义在于保证获得非线性的表达能力. Sigmoid 等激活函数在神经网络中有着重要作用, 通过区分饱和区和非饱和区, 使得神经网络的数据变换具有了非线性计算能力. 而第一步的规范化会将几乎所有数据映射到激活函数的非饱和区(线性区), 仅利用到了线性变化能力, 从而降低了神经网络的表达能力. 而进行再变换, 则可以将数据从线性区变换到非线性区, 恢复模型的表达能力.
那么问题又来了——
经过这么的变回来再变过去, 会不会跟没变一样?
不会. 因为, 再变换引入的两个新参数 g 和 b, 可以表示旧参数作为输入的同一族函数, 但是新参数有不同的学习动态. 在旧参数中, 的均值取决于下层神经网络的复杂关联;但在新参数中,
仅由
来确定, 去除了与下层计算的密切耦合. 新参数很容易通过梯度下降来学习, 简化了神经网络的训练.
那么还有一个问题——
这样的 Normalization 离标准的白化还有多远?
标准白化操作的目的是“独立同分布”. 独立就不说了, 暂不考虑. 变换为均值为 、方差为
的分布, 也并不是严格的同分布, 只是映射到了一个确定的区间范围而已. (所以, 这个坑还有得研究呢!)
在上一节中, 我们提炼了 Normalization 的通用公式:
对照于这一公式, 我们来梳理主流的四种规范化方法.
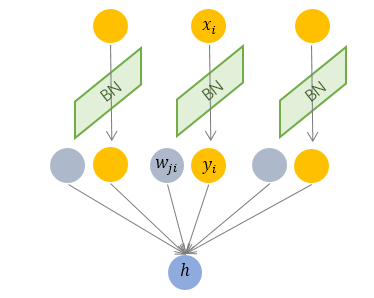
Batch Normalization 于2015年由 Google 提出, 开 Normalization 之先河. 其规范化针对单个神经元进行, 利用网络训练时一个 mini-batch 的数据来计算该神经元 的均值和方差, 因而称为 Batch Normalization.
其中 是 mini-batch 的大小.
按上图所示, 相对于一层神经元的水平排列, BN 可以看做一种纵向的规范化. 由于 BN 是针对单个维度定义的, 因此标准公式中的计算均为 element-wise 的.
BN 独立地规范化每一个输入维度 , 但规范化的参数是一个 mini-batch 的一阶统计量和二阶统计量. 这就要求 每一个 mini-batch 的统计量是整体统计量的近似估计, 或者说每一个 mini-batch 彼此之间, 以及和整体数据, 都应该是近似同分布的. 分布差距较小的 mini-batch 可以看做是为规范化操作和模型训练引入了噪声, 可以增加模型的鲁棒性;但如果每个 mini-batch的原始分布差别很大, 那么不同 mini-batch 的数据将会进行不一样的数据变换, 这就增加了模型训练的难度.
因此, BN 比较适用的场景是:每个 mini-batch 比较大, 数据分布比较接近. 在进行训练之前, 要做好充分的 shuffle. 否则效果会差很多.
另外, 由于 BN 需要在运行过程中统计每个 mini-batch 的一阶统计量和二阶统计量, 因此不适用于动态的网络结构 和 RNN 网络. 不过, 也有研究者专门提出了适用于 RNN 的 BN 使用方法, 这里先不展开了.
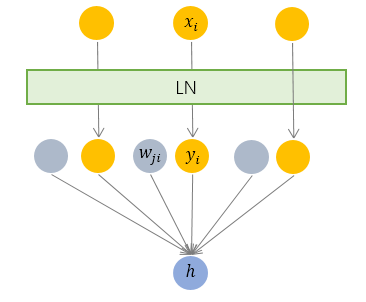
层规范化就是针对 BN 的上述不足而提出的. 与 BN 不同, LN 是一种横向的规范化, 如图所示. 它综合考虑一层所有维度的输入, 计算该层的平均输入值和输入方差, 然后用同一个规范化操作来转换各个维度的输入.
可以近似理解为对于输入的各个特征维度的整体均值方差来计算处理归一化
其中 枚举了该层所有的输入神经元. 对应到标准公式中, 四大参数
,
,
,
均为标量(BN中是向量), 所有输入共享一个规范化变换.
LN 针对单个训练样本进行, 不依赖于其他数据, 因此可以避免 BN 中受 mini-batch 数据分布影响的问题, 可以用于 小mini-batch场景、动态网络场景和 RNN, 特别是自然语言处理领域. 此外, LN 不需要保存 mini-batch 的均值和方差, 节省了额外的存储空间.
但是, BN 的转换是针对单个神经元可训练的——不同神经元的输入经过再平移和再缩放后分布在不同的区间, 而 LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内. 如果不同输入特征不属于相似的类别(比如颜色和大小), 那么 LN 的处理可能会降低模型的表达能力.
前面我们讲的模型框架
经过规范化之后的 作为输入送到下一个神经元, 应用以
为参数的
函数定义的变换. 最普遍的变换是线性变换, 即
.
BN 和 LN 均将规范化应用于输入的特征数据 , 而 WN 则另辟蹊径, 将规范化应用于线性变换函数的权重
, 这就是 WN 名称的来源.
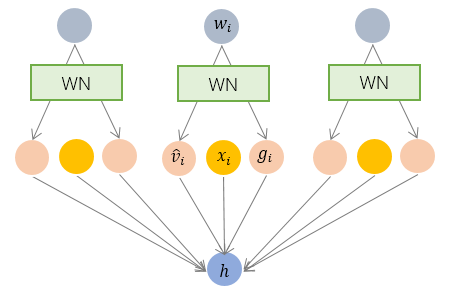
具体而言, WN 提出的方案是, 将权重向量 分解为向量方向
和向量模
两部分:
其中 是与
同维度的向量,
是欧氏范数, 因此
是单位向量, 决定了
的方向;
是标量, 决定了
的长度. 由于
, 因此这一权重分解的方式将权重向量的欧氏范数进行了固定, 从而实现了正则化的效果.
乍一看, 这一方法似乎脱离了我们前文所讲的通用框架?
并没有. 其实从最终实现的效果来看, 异曲同工. 我们来推导一下看.
对照一下前述框架:
我们只需令:
就完美地对号入座了!
回忆一下, BN 和 LN 是用输入的特征数据的方差对输入数据进行 scale, 而 WN 则是用神经元的权重的欧氏范式对输入数据进行 scale. **虽然在原始方法中分别进行的是特征数据规范化和参数的规范化, 但本质上都实现了对数据的规范化, 只是用于 scale 的参数来源不同. **
另外, 我们看到这里的规范化只是对数据进行了 scale, 而没有进行 shift, 因为我们简单地令 . 但事实上, 这里留下了与 BN 或者 LN 相结合的余地——那就是利用 BN 或者 LN 的方法来计算输入数据的均值
.
如何结合计算?难道说可以让$\mu \neq 0$?这里的意思应该是指, 前面利用BN或者LN来计算shift操作, 而利用WN实现scale操作. (平移, 放缩)
WN 的规范化不直接使用输入数据的统计量, 因此避免了 BN 过于依赖 mini-batch 的不足, 以及 LN 每层唯一转换器的限制, 同时也可以用于动态网络结构.
Normalization 还能怎么做?
我们再来看看神经元的经典变换.
对输入数据 的变换已经做过了, 横着来是 LN, 纵着来是 BN.
对模型参数 的变换也已经做过了, 就是 WN.
好像没啥可做的了.
然而天才的研究员们盯上了中间的那个点, 对, 就是****. 他们说, 我们要对数据进行规范化的原因, 是数据经过神经网络的计算之后可能会变得很大, 导致数据分布的方差爆炸, 而这一问题的根源就是我们的计算方式——点积, 权重向量
和 特征数据向量
的点积. 向量点积是无界(unbounded)的啊!
那怎么办呢?我们知道向量点积是衡量两个向量相似度的方法之一. 哪还有没有其他的相似度衡量方法呢?有啊, 很多啊!夹角余弦就是其中之一啊!而且关键的是, 夹角余弦是有确定界的啊, [-1, 1] 的取值范围, 多么的美好!仿佛看到了新的世界!
于是, Cosine Normalization 就出世了. 他们不处理权重向量 , 也不处理特征数据向量
, 就改了一下线性变换的函数:
其中 是
和
的夹角. 然后就没有然后了, 所有的数据就都是 [-1, 1] 区间范围之内的了!
不过, 回过头来看, CN 与 WN 还是很相似的. 我们看到上式中, 分子还是 和
的内积, 而分母则可以看做用
和
二者的模之积进行规范化. 对比一下 WN 的公式:
一定程度上可以理解为, WN 用 权重的模 对输入向量进行 scale, 而 CN 在此基础上用输入向量的模
对输入向量进行了进一步的 scale.
CN 通过用余弦计算代替内积计算实现了规范化, 但成也萧何败萧何. 原始的内积计算, 其几何意义是 输入向量在权重向量上的投影, 既包含 二者的夹角信息, 也包含 两个向量的scale信息. 去掉scale信息, 可能导致表达能力的下降, 因此也引起了一些争议和讨论. 具体效果如何, 可能需要在特定的场景下深入实验.
我们以下面这个简化的神经网络为例来分析.
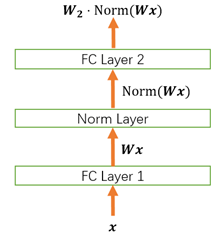
**权重伸缩不变性(weight scale invariance)**指的是, 当权重 按照常量
进行伸缩时, 得到的规范化后的值保持不变, 即:
其中 .
上述规范化方法均有这一性质, 这是因为, 当权重 伸缩时, 对应的均值和标准差均等比例伸缩, 分子分母相抵.
权重伸缩不变性可以有效地提高反向传播的效率.
由于
因此, 权重的伸缩变化不会影响反向梯度的 Jacobian 矩阵, 因此也就对反向传播没有影响, 避免了反向传播时因为权重过大或过小导致的梯度消失或梯度爆炸问题, 从而加速了神经网络的训练.
**权重伸缩不变性还具有参数正则化的效果, 可以使用更高的学习率. **
由于
因此, 下层的权重值越大, 其梯度就越小. 这样, 参数的变化就越稳定, 相当于实现了参数正则化的效果, 避免参数的大幅震荡, 提高网络的泛化性能.
**数据伸缩不变性(data scale invariance)**指的是, 当数据 按照常量
进行伸缩时, 得到的规范化后的值保持不变, 即:
其中 .
**数据伸缩不变性仅对 BN、LN 和 CN 成立. **因为这三者对输入数据进行规范化, 因此当数据进行常量伸缩时, 其均值和方差都会相应变化, 分子分母互相抵消. 而 WN 不具有这一性质.
数据伸缩不变性可以有效地减少梯度弥散, 简化对学习率的选择.
对于某一层神经元 而言, 展开可得
每一层神经元的输出依赖于底下各层的计算结果. 如果没有正则化, 当下层输入发生伸缩变化时, 经过层层传递, 可能会导致数据发生剧烈的膨胀或者弥散, 从而也导致了反向计算时的梯度爆炸或梯度弥散.
加入 Normalization 之后, 不论底层的数据如何变化, 对于某一层神经元 而言, 其输入
永远保持标准的分布, 这就使得高层的训练更加简单. 从梯度的计算公式来看:
数据的伸缩变化也不会影响到对该层的权重参数更新, 使得训练过程更加鲁棒, 简化了对学习率的选择.