在了解「最小生成树」之前,我们需要要先理解 「生成树」的概念。
图的生成树(Spanning Tree):如果无向连通图 G 的一个子图是一棵包含图 G 所有顶点的树,则称该子图为 G 的生成树。生成树是连通图的包含图中的所有顶点的极小连通子图。图的生成树不惟一。从不同的顶点出发进行遍历,可以得到不同的生成树。
换句话说,生成树是原图 G 的一个子图,它包含了原图 G 的所有顶点,并且通过选择图中一部分边连接这些顶点,使得子图中没有环。
生成树有以下特点:
- 包含所有顶点:生成树中包含了原图的所有顶点。
- 连通性:生成树是原图的一个连通子图,意味着任意两个顶点之间都存在一条路径。
- 无环图:生成树一个无环图。
-
边数最少:在包含所有顶点的情况下,生成树的边数最少,其边数为顶点数减
$1$ 。
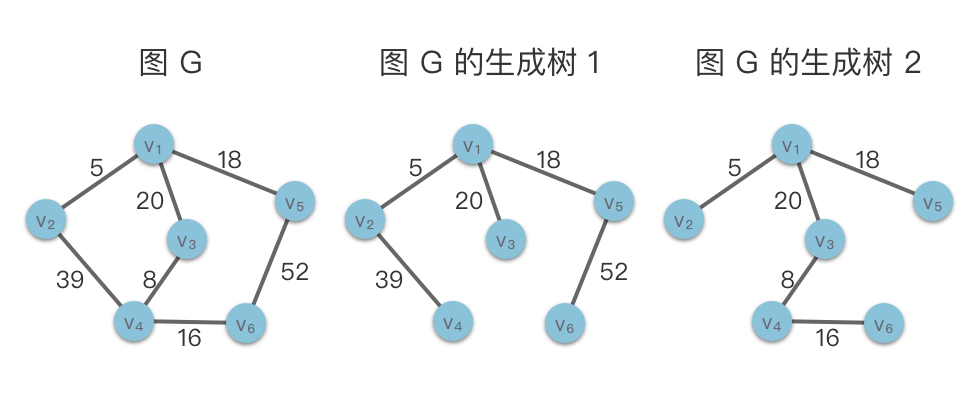
如上图所示,左侧图
最小生成树(Minimum Spanning Tree):无向连通图 G 的所有生成树中,边的权值之和最小的生成树,被称为最小生成树。
最小生成树除了包含生成树的特点之外,还具有一个特点。
- 边的权值之和最小:在包含所有顶点的情况下,最小生成树的边的权重之和是所有可能的生成树中最小的。

如上图所示,左侧图
为了找到无向图的最小生成树,常用的算法有「Prim 算法」和「Kruskal 算法」。
- Prim 算法:从一个起始顶点出发,逐步选择与已经构建的树连接的最短边,直到包含所有顶点为止。
- Kruskal 算法:基于边的排序和并查集数据结构,逐步添加边,并保证所选边不会构成环路,直到构建出最小生成树。
这两个算法都可以帮助我们找到图中的最小生成树,以满足连接所有顶点的要求同时使得总权重最小。
Prim 算法的算法思想:每次选择最短边来扩展最小生成树,从而保证生成树的总权重最小。算法通过不断扩展小生成树的顶点集合
$MST$ ,逐步构建出最小生成树。
- 将图
$G$ 中所有的顶点$V$ 分为两个顶点集合$V_A$ 和$V_B$ 。其中$V_A$ 为已经加入到最小生成树的顶点集合,$V_B$ 是还未加入生成树的顶点集合。 - 选择起始顶点
$start$ ,将其加入到最小生成树的顶点集合$V_A$ 中。 - 从
$V_A$ 的顶点集合中选择一个顶点$u$ ,然后找到连接顶点$u$ 与$V_B$ 之间的边中权重最小的边。 - 让上一步中找到的顶点和边加入到
$MST$ 中,更新$MST$ 的顶点集合和边集合。 - 重复第
$3 \sim 4$ 步,直到$MST$ 的顶点集合中包含了图中的所有顶点为止。
Kruskal 算法的算法思想:通过依次选择权重最小的边并判断其两个端点是否连接在同一集合中,从而逐步构建最小生成树。这个过程保证了最终生成的树是无环的,并且总权重最小。
在实际实现中,我们通常使用并查集数据结构来管理顶点的集合信息,以便高效地判断两个顶点是否在同一个集合中,以及合并集合。
- 将图中所有边按照权重从小到大进行排序。
- 将每个顶点看做是一个单独集合,即初始时每个顶点自成一个集合。
- 按照排好序的边顺序,按照权重从小到大,依次遍历每一条边。
- 对于每条边,检查其连接的两个顶点所属的集合:
- 如果两个顶点属于同一个集合,则跳过这条边,以免形成环路。
- 如果两个顶点不属于同一个集合,则将这条边加入到最小生成树中,同时合并这两个顶点所属的集合。
- 重复第
$3 \sim 4$ 步,直到最小生成树中的变数等于所有节点数减$1$ 为止。