We have n jobs, where every job is scheduled to be done from startTime[i] to endTime[i], obtaining a profit of profit[i].
You're given the startTime, endTime and profit arrays, return the maximum profit you can take such that there are no two jobs in the subset with overlapping time range.
If you choose a job that ends at time X you will be able to start another job that starts at time X.
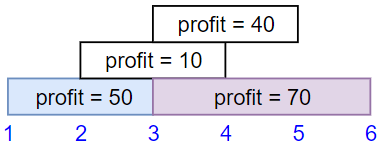
Input: startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70] Output: 120 Explanation: The subset chosen is the first and fourth job. Time range [1-3]+[3-6] , we get profit of 120 = 50 + 70.
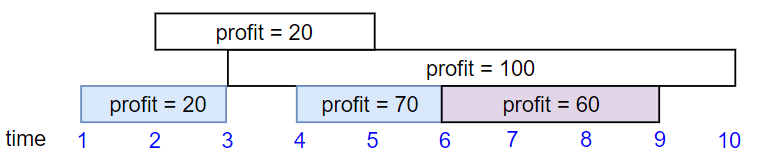
Input: startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60] Output: 150 Explanation: The subset chosen is the first, fourth and fifth job. Profit obtained 150 = 20 + 70 + 60.

Input: startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4] Output: 6
1 <= startTime.length == endTime.length == profit.length <= 5 * 1041 <= startTime[i] < endTime[i] <= 1091 <= profit[i] <= 104
impl Solution {
pub fn job_scheduling(start_time: Vec<i32>, end_time: Vec<i32>, profit: Vec<i32>) -> i32 {
let mut jobs = (0..profit.len())
.map(|i| (end_time[i], start_time[i], profit[i]))
.collect::<Vec<_>>();
let mut dp = vec![(0, 0)];
let mut ret = 0;
jobs.sort_unstable();
for &(et, st, pf) in &jobs {
let i = match dp.binary_search_by_key(&st, |&(t, _)| t) {
Ok(i) => i,
Err(i) => i - 1,
};
if et != dp.last().unwrap().0 {
dp.push((et, dp[i].1 + pf));
} else if dp.last().unwrap().1 < dp[i].1 + pf {
dp.last_mut().unwrap().1 = dp[i].1 + pf;
}
if ret > dp.last().unwrap().1 {
dp.last_mut().unwrap().1 = ret;
} else {
ret = dp.last().unwrap().1;
}
}
ret
}
}