Quickstart
Please use the scalanlp/breeze wiki from now on.
Breeze is hosted on github and is built with sbt
Set up sbt following their instructions, and then run sbt. The following targets are useful:
-
compile-- Builds the library -
test-- Runs the unit tests -
doc-- Builds scaladoc for the public API -
publish-local-- Copies jars to local Ivy repository. -
assembly-- Builds a distributable jar -
console-- starts a scala repl
First, publish-local the jars so that they're available to SBT. We'll get them hosted soon. Breeze consists of three parts:
- breeze-math contains high-performance linear algebra and numerics.
- breeze-process contains tokenization, and other NLP-related items.
- breeze-learn contains machine learning and optimization routines.
- breeze-core contains some basic data structures and configuration. (New as of 0.2-SNAPSHOT.)
For SBT, Add these lines to your SBT project definition:
- For SBT versions 0.10.x
libraryDependencies ++= Seq(
// other dependencies here
// pick and choose:
"org.scalanlp" %% "breeze-math" % "0.1",
"org.scalanlp" %% "breeze-learn" % "0.1",
"org.scalanlp" %% "breeze-process" % "0.1",
"org.scalanlp" %% "breeze-viz" % "0.1"
)
resolvers ++= Seq(
// other resolvers here
// if you want to use snapshot builds (currently 0.2-SNAPSHOT), use this.
"Sonatype Snapshots" at "https://oss.sonatype.org/content/repositories/snapshots/"
)
// Scala 2.10 is supported with 0.2-SNAPSHOT
scalaVersion := "2.9.2"Breeze-Math is modeled on Scalala, and so if you're familiar with it, you'll be familiar with Breeze-Math. First, import the linear algebra package:
scala> import breeze.linalg._Let's create a vector:
scala> val x = DenseVector.zeros[Double](5)
x: breeze.linalg.DenseVector[Double] = DenseVector(0.0, 0.0, 0.0, 0.0, 0.0)Here we make a column vector of zeros of type Double. And there are other ways we could create the vector - such as with a literal DenseVector(1,2,3) or with a call to fill or tabulate. Unlike Scalala, all Vectors are column vectors. Row vectors are represented as matrices.
The vector object supports accessing and updating data elements by their index in 0 to x.length-1. The vector is "dense" because it is backed by an Array[Double], but could as well have created a SparseVector.zeros[Double](5), which would not allocate memory for zeros.
scala> x(0)
res0: Double = 0.0
scala> x(1) = 2
scala> x
res2: breeze.linalg.DenseVector[Double] = DenseVector(0.0, 2.0, 0.0, 0.0, 0.0)Breeze also supports slicing. Note that slices using a Range are much, much faster than those with an arbitrary sequence.
scala> x(3 to 4) := .5
res3: breeze.linalg.DenseVector[Double] = DenseVector(0.5, 0.5)
scala> x
res4: breeze.linalg.DenseVector[Double] = DenseVector(0.0, 2.0, 0.0, 0.5, 0.5)The slice operator constructs a read-through and write-through view of the given elements in the underlying vector. You set its values using the vectorized-set operator :=. You could as well have set it to a compatibly sized Vector.
scala> x(0 to 1) := DenseVector(.1,.2)
scala> x
res6: breeze.linalg.DenseVector[Double] = DenseVector(0.1, 0.2, 0.0, 0.5, 0.5)Similarly, a DenseMatrix can be created with a constructor method call, and its elements can be accessed and updated.
scala> val m = DenseMatrix.zeros[Int](5,5)
m: breeze.linalg.DenseMatrix[Int] =
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0 The columns of m can be accessed as DenseVectors, and the rows as DenseMatrices.
scala> (m.rows, m.cols)
res10: (Int, Int) = (5,5)
scala> m(::,1)
res7: breeze.linalg.DenseVector[Int] = DenseVector(0, 0, 0, 0, 0)
scala> m(4,::) := DenseVector(1,2,3,4,5).t // transpose to match row shape
res8: breeze.linalg.DenseMatrix[Int] = 1 2 3 4 5
scala> m
res9: breeze.linalg.DenseMatrix[Int] =
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
1 2 3 4 5 Assignments with incompatible cardinality or a larger numeric type won't compile. Assignments with incompatible size will throw an exception:
scala> m := x
<console>:13: error: could not find implicit value for parameter op: breeze.linalg.operators.BinaryUpdateOp[breeze.linalg.DenseMatrix[Int],breeze.linalg.DenseVector[Double],breeze.linalg.operators.OpSet]
m := x
^
scala> m := DenseMatrix.zeros[Int](3,3)
java.lang.IllegalArgumentException: requirement failed: Matrixs must have same number of rowSub-matrices can be sliced and updated, and literal matrices can be specified using a simple tuple-based syntax. Unlike Scalala, only range slices are supported, and only the columns (or rows for a transposed matrix) can have a Range step size different form 1.
scala> m(0 to 1, 0 to 1) := DenseMatrix((3,1),(-1,-2))
res12: breeze.linalg.DenseMatrix[Int] =
3 1
-1 -2
scala> m
res13: breeze.linalg.DenseMatrix[Int] =
3 1 0 0 0
-1 -2 0 0 0
0 0 0 0 0
0 0 0 0 0
1 2 3 4 5 This document describes several of the major components of the 0.2 release of Breeze-Data and Breeze-Learn. It's intended as something of an overview, and not a reference, for that, see the scaladocs.
**This API is highly experimental. It may change greatly. **
Breeze continues most of the functionality of Scalala's plotting facilities, though the API is somewhat different (in particular, more object oriented.) These methods are documented in scaladoc (sbt doc) for the traits in the breeze.plot package object. First, let's plot some lines and save the image to file. All the actual plotting work is done by the excellent JFreeChart library.
import breeze.plot._val f = Figure()
val p = f.subplot(0)
val x = linspace(0.0,1.0)
p += plot(x, x :^ 2.0)
p += plot(x, x :^ 3.0, '.')
p.xlabel = "x axis"
p.ylabel = "y axis"
f.saveas("lines.png") // save current figure as a .png, eps and pdf also supported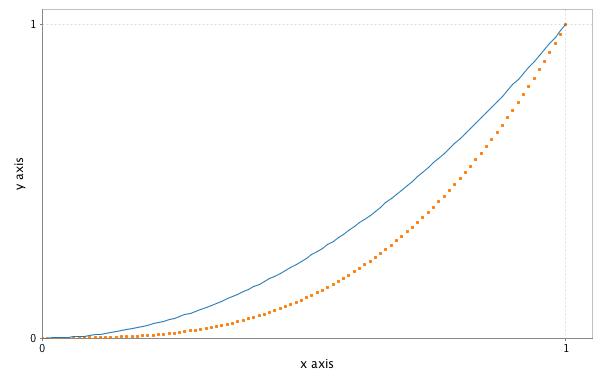
Then we'll add a new subplot and plot a histogram of 100,000 normally distributed random numbers into 100 buckets.
val p2 = f.subplot(2,1,1)
val g = breeze.stats.distributions.Gaussian(0,1)
p2 += hist(g.sample(100000),100)
p2.title = "A normal distribution"
f.saveas("subplots.png")
Breeze also supports the Matlab-like "image" command, here imaging a random matrix.
val f2 = Figure()
f2.subplot(0) += image(DenseMatrix.rand(200,200))
f2.saveas("image.png")
breeze.config.Configuration is a general mechanism for handling program configuration. It relies on reflection and bytecode munging to work. In particular, classes defined in the REPL won't work.
Configurations can be made in three ways:
- from a Map[String,String]:
scalaConfiguration.fromMap(m) - from Java-style properties files:
scalaConfiguration.fromPropertiesFiles(Seq(f1,f2,f3)) - from command line arguments:
scalaCommandLineParser.parseArguments(args)
For basic usage, you can read in a property with scalaconfig.readIn[T]("property.name", [optional default]). If a property named "property.name" cannot be found, it will look for just "name". If that fails, it will use either the default or throw an exception, if none is provided.
Configuration also supports reflectively processing case classes. For instance, the Trainer object in breeze.classify has the following parameters:
case class TrainerParams(
@Help(text="The kind of classifier to train. {Logistic,SVM,Pegasos}") `type`: String= "Logistic",
@Help(text="Input file in svm light format.") input: File= new java.io.File("train"),
@Help(text="Output file for the serialized classifier.") output: File = new File("classifier.ser"),
@Help(text="Optimization parameters.") opt: OptParams,
@Help(text="Prints this") help:Boolean = false)We can read in a TrainerParams by saying config.readIn[TrainerParams]("prefix"). Nested parameters have ".${name}" appended to this prefix.
The listing also illustrates a few other features. We have the Help annotation for displaying usage information with the GenerateHelp object. Configuration also supports Files natively. Recursive case classes are supported.
To specify the arguments, you can use command line arguments like --opt.batchSize 3 --useStochastic true --type Logistic. Anything not specified uses the default arguments provided by Scala. If no default is found, an error is thrown.
Most of the classifiers in Breeze-Learn expect Examples for training, which are simply traits that have a label, some features, and an id. Example is generic about what those types are. Observation is Example's parent type, and it differs only in not having a label.
There are also some routines for reading in different standard formats of datasets.
I'd like to outsource this package to someone else's library. This is a type-class oriented approach to writing and reading data. The idea is to provide a ReadWritable typeclass implicit for writing. For instance, DenseVector's ReadWritable instance looks like:
implicit object DenseVectorReadWritable extends ReadWritable[DenseVector[Double]] {
override def read(in : DataInput) = {
val offset = DataSerialization.read[Int](in)
val stride = DataSerialization.read[Int](in)
val length = DataSerialization.read[Int](in)
val data = DataSerialization.read[Array[Double]](in)
new DenseVector(data, offset,stride,length)
}
override def write(out : Output, v : DenseVector[Double]) {
DataSerialization.write(out,v.offset)
DataSerialization.write(out,v.stride)
DataSerialization.write(out,v.length)
DataSerialization.write(out,v.data)
}
}
Writing and reading are done though the obvious methods:
DataSerialization.write(output, t)
DataSerialization.read[T](input)
This package provides methods for tokenizing text and turning it into more useful forms. For example, we provide routines for segmenting sentences, tokenizing text into a form expected by most parsers, and stemming words.
scala> import breeze.text.tokenize._
import breeze.text.tokenize._
scala> val text = "Breeze is a library for numerical processing, machine learning, and natural language processing. Its primary focus is on being generic, clean, and powerful without sacrificing (much) efficiency."
text: java.lang.String = Breeze is a library for numerical processing, machine learning, and natural language processing. Its primary focus is on being generic, clean, and powerful without sacrificing (much) efficiency.
scala> import breeze.text.segment._
import breeze.text.segment._
scala> val sentences = (new JavaSentenceSegmenter)(text).toIndexedSeq
sentences: scala.collection.immutable.IndexedSeq[String] = Vector(Breeze is a library for numerical processing, machine learning, and natural language processing., Its primary focus is on being generic, clean, and powerful without sacrificing (much) efficiency.)
^
scala> val tokenized = sentences.map(PTBTokenizer)
tokenized: scala.collection.immutable.IndexedSeq[Iterable[String]] = Vector(ArrayBuffer(Breeze, is, a, library, for, numerical, processing, ,, machine, learning, ,, and, natural, language, processing, .), ArrayBuffer(Its, primary, focus, is, on, being, generic, ,, clean, ,, and, powerful, without, sacrificing, -LRB-, much, -RRB-, efficiency, .))
scala> tokenized foreach println
ArrayBuffer(Breeze, is, a, library, for, numerical, processing, ,, machine, learning, ,, and, natural, language, processing, .)
ArrayBuffer(Its, primary, focus, is, on, being, generic, ,, clean, ,, and, powerful, without, sacrificing, -LRB-, much, -RRB-, efficiency, .)
scala> import breeze.text.analyze._
import breeze.text.analyze._
scala> val res4 = tokenized.map { for( word <- _ ) yield (new PorterStemmer)(word) }
res4: scala.collection.immutable.IndexedSeq[Iterable[String]] = Vector(ArrayBuffer(breez, is, a, librari, for, numer, process, ,, machin, learn, ,, and, natur, languag, process, .), ArrayBuffer(it, primari, focu, is, on, be, gener, ,, clean, ,, and, power, without, sacrif, -lrb-, much, -rrb-, effici, .))
scala> res4 foreach println
ArrayBuffer(breez, is, a, librari, for, numer, process, ,, machin, learn, ,, and, natur, languag, process, .)
ArrayBuffer(it, primari, focu, is, on, be, gener, ,, clean, ,, and, power, without, sacrif, -lrb-, much, -rrb-, effici, .)
util contains a number of useful things. Mostly notable is Index which specifies a mapping from objects to integers. In NLP, we often need to map structured objects (strings say) to unique integers for efficiency's sake. This class, along with Encoder, allows for that.
Breeze provides 4 classifiers: a standard Naive Bayes classifier, an SVM, a Perceptron, and a Logistic Classifier (also known as a softmax or maximum entropy classifier). All classifiers (except Naive Bayes) have a Trainer class in their companion object, which can be used to train up a classifier from breeze.data.Examples. This classifier can then be applied to new observations.
Breeze also provides a fairly large number of probability distributions built in. These come with access to either probability density function (for discrete distributions) or pdf functions (for continuous distributions). Many distributions also have methods for giving the mean and the variance.
scala> val poi = new Poisson(3.0);
poi: breeze.stats.distributions.Poisson = <function1>
scala> poi.sample(10);
res21: List[Int] = List(3, 5, 5, 2, 2, 1, 1, 2, 4, 1)
scala> res21 map { poi.probabilityOf(_) }
res23: List[Double] = List(0.6721254229661636, 0.504094067224622, 0.504094067224622, 0.44808361531077556, 0.44808361531077556, 0.1493612051035918, 0.1493612051035918, 0.44808361531077556, 0.6721254229661628, 0.1493612051035918)
scala> val doublePoi = for(x <- poi) yield x.toDouble; // meanAndVariance requires doubles, but Poisson samples over Ints
doublePoi: java.lang.Object with breeze.stats.distributions.Rand[Double] = breeze.stats.distributions.Rand$$anon$2@2c98070c
scala> breeze.stats.DescriptiveStats.meanAndVariance(doublePoi.samples.take(1000));
res29: (Double, Double) = (3.018,2.9666426426426447)
scala> (poi.mean,poi.variance)
res30: (Double, Double) = (3.0,3.0)TODO: exponential families
Breeze's optimization package includes several convex optimization routines and a simple linear program solver. Convex optimization routines typically take a DiffFunction[T], which is a Function1 extended to have a gradientAt method, which returns the gradient at a particular point. Most routines will require a breeze.linalg-enabled type: something like a Vector or a Counter.
Here's a simple DiffFunction: a parabola along each vector's coordinate.
scala> import breeze.optimize._
import breeze.optimize._
scala> import breeze.linalg._
import breeze.linalg._
scala> val f = new DiffFunction[DenseVector[Double]] {
| def calculate(x: DenseVector[Double]) = {
| (norm((x - 3.) :^ 2.,1.),(x * 2.) - 6.);
| }
| }
f: java.lang.Object with breeze.optimize.DiffFunction[breeze.linalg.DenseVector[Double]] = $anon$1@617746b2Note that this function takes its minimum when all values are 3. (It's just a parabola along each coordinate.)
scala> f.valueAt(DenseVector(0,0,0))
res0: Double = 27.0
scala> f.valueAt(DenseVector(3,3,3))
res1: Double = 0.0
scala> f.gradientAt(DenseVector(3,0,1))
res2: breeze.linalg.DenseVector[Double] = DenseVector(0.0, -6.0, -4.0)
scala> f.calculate(DenseVector(0,0))
res3: (Double, breeze.linalg.DenseVector[Double]) = (18.0,DenseVector(-6.0, -6.0))
You can also use approximate derivatives, if your function is easy enough to compute:
scala> def g(x: DenseVector[Double]) = (x - 3.0):^ 2.0 sum
g: (x: breeze.linalg.DenseVector[Double])Double
scala> g(DenseVector(0.,0.,0.))
res5: Double = 27.0
scala> val diffg = new ApproximateGradientFunction(g)
diffg: breeze.optimize.ApproximateGradientFunction[Int,breeze.linalg.DenseVector[Double]] = <function1>
scala> diffg.gradientAt(DenseVector(3,0,1))
res5: breeze.linalg.DenseVector[Double] = DenseVector(1.000000082740371E-5, -5.999990000127297, -3.999990000025377)Ok, now let's optimize f. The easiest routine to use is just LBFGS, which is a quasi-Newton method that works well for most problems.
scala> val lbfgs = new LBFGS[DenseVector[Double]](maxIter=100, m=3) // m is the memory. anywhere between 3 and 7 is fine. The larger m, the more memory is needed.
lbfgs: breeze.optimize.LBFGS[breeze.linalg.DenseVector[Double]] = breeze.optimize.LBFGS@43e43267
scala> lbfgs.minimize(f,DenseVector(0,0,0))
scala> lbfgs.minimize(f,DenseVector(0,0,0))
res6: breeze.linalg.DenseVector[Double] = DenseVector(2.9999999999999973, 2.9999999999999973, 2.9999999999999973)
scala> f(res6)
res8: Double = 2.129924444096732E-29
That's pretty close to 0! You can also use a configurable optimizer, using FirstOrderMinimizer.OptParams. It takes several parameters:
case class OptParams(batchSize:Int = 512,
regularization: Double = 1.0,
alpha: Double = 0.5,
maxIterations:Int = -1,
useL1: Boolean = false,
tolerance:Double = 1E-4,
useStochastic: Boolean= false) {
// ...
}
batchSize applies to BatchDiffFunctions, which support using small minibatches of a dataset. regularization integrates L2 or L1 (depending on useL1) regularization with constant lambda. alpha controls the initial stepsize for algorithms that need it. maxIterations is the maximum number of gradient steps to be taken (or -1 for until convergence). tolerance controls the sensitivity of the convergence check. Finally, useStochastic determines whether or not batch functions should be optimized using a stochastic gradient algorithm (using small batches), or using LBFGS (using the entire dataset).
OptParams can be controlled using breeze.config.Configuration, which we described earlier.
We provide a DSL for solving linear programs, along with two methods for solving them. (I recommend InteriorPoint.) This package isn't industrial strength yet by any means, but it's good for simple problems. The DSL is pretty simple:
val lp = new LinearProgram()
import lp._
val x0 = Real()
val x1 = Real()
val x2 = Real()
val lpp = ( (x0 + x1 * 2 + x2 * 3 )
subjectTo ( x0 * -1 + x1 + x2 <= 20)
subjectTo ( x0 - x1 * 3 + x2 <= 30)
subjectTo ( x0 <= 40 )
)
val result = maximize( lpp)
assert( (result.result - DenseVector(40.,17.5,42.5)).norm(2) < 1E-4)
We also have specialized routines for bipartite matching (KuhnMunkres and CompetitiveLinking).