ELF文件:可执行可链接文件
ELF文件在磁盘中和在内存中是不同的形式存在,对应着链接视图和执行视图。
无论是哪个视图,ELF hader都是必不可少的部分,接着根据不同视图,可能为不同 的Section部分或Program部分。ELFHeader记录着Section和Program部分的信息以及ELF文件的属性,因此不过多描述。
从连接视图来看,一个ELF文件会包含有多个Section,为了描述这些Section的信息和方便索引,还有一个Section Header Table。
SHT是个结构体数组,每个结构体对应着一项Section
- sh_name section表名,保存的是在.shstrtab中的偏移量
- sh_type
- sh_flags
- sh_addr
- sh_offset
- sh_size
Section Header String Table,存储Section名称用到的字符串信息。
PS:ELF文件可能包含多个String Table Sectino,例如.strtab section(存储.symtab符号表用到的字符串)、.dynstr section(存储.dynsym符号表用到的字符串)
.text section:用于存储程序的指令。简单点说,程序的机器指令就放在这个section中。。
.bss section:bss是block storage segment的缩写。ELF规范中,.bss section包含了一块内存区域,这块区域在ELF文件被加载到进程空间时会由系统创建并设置这块内存的内容为0。注意,.bss section在ELF文件里不占据任何文件的空间,所以其sh_type为SHF_NOBITS(取值为8),它只是在ELF加载到内存的时候会分配一块由sh_size指定大小的内存。一般用于存储全局变量。
.symtab section是ELF中非常重要的一个section,里边存储的是符号表(SymbolTable)。在链接的过程中需要把多个不同的目标文件合并在一起,不同的目标文件相互之间会引用变量和函数。在链接过程中,我们将函数和变量统称为符号,函数名和变量名就是符号名。.symtab section的类型为SHT_SYMTAB。一般而言,符号表主要用于编译链接,也可以参与动态库的加载。
.symtab section往往包含了全部的符号表信息,但不是其中所有符号信息都会参与动态链接,所以ELF还专门定义一个.dynsym section(类型为SHT_DYNSYM),这个section存储的仅是动态链接需要的符号信息。
访问全局变量的操作通常会被编译器翻译成访问内存地址的指令。然而,可重定位文件中的节只记录了它在文件中的位置,而不像段一样记录它在内存中的位置,因此我们并不知道文件中定义的全局变量的内存地址。除此之外,如果一个文件引用了另一个文件定义的全局变量,那么直到将它们链接起来之前,我们都不可能知道这个全局变量的内存地址。 进一步地说,直到最终链接成可执行文件时,我们才能知道全局变量和函数的内存地址,在此之前我们始终无法生成访问它们的指令。
在静态链接(动态链接则是plt表和got表)中ELF 文件的做法是:仍然按照正常的流程生成访问这些全局变量和函数的指令,但是在内存地址部分填写 0,并且将这些占位 0 的出现的位置记录在 ELF 文件中。在确定了所有这些符号的内存地址后,将占位 0 改成正确的内存地址。
如果访问的是全局数组中的某个元素或者全局结构的某个成员,我们会将元素或成员的偏移量当作占位符写在内存地址出现的地方。在确定了符号的内存地址后,将这两者相加就可以得到正确的内存地址。这个偏移量被称作 addon 。
记录这些占位符的位置就是重定位表,重定位最主要的作用就是将符号的使用之处和符号的定义之处关联起来。
链接器Linker在处理目标文件时,需要对代码段和数据段中绝对地址引用的位置进行重定位,对于每个需要重定位的代码段或数据段,都会有一个相应的重定位表。比如”.rel.text”就是针对”.text”的重定位表,”.rel.data”就是针对”.data”的重定位表。例如使用objdump -r解析时可以看到,重定位表中会包含:
- offset:重定位的入口偏移,对于可重定位文件来说,这个值是该 重定位入口所要修正的位置的第一个 字节相对段起始的偏移。对于 可执行文件或者共享文件来说,这个值是所有修正的位置的 第一个字节的虚拟地址。
- value:要重定位的函数或者变量名称
- 重定位时的地址计算方式
- addon
常见的地址计算方式有:
- R_386_32 符号内存地址 + Addon
- R_386_PC32 符号内存地址 + Addon -PC
如何将符号的使用之处和它的定义之处关联起来呢,方法有两种,
·编译链接过程中,最终生成可执行文件或动态库文件时,编译链接器将根据ELF文件中的重定位表计算最终的符号的位置。
·加载动态库时,加载器也会根据重定位信息修改对应的符号使用之处,使得动态库能正常工作。
rela和rel的区别在于.rel 格式的重定位表将 addon 写在内存地址出现的位置,当作占位符,如同前面描述的一样;而 .rela 格式的重定位表将 addon 写在重定位表中,而不是被重定位的位置上。。
动态链接的文件中,有专门的重定位表分别叫做.rel.dyn和.rel.plt。
前者是对数据引用的修正,所修正的位置位于.got以及数据段。
后者是对函数引用的修正,所修正的位置位于.got
Execution View中ELF必须包含Program Header Table(以后简称PH Table)。和Section Header Table相对应,PH Table描述的是segment的信息。
PHT中几个关键字段
- p_offset:该segment位于文件的起始位置
- p_filesz:该segment在文件中占据的大小,可以为0,因为segment是由section组成的,有些section在文件中不占据空间,比如前文提到的.bss section。p_offset和p_filesz决定了Section到Segement之间的映射关系,区间落在[p_offset,p_offset+p_filesz]范围内的Section属于同一个Segment。
·ELF文件真正核心的内容其实是包含在一个个的Section中。了解Section的类型、内部对应的数据结构及功能对于掌握ELF有着至关重要的作用。
·当ELF文件加载到内存中时,ELF文件不同的Section会根据PH Table的映射关系映射到进程的虚拟内存空间中去。这时的Section就会以Segment的样子呈现出来。
另外,结合Linking View和本节的内容可知,要实现一个ELF文件的解析有两种方式。·基于Linking View的方式:即根据Section Header Table解析Section。这时只要按基于文件的偏移量来读取不同Section的内容,再根据Section对应的数据结构来解析它就可以。这种方式适用于类似readelf这样的工具。
·基于Execution View的方式:即先打开文件,然后逐个将PH Table(ProgramHeader Table)中的Segment映射到(利用mmap系统调用)对应的虚拟内存地址(p_vaddr)上去。然后就可以遍历Segment的内容。不过,由于Segment可由多个Section组成,在解析这样的Segment之时,不免还是需要借助Section HeaderTable。这种方法比基于Linking View的方式麻烦一些,但Android里的oatdump工具就是用这种方法解析oat文件的。
源码编译成ELF文件后,代码就被翻译成了机器指令。而函数调用对应的指令就是指示CPU先跳到该函数所在的内存地址,然后执行后面的指令。所以,对于函数调用而言,最关键之处莫过于确定该函数的入口在内存中的地址了。那么,如何确定这个函数的地址[插图]呢?
一种很直观的方法是编译时确定。如果编译时就能计算出某个函数的地址,这个问题就非常简单了。比如main函数调用test函数,如果test函数在编译时得到其入口地址为0x00009000(虚拟地址)的话。那么,对应的调用指令可能就是"call 0x00009000"。但现实中这种做法很不实用,原因有很多,比如:
- 如果一个程序使用多个动态库,编译器很难为所有函数都确定一个绝对地址。
- 出于安全考虑,操作系统加载动态库到内存的时候并不会使用固定的位置,而是会基于一个随机数来计算最终的加载位置。如此,0x00009000这个地址不太可能是test函数在内存后的真正地址。并且,test的真实地址每次随着动态库加载都可能不一样。
ELF规范中的GOT表就是用于解决此问题的。
GOT表也是一个Section,GOT表对应的section名为.got,每一项存储的是该ELF文件用到的符号(函数或变量)的地址。
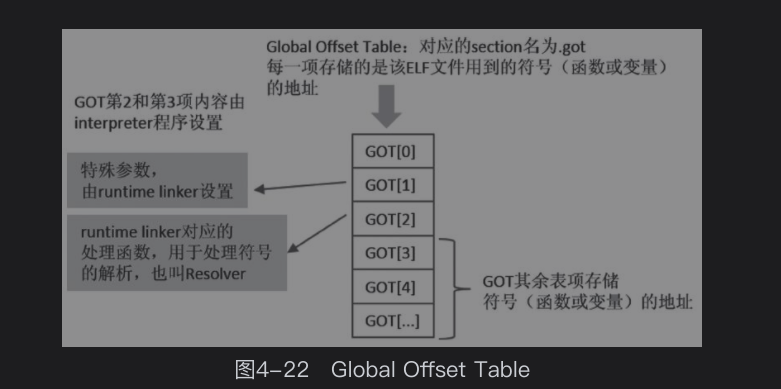
值得注意的是,GOT第2项和第3项内容由interpreter程序设置,
即GOT[1]由runtime linker设置,Program Header中索引号为1的元素,其类型为PT_INTERP,值为/linux64/ld-linux-x86-64.so.2。这个东西其实就是链接器ld。当可执行程序使用动态库的时候,编译器会将ld的信息放到ELF对应位置上。当可执行程序被操作系统加载和准备执行之时,操作系统发现该程序有PT_INTERP类型的segment,就会先跳转到ld的entry point执行(注意,ld也是一个ELF文件)。也就是说,对于使用动态库的可执行程序,操作系统首先执行的是ld,而不是可执行程序本身。当然,操作系统还会把和待执行的目标程序信息一起告诉ld。ld则负责加载那些执行时需要的动态库(是根据可执行程序ELF文件里的.dynsym表等信息来处理),设置好GOT等对应项。最后,系统的控制权将交还给可执行程序。这时,我们的程序才真正运行起来。
GOT[2]为runtime linker对应的处理函数用于处理符号的解析,一般称之为Resolver。
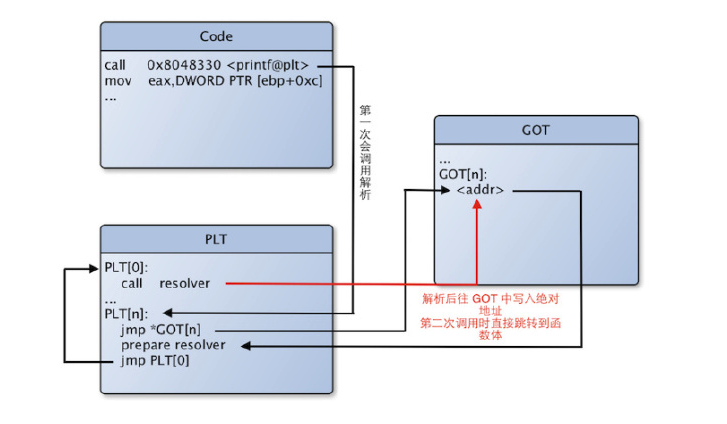
GOT其余表项存储符号(函数或变量)的地址。特别注意:其余表项中的值将由Resolver动态填写。即,当调用者第一次访问这些符号的时候,将触发Interpreter的Resolver函数被调用,该函数将计算符号的最终地址,然后填写到GOT对应项中。而符号地址的计算方法依赖于ELF文件中重定位和符号表中的一些信息。
但是问题来了,GOT表既然存储的是符号的绝对地址,但是这些地址又是从哪儿来和什么时候计算得来的呢。
前面说到GOT[1]存储着ld的地址,ld来计算符号的绝对地址,但是绝对地址的计算是什么时候计算出来呢,真的是全都在ld执行时就已经计算完毕吗?
其实不是,一般而言,符号地址计算有两个时机:
-
ld将控制权交给可执行程序之前。此时,ld已经加载了依赖的动态库,而且也知道这些动态库加载到内存的虚拟地址,这样就可以计算出所有需要的符号的地址。如果要使用这种方法的话,需要设置环境变量LD_BIND_NOW(exportLD_BIND_NOW=1)。对于运行中调用dlopen来加载so文件的程序而言,就需设置dlopen的flag参数为RTLOAD_NOW。这种做法的一个主要缺点在于它使得那些大量依赖动态库的程序的加载时间变长。
-
用的时候再计算。相比上面一种方式而言,这种方式可以让ld尽快把控制权交给可执行程序本身,从而提升程序启动速度。如果要使用这种方式,需要设置环境变量LD_BIND_NOT(ld默认采用这种策略)。而对于dlopen来说,设置flag为RTLOAD_LAZY即可。
但是程序本身是不知道ld到底会使用哪种方法的,所以编译器生成的二进制文件必须同时支持这两种方法。这是如何做到的呢?现在请出第二个辅助手段,PLT。
Procedure Linkage Table简称PLT,也是一种表结构,不过其表项存储的是一段小小的代码,这段代码能帮助我们触发符号地址的计算以及跳转到正确的符号地址上。类似这种跳转作用的函数,一般比喻为跳板函数Trampoline,在了解inline hook时也会经常接触到。
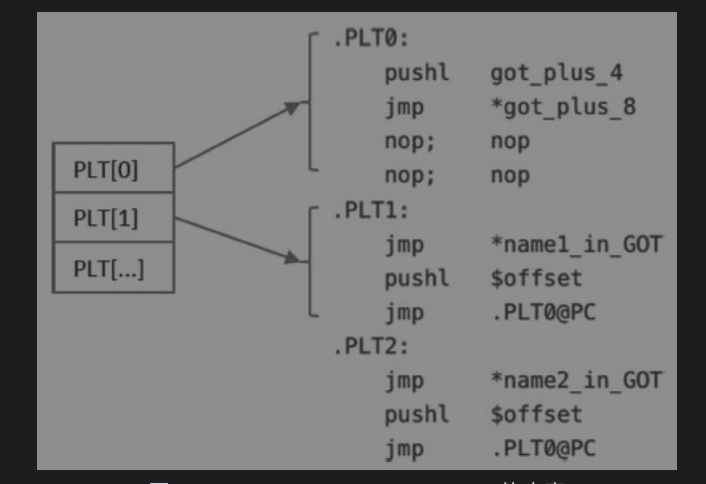
- PLT[0]存储的是跳转到GOT表Resolver的指令。
- PLT[1]存储的是跳转到符号对应GOT表中的内容,如果该符号的地址还未计算,该内容存储的其实是一条用于将计算 这个符号地址所需的参数压栈的指令的地址,然后PLT[1]接着执行到PLT[0]即resolver。如果这个符号地址已经计算过,那么就直接跳到目标地址上了。
GOT表Hook的目标是找到对应GOT项位置,替换目标地址。 假如我们已经知道目标函数的内存地址,那么我们可以:
- 首先我们需要找到GOT表在ELF文件中的偏移位置,因为GOT表也是个Section,通过ELF Header中e_shoff即 section header偏移进入section header table中,然后遍历每一个sh_name(需要到.shstrtab中找具体的字符串字面量,.shstrtab也是个section,通过遍历判断sh_type是否是SHT_STRTAB找到),判断是否为got表。
- 或者直接通过Elf Header中e_shstrndx索引到shstrtab位置。
- 这样我们便可以找到.got表在elf文件中的偏移量,配合在maps文件找到的模块基地址,就可以定位到进程so中GOT表的位置了。
- 拿到目标函数的地址,遍历.got表进行 匹配找到对应表项替换即可。
还有一种解决方案是通过.rel.plt表来定位GOT表。
- 找到.rel(a).plt,遍历对应的符号
- 上.symtab中查找符号对应的名字在.strtab中的偏移
- 上.strtab中查找符号具体的值。
http://nicephil.blinkenshell.org/my_book/ch07s05.html