Light Bulb is an labeling tool built with state of the art active learning and semi supervised learning techniques. Currently supports text classification and image classification.
See the Medium post here.
brew install yarn
git clone https://github.com/czhu12/labelling-tool && cd labelling-tool
make
make dataset/cat_not_cat # Download and set up dataset.
./bin/run config/examples/cat_not_cat.yml # Server set up on localhost:5000
make dataset/small_imdb_reviews # Download and set up dataset.
./bin/run config/examples/small_imdb_reviews.yml # Server set up on localhost:5000
Heres an example configuration:
task:
title: What kind of animal is this?
description: Select the type of animal you see, if there is none, select "Skip"
dataset:
directory: dataset/image_classification/
data_type: images
judgements_file: outputs/image_multiclass_classification/labels.csv
label:
type: classification
classes:
- Dog
- Cat
- Giraffe
- Dolphin
- Skip
model:
directory: outputs/image_multiclass_classification/models/
user: chris
task:
title: What kind of animal is this?
description: Select the type of animal you see, if there is none, select "Skip"
dataset:
directory: dataset/image_classification/
data_type: images
judgements_file: outputs/image_multiclass_classification/labels.csv
judgements_file defines the file that the labels are saved in.
data_type defines what type of model is used. Valid options are images and text
label:
type: classification
classes:
- Dog
- Cat
- Giraffe
- Dolphin
type defines the type of label, options are classification and binary.
model:
directory: outputs/image_multiclass_classification/models/
directory defines where the trained model is saved.
user: chris
user defines who the person labeling is, which may be useful when the label's are used.
To run the text classification demo:
make dataset/small_imdb_reviews
./bin/run config/examples/small_imdb_reviews.yml
To run the image classification demo:
make dataset/cat_not_cat
./bin/run config/examples/cat_not_cat.yml
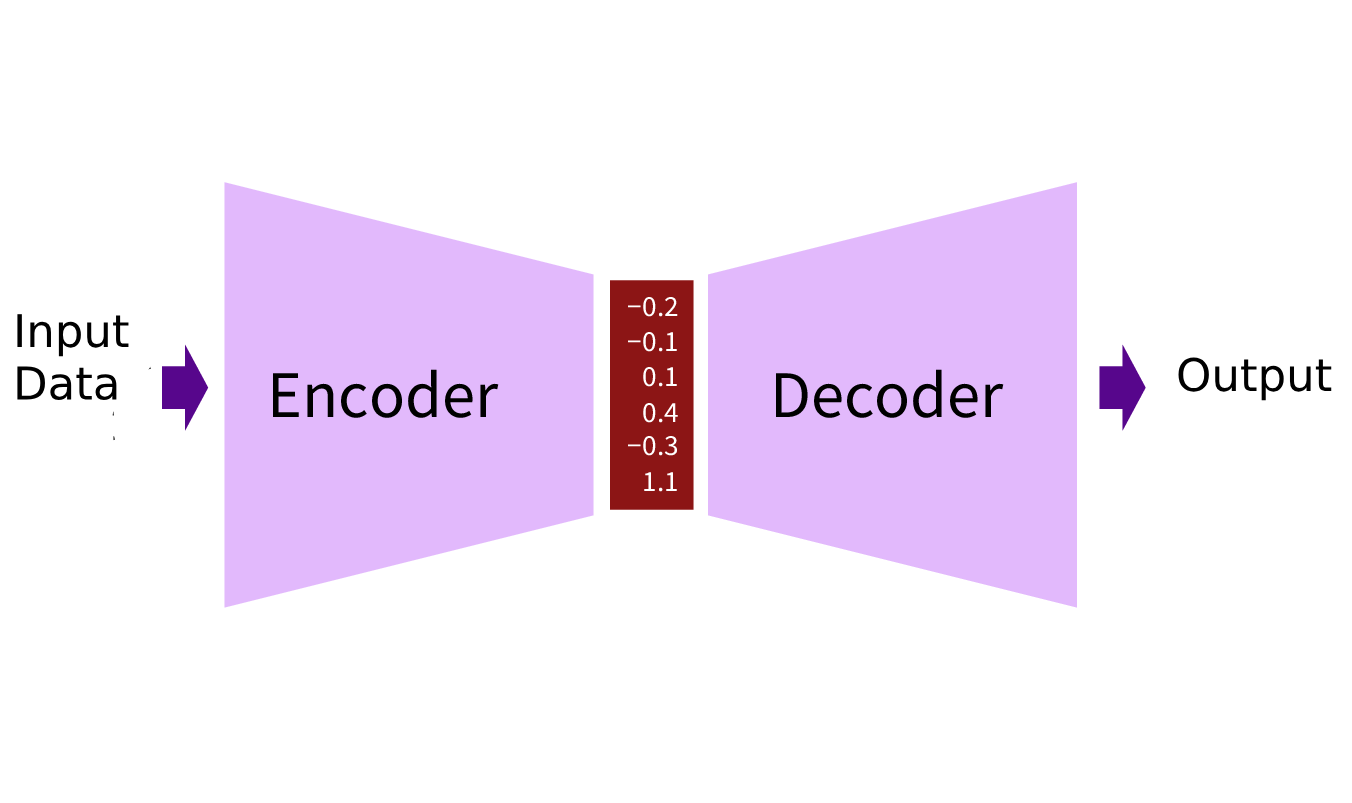
Most deep learning tasks can be framed as a encoder - decoder architecture. For example, text classification can be framed as an LSTM encoder that outputs into a logistic regression decoder. Object detection can be framed as a ResNet encoder with a regression decoder. All models in Light Bulb are framed as an encoder - decoder architecture, and the encoder are pre-trained on an external dataset (Image Net for images, and Wikitext-103 for text), and then fine-tuned on the target dataset.
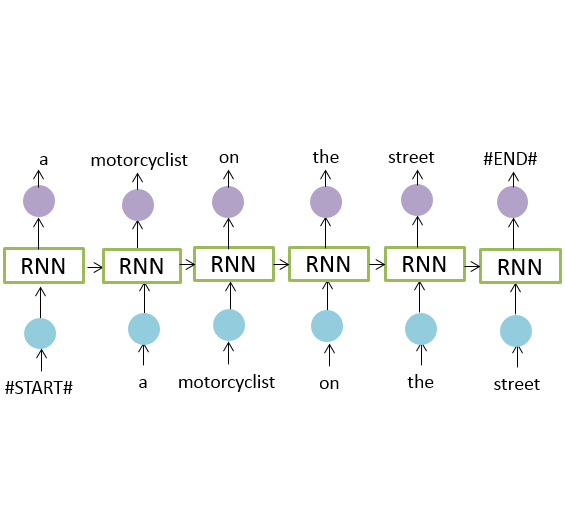
Light Bulb's text encoder is a pretrained language model on wikitext-103 (inspired by ULMFiT), with a vocab limited to the most frequent 100k words in the corpus. The model is fine-tuned on the target dataset as a language model.
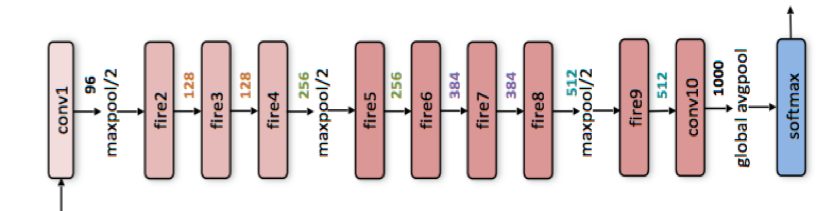
Light Bulb uses Squeeze Net pretrained on the ImageNet dataset to encode image data. The encoder is fine-tuned on the target dataset that is given to be labeled as an auto-encoder. Standard image augmentation techniques are used to expand the labeled training set.
Light Bulb will train a model as you provide training data through labeling. Light Bulb will sample items to be labeled by scoring the unlabeled items and sample the highest entropy items.
- Sequence Tagging
- Object Detection
- Sequence to Sequence Modeling
- Dockerize Application