This repository contains the code for TACL2021 paper: SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization
We release: (1) the trained SummaC models, (2) the SummaC Benchmark and data loaders, (3) training and evaluation scripts.
[Update] Thanks to @Aktsvigun for the help, we now have a pip package, making it easy to install the SummaC models:
pip install summac
Requirement issues: in v0.0.4, we've reduced package dependencies to facilitate installation. We recommend you install torch first and verify it works before installing summac.
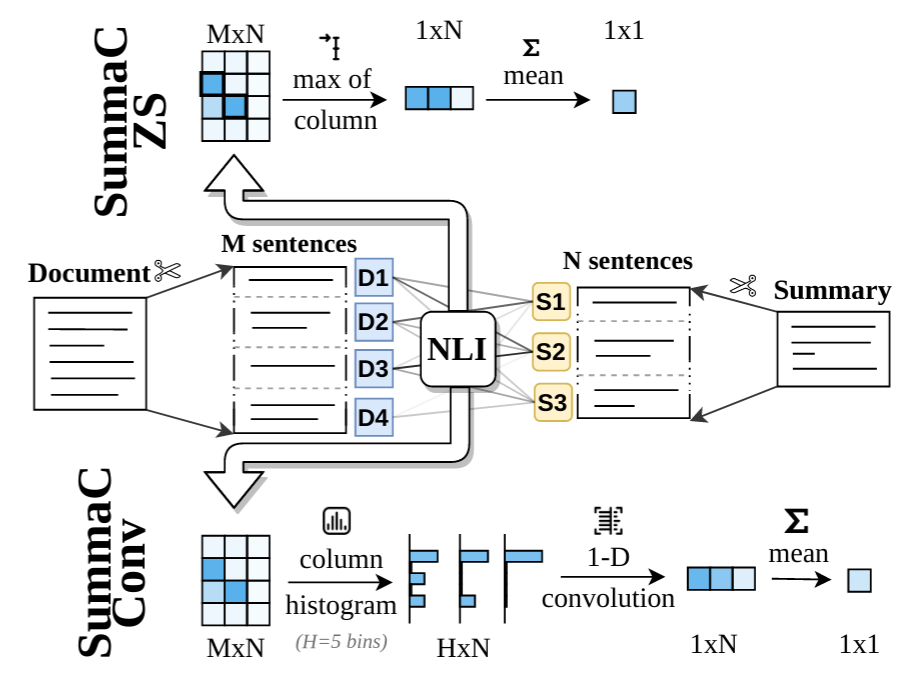
The two trained models SummaC-ZS and SummaC-Conv are implemented in model_summac (link). Once the package is installed, the models can be used like this:
from summac.model_summac import SummaCZS, SummaCConv
model_zs = SummaCZS(granularity="sentence", model_name="vitc", device="cpu") # If you have a GPU: switch to: device="cuda"
model_conv = SummaCConv(models=["vitc"], bins='percentile', granularity="sentence", nli_labels="e", device="cpu", start_file="default", agg="mean")
document = """Scientists are studying Mars to learn about the Red Planet and find landing sites for future missions.
One possible site, known as Arcadia Planitia, is covered instrange sinuous features.
The shapes could be signs that the area is actually made of glaciers, which are large masses of slow-moving ice.
Arcadia Planitia is in Mars' northern lowlands."""
summary1 = "There are strange shape patterns on Arcadia Planitia. The shapes could indicate the area might be made of glaciers. This makes Arcadia Planitia ideal for future missions."
score_zs1 = model_zs.score([document], [summary1])
score_conv1 = model_conv.score([document], [summary1])
print("[Summary 1] SummaCZS Score: %.3f; SummacConv score: %.3f" % (score_zs1["scores"][0], score_conv1["scores"][0])) # [Summary 1] SummaCZS Score: 0.582; SummacConv score: 0.536
summary2 = "There are strange shape patterns on Arcadia Planitia. The shapes could indicate the area might be made of glaciers."
score_zs2 = model_zs.score([document], [summary2])
score_conv2 = model_conv.score([document], [summary2])
print("[Summary 2] SummaCZS Score: %.3f; SummacConv score: %.3f" % (score_zs2["scores"][0], score_conv2["scores"][0])) # [Summary 2] SummaCZS Score: 0.877; SummacConv score: 0.709We recommend using the SummaCConv models, as experiments from the paper show it provides better predictions. Two notebooks provide experimental details: SummaC - Main Results.ipynb for the main results (Table 2) and SummaC - Additional Experiments.ipynb for additional experiments (Tables 1, 3, 4, 5, 6) from the paper.
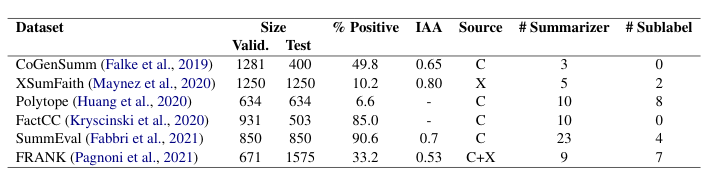
The SummaC Benchmark consists of 6 summary consistency datasets that have been standardized to a binary classification task. The datasets included are:
% Positive is the percentage of positive (consistent) summaries. IAA is the inter-annotator agreement (Fleiss Kappa). Source is the dataset used for the source documents (CNN/DM or XSum). # Summarizers is the number of summarizers (extractive and abstractive) included in the dataset. # Sublabel is the number of labels in the typology used to label summary errors.
The data-loaders for the benchmark are included in benchmark.py (link). Each dataset in the benchmark downloads automatically on first run. To load the benchmark:
from summac.benchmark import SummaCBenchmark
benchmark_val = SummaCBenchmark(benchmark_folder="/path/to/summac_benchmark/", cut="val")
frank_dataset = benchmark_val.get_dataset("frank")
print(frank_dataset[300]) # {"document: "A Darwin woman has become a TV [...]", "claim": "natalia moon , 23 , has become a tv sensation [...]", "label": 0, "cut": "val", "model_name": "s2s", "error_type": "LinkE"}If you make use of the code, models, or algorithm, please cite our paper.
@article{Laban2022SummaCRN,
title={SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization},
author={Philippe Laban and Tobias Schnabel and Paul N. Bennett and Marti A. Hearst},
journal={Transactions of the Association for Computational Linguistics},
year={2022},
volume={10},
pages={163-177}
}
If you'd like to contribute, or have questions or suggestions, you can contact us at [email protected]. All contributions welcome, for example helping make the benchmark more easily downloadable, or improving model performance on the benchmark.