이 폴더에는 문장 분리 성능을 평가하기 위한 코드와 데이터가 있습니다. 평가 데이터는 testset 폴더 안에 있으며 다음과 같이 구성되어 있습니다.
- sample: http://semantics.kr/%ED%95%9C%EA%B5%AD%EC%96%B4-%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B0-%EB%B3%84-%EB%AC%B8%EC%9E%A5-%EB%B6%84%EB%A6%AC-%EC%84%B1%EB%8A%A5%EB%B9%84%EA%B5%90/ 에서 소개된 블로그 예제
- blogs, blogs_ko: 다양한 블로그에서 수집한 텍스트
- etn: 명사형 전성 어미를 종결 어미처럼 사용하는 텍스트
- nested: 문장 내 안긴 문장이 있는 텍스트
- tweets: 무작위로 선택된 트윗 텍스트
- v_ending: 사투리를 비롯한 다양한 종결어미를 포함한 텍스트
- wikipedia: 위키백과 문서
또한 다음 세 가지 평가 코드를 제공합니다.
- sentence_split.py: 베이스라인과
Kiwi.split_into_sents의 성능을 평가합니다. - kss_ref.py: KSS의 성능을 평가합니다.
- koalanlp_ref.py: KoalaNLP Python에 포함된 다양한 문장 분리기의 성능을 평가합니다.
다음은 위의 데이터와 코드를 이용해 평가한 결과를 정리한 것입니다. 베이스라인은 . ! ? 문자 뒤에 바로 공백이 있는 경우만 문장 종결로 간주하고 분리합니다.
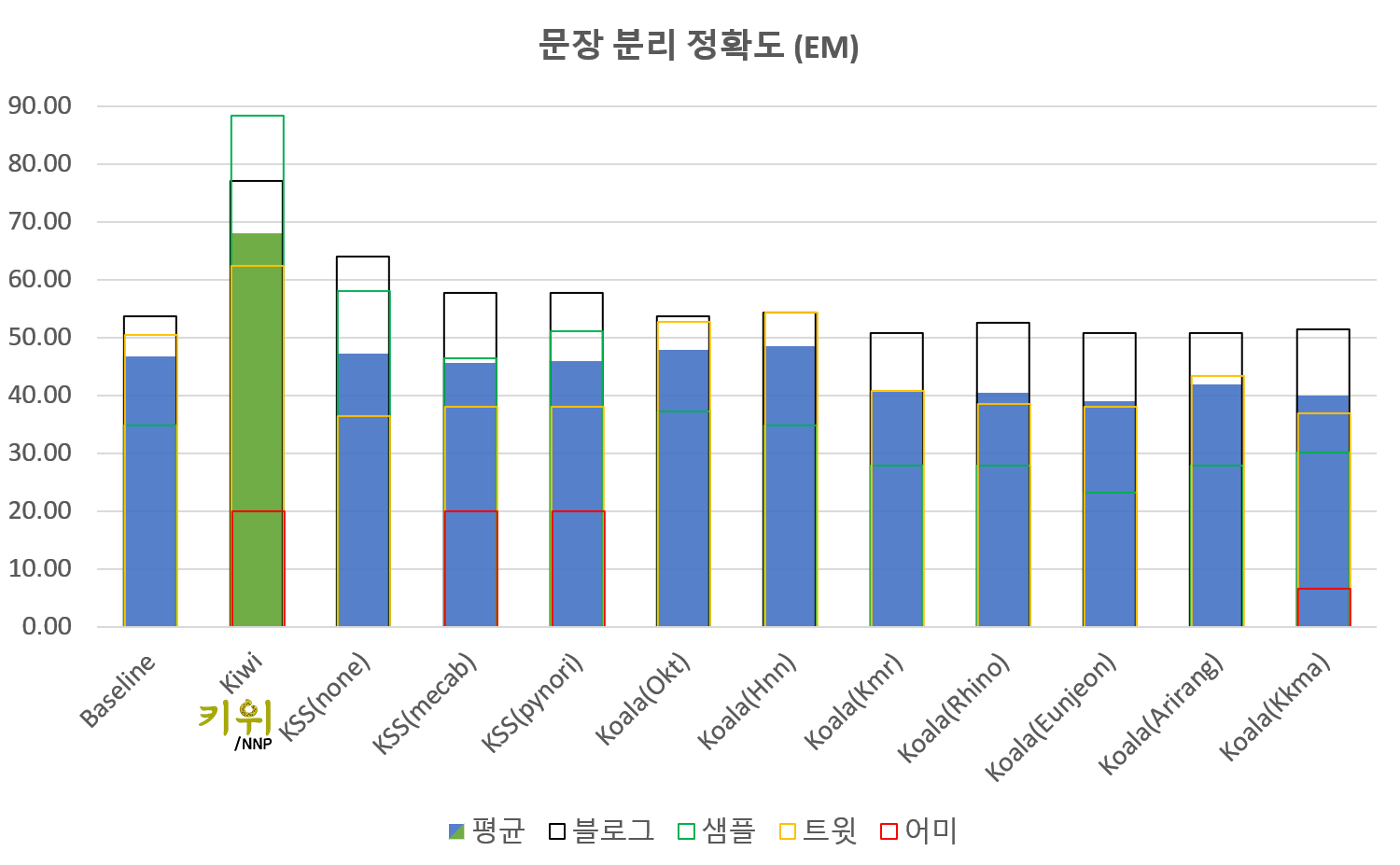
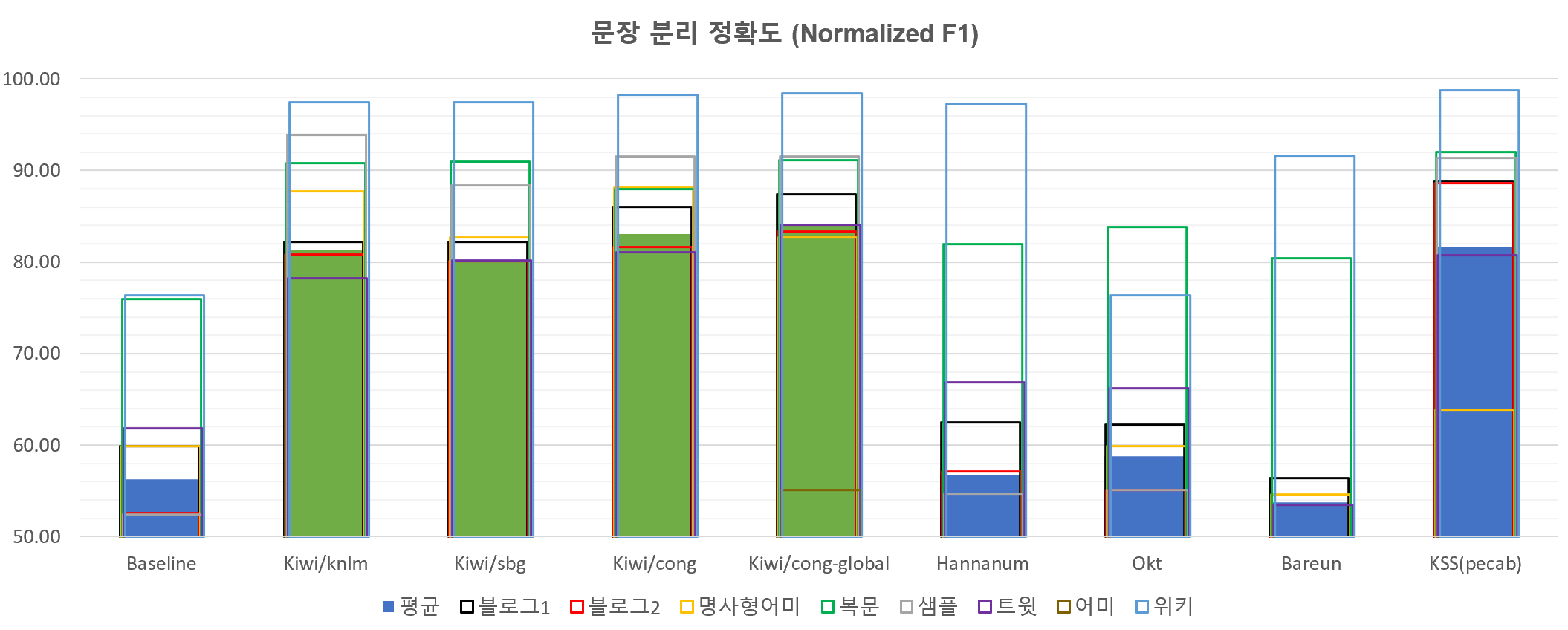

Kiwi가 비교적 빠르면서도 높은 정확도를 달성하고 있는 것을 확인할 수 있습니다. 다만 아직 전반적으로 부정확한 상황이라 앞으로 개선의 여지가 많습니다.
평가에 사용된 라이브러리 버전은 다음과 같습니다.
| Kiwi | KSS | Koala(Okt) | Koala(Hnn) | Koala(Kmr) | Koala(Rhino) | Koala(Eunjeon) | Koala(Arirang) | Koala(Kkma) |
|---|---|---|---|---|---|---|---|---|
| 0.19.0 | 3.4.2 | 2.1.4 | 2.1.4 | 2.1.4 | 2.1.5 | 2.1.6 | 2.1.4 | 2.1.4 |
$ python sentence_split.py testset/*.txt
======== Baseline Splitter ========
[Sentence Split Benchmark] Dataset: testset/blogs.txt
Gold: 170 sents, System: 151 sents, EM: 0.53529, F1: 0.66847, Normalized F1: 0.59884, Latency: 0.29 msec
[Sentence Split Benchmark] Dataset: testset/blogs_ko.txt
Gold: 346 sents, System: 243 sents, EM: 0.43642, F1: 0.55724, Normalized F1: 0.52607, Latency: 0.53 msec
[Sentence Split Benchmark] Dataset: testset/etn.txt
Gold: 39 sents, System: 26 sents, EM: 0.46154, F1: 0.59857, Normalized F1: 0.59857, Latency: 0.05 msec
[Sentence Split Benchmark] Dataset: testset/nested.txt
Gold: 91 sents, System: 104 sents, EM: 0.68132, F1: 0.85438, Normalized F1: 0.75991, Latency: 0.15 msec
[Sentence Split Benchmark] Dataset: testset/sample.txt
Gold: 43 sents, System: 26 sents, EM: 0.34884, F1: 0.52431, Normalized F1: 0.52431, Latency: 0.04 msec
[Sentence Split Benchmark] Dataset: testset/tweets.txt
Gold: 178 sents, System: 140 sents, EM: 0.51124, F1: 0.65446, Normalized F1: 0.61806, Latency: 0.16 msec
[Sentence Split Benchmark] Dataset: testset/v_ending.txt
Gold: 30 sents, System: 6 sents, EM: 0.00000, F1: 0.11359, Normalized F1: 0.11359, Latency: 0.03 msec
[Sentence Split Benchmark] Dataset: testset/wikipedia.txt
Gold: 326 sents, System: 267 sents, EM: 0.66258, F1: 0.76664, Normalized F1: 0.76379, Latency: 0.42 msec
======== Kiwi.split_into_sents ========
[Sentence Split Benchmark] Dataset: testset/blogs.txt
Gold: 170 sents, System: 176 sents, EM: 0.70588, F1: 0.88183, Normalized F1: 0.82171, Latency: 171.42 msec
[Sentence Split Benchmark] Dataset: testset/blogs_ko.txt
Gold: 346 sents, System: 344 sents, EM: 0.64162, F1: 0.85765, Normalized F1: 0.81316, Latency: 318.46 msec
[Sentence Split Benchmark] Dataset: testset/etn.txt
Gold: 39 sents, System: 39 sents, EM: 0.76923, F1: 0.88685, Normalized F1: 0.85661, Latency: 29.17 msec
[Sentence Split Benchmark] Dataset: testset/nested.txt
Gold: 91 sents, System: 95 sents, EM: 0.79121, F1: 0.95392, Normalized F1: 0.90797, Latency: 172.75 msec
[Sentence Split Benchmark] Dataset: testset/sample.txt
Gold: 43 sents, System: 44 sents, EM: 0.83721, F1: 0.93592, Normalized F1: 0.91465, Latency: 29.83 msec
[Sentence Split Benchmark] Dataset: testset/tweets.txt
Gold: 178 sents, System: 169 sents, EM: 0.70787, F1: 0.83580, Normalized F1: 0.79297, Latency: 104.42 msec
[Sentence Split Benchmark] Dataset: testset/v_ending.txt
Gold: 30 sents, System: 16 sents, EM: 0.23333, F1: 0.40282, Normalized F1: 0.37656, Latency: 16.79 msec
[Sentence Split Benchmark] Dataset: testset/wikipedia.txt
Gold: 326 sents, System: 333 sents, EM: 0.96933, F1: 0.99254, Normalized F1: 0.97473, Latency: 434.14 msec
kss_ref.py의 경우 backend 옵션을 제공합니다. [pecab, mecab, none] 중에 하나를 선택할 수 있습니다. 이에 대한 설명은 KSS 공식 저장소를 참조하세요.
$ python kss_ref.py testset/*.txt
[Sentence Split Benchmark] Dataset: testset/blogs.txt
Gold: 170 sents, System: 168 sents, EM: 0.87059, F1: 0.92162, Normalized F1: 0.88878, Latency: 8312.93 msec
[Sentence Split Benchmark] Dataset: testset/blogs_ko.txt
Gold: 346 sents, System: 330 sents, EM: 0.82659, F1: 0.90335, Normalized F1: 0.88605, Latency: 20854.73 msec
[Sentence Split Benchmark] Dataset: testset/etn.txt
Gold: 39 sents, System: 38 sents, EM: 0.46154, F1: 0.72488, Normalized F1: 0.63843, Latency: 637.50 msec
[Sentence Split Benchmark] Dataset: testset/nested.txt
Gold: 91 sents, System: 88 sents, EM: 0.86813, F1: 0.93012, Normalized F1: 0.92063, Latency: 6230.18 msec
[Sentence Split Benchmark] Dataset: testset/sample.txt
Gold: 43 sents, System: 40 sents, EM: 0.86047, F1: 0.91394, Normalized F1: 0.91394, Latency: 8644.43 msec
[Sentence Split Benchmark] Dataset: testset/tweets.txt
Gold: 178 sents, System: 159 sents, EM: 0.74157, F1: 0.82720, Normalized F1: 0.80771, Latency: 2766.56 msec
[Sentence Split Benchmark] Dataset: testset/v_ending.txt
Gold: 30 sents, System: 17 sents, EM: 0.36667, F1: 0.48153, Normalized F1: 0.48153, Latency: 448.44 msec
[Sentence Split Benchmark] Dataset: testset/wikipedia.txt
Gold: 326 sents, System: 323 sents, EM: 0.98160, F1: 0.98801, Normalized F1: 0.98801, Latency: 171493.01 msec
koalanlp_ref.py 역시 backend 옵션을 제공합니다. [OKT, HNN, KMR, RHINO, EUNJEON, ARIRANG, KKMA] 중 하나를 선택할 수 있으며, OKT, HNN의 경우 두 분석기가 자체적으로 제공하는 문장 분리 기능을 사용하고, 나머지의 경우 각 분석기로 형태소 분석 후 KoalaNLP에서 제공하는 문장 분리 기능을 사용합니다.
$ python koalanlp_ref.py testset/*.txt --backend=OKT
[koalanlp.jip] [INFO] Latest version of kr.bydelta:koalanlp-okt (2.1.4) will be used.
[root] Java gateway started with port number 10667
[root] Callback server will use port number 25334
[koalanlp.jip] JVM initialization procedure is completed.
[Sentence Split Benchmark] Dataset: testset/blogs.txt
Gold: 170 sents, System: 141 sents, EM: 0.53529, F1: 0.66847, Normalized F1: 0.62168, Latency: 66.48 msec
[Sentence Split Benchmark] Dataset: testset/blogs_ko.txt
Gold: 346 sents, System: 224 sents, EM: 0.43642, F1: 0.55724, Normalized F1: 0.55064, Latency: 82.07 msec
[Sentence Split Benchmark] Dataset: testset/etn.txt
Gold: 39 sents, System: 26 sents, EM: 0.46154, F1: 0.59857, Normalized F1: 0.59857, Latency: 22.24 msec
[Sentence Split Benchmark] Dataset: testset/nested.txt
Gold: 91 sents, System: 107 sents, EM: 0.79121, F1: 0.93010, Normalized F1: 0.83832, Latency: 56.54 msec
[Sentence Split Benchmark] Dataset: testset/sample.txt
Gold: 43 sents, System: 27 sents, EM: 0.37209, F1: 0.55109, Normalized F1: 0.55109, Latency: 6.44 msec
[Sentence Split Benchmark] Dataset: testset/tweets.txt
Gold: 178 sents, System: 145 sents, EM: 0.53371, F1: 0.69434, Normalized F1: 0.66198, Latency: 63.41 msec
[Sentence Split Benchmark] Dataset: testset/v_ending.txt
Gold: 30 sents, System: 6 sents, EM: 0.00000, F1: 0.11359, Normalized F1: 0.11359, Latency: 3.23 msec
[Sentence Split Benchmark] Dataset: testset/wikipedia.txt
Gold: 326 sents, System: 264 sents, EM: 0.65951, F1: 0.76639, Normalized F1: 0.76354, Latency: 104.33 msec
$ python koalanlp_ref.py testset/*.txt --backend=HNN
[koalanlp.jip] [INFO] Latest version of kr.bydelta:koalanlp-hnn (2.1.4) will be used.
[root] Java gateway started with port number 40435
[root] Callback server will use port number 25334
[koalanlp.jip] JVM initialization procedure is completed.
[Sentence Split Benchmark] Dataset: testset/blogs.txt
Gold: 170 sents, System: 151 sents, EM: 0.54118, F1: 0.69341, Normalized F1: 0.62515, Latency: 81.27 msec
[Sentence Split Benchmark] Dataset: testset/blogs_ko.txt
Gold: 346 sents, System: 241 sents, EM: 0.44220, F1: 0.59185, Normalized F1: 0.57098, Latency: 99.12 msec
[Sentence Split Benchmark] Dataset: testset/etn.txt
Gold: 39 sents, System: 26 sents, EM: 0.46154, F1: 0.59857, Normalized F1: 0.59857, Latency: 21.94 msec
[Sentence Split Benchmark] Dataset: testset/nested.txt
Gold: 91 sents, System: 114 sents, EM: 0.78022, F1: 0.94163, Normalized F1: 0.82031, Latency: 51.72 msec
[Sentence Split Benchmark] Dataset: testset/sample.txt
Gold: 43 sents, System: 27 sents, EM: 0.34884, F1: 0.54681, Normalized F1: 0.54681, Latency: 6.40 msec
[Sentence Split Benchmark] Dataset: testset/tweets.txt
Gold: 178 sents, System: 150 sents, EM: 0.54494, F1: 0.70350, Normalized F1: 0.66922, Latency: 61.29 msec
[Sentence Split Benchmark] Dataset: testset/v_ending.txt
Gold: 30 sents, System: 6 sents, EM: 0.00000, F1: 0.11359, Normalized F1: 0.11359, Latency: 3.42 msec
[Sentence Split Benchmark] Dataset: testset/wikipedia.txt
Gold: 326 sents, System: 328 sents, EM: 0.67791, F1: 0.98116, Normalized F1: 0.97286, Latency: 126.11 msecbareun_ref.py를 실행하면 바른 형태소 분석기의 문장 분리 성능을 평가할 수 있습니다. 이를 위해서는 먼저 바른 형태소 분석기를 설치하고 API Key를 받아야 합니다. 이에 대한 자세한 내용은 바른 형태소 분석기 공식 문서를 참조하세요.
$ python bareun_ref.py testset/*.txt --api_key=${YOUR_API_KEY}
[Sentence Split Benchmark] Dataset: testset/blogs.txt
Gold: 170 sents, System: 115 sents, EM: 0.42941, F1: 0.57341, Normalized F1: 0.56182, Latency: 821.68 msec
[Sentence Split Benchmark] Dataset: testset/blogs_ko.txt
Gold: 346 sents, System: 183 sents, EM: 0.36994, F1: 0.46045, Normalized F1: 0.45200, Latency: 1324.90 msec
[Sentence Split Benchmark] Dataset: testset/etn.txt
Gold: 39 sents, System: 23 sents, EM: 0.38462, F1: 0.51218, Normalized F1: 0.51218, Latency: 245.26 msec
[Sentence Split Benchmark] Dataset: testset/nested.txt
Gold: 91 sents, System: 89 sents, EM: 0.79121, F1: 0.88125, Normalized F1: 0.84130, Latency: 762.98 msec
[Sentence Split Benchmark] Dataset: testset/sample.txt
Gold: 43 sents, System: 5 sents, EM: 0.02326, F1: 0.07296, Normalized F1: 0.07296, Latency: 91.03 msec
[Sentence Split Benchmark] Dataset: testset/tweets.txt
Gold: 178 sents, System: 107 sents, EM: 0.35955, F1: 0.52089, Normalized F1: 0.51330, Latency: 760.96 msec
[Sentence Split Benchmark] Dataset: testset/v_ending.txt
Gold: 30 sents, System: 6 sents, EM: 0.00000, F1: 0.11359, Normalized F1: 0.11359, Latency: 87.74 msec
[Sentence Split Benchmark] Dataset: testset/wikipedia.txt
Gold: 326 sents, System: 303 sents, EM: 0.88344, F1: 0.91940, Normalized F1: 0.91940, Latency: 1411.05 msec