aws-liteis a simple, extremely fast, extensible AWS client for Node.js.(It's got good error reporting, too.)
This repo benchmarks and analyzes performance metrics from aws-lite, aws-sdk (v2), and @aws-sdk (v3) as unbundled and bundled dependencies. Control values are provided in a subset of relevant tests.
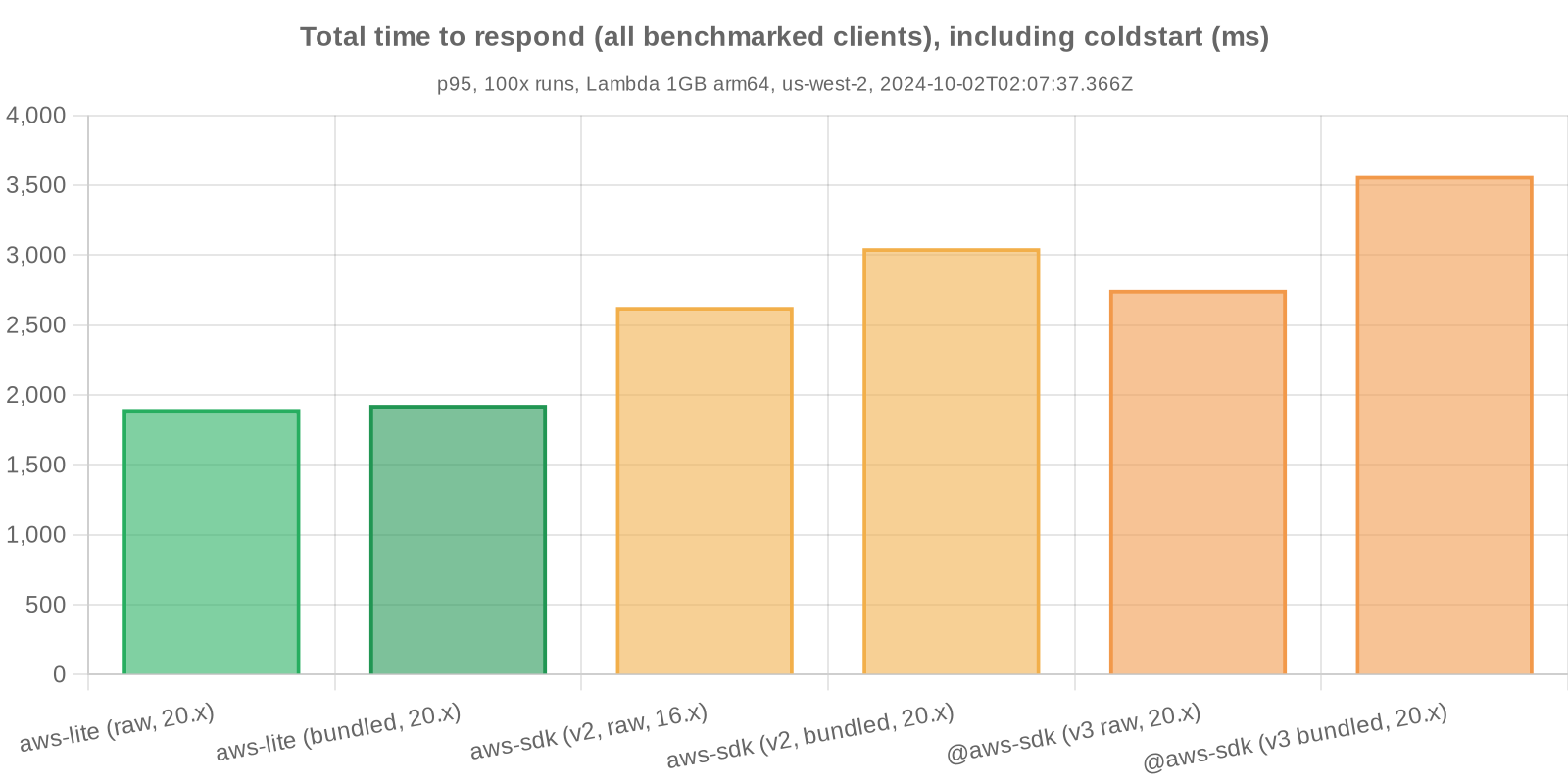
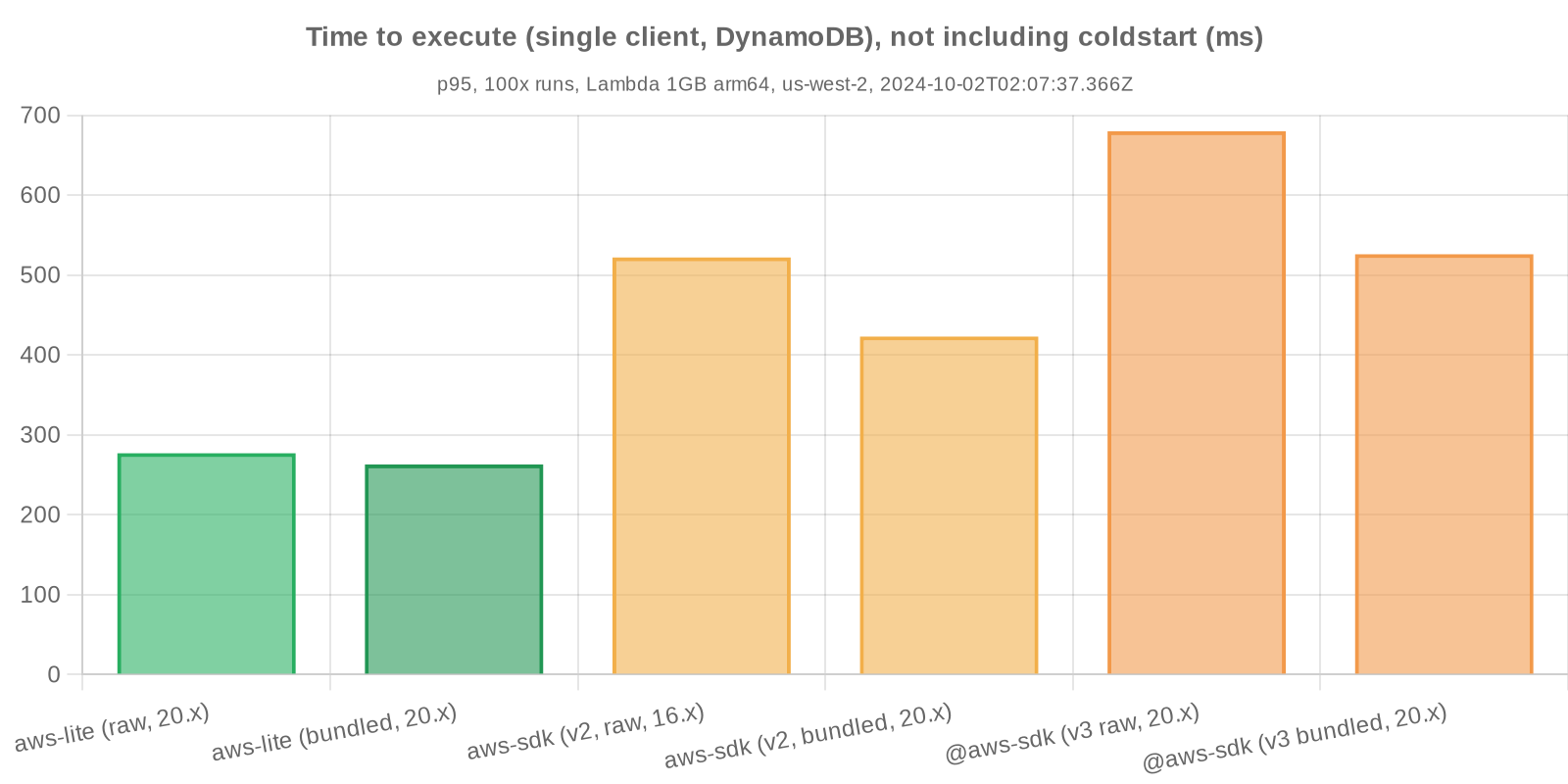
The performance metrics below represent timing and memory for a basic roundtrip operation in Lambda:
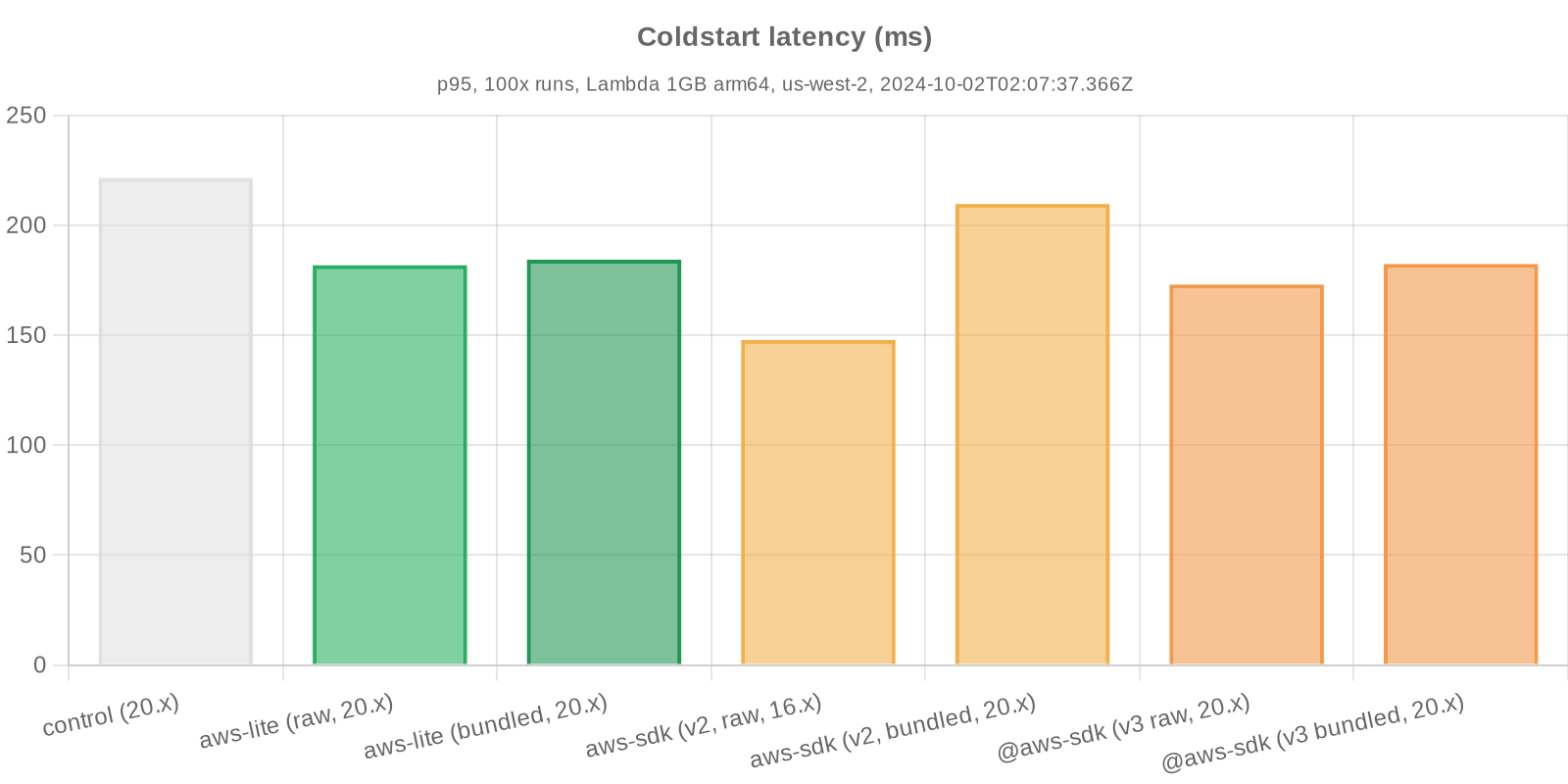
- Coldstart / initialization
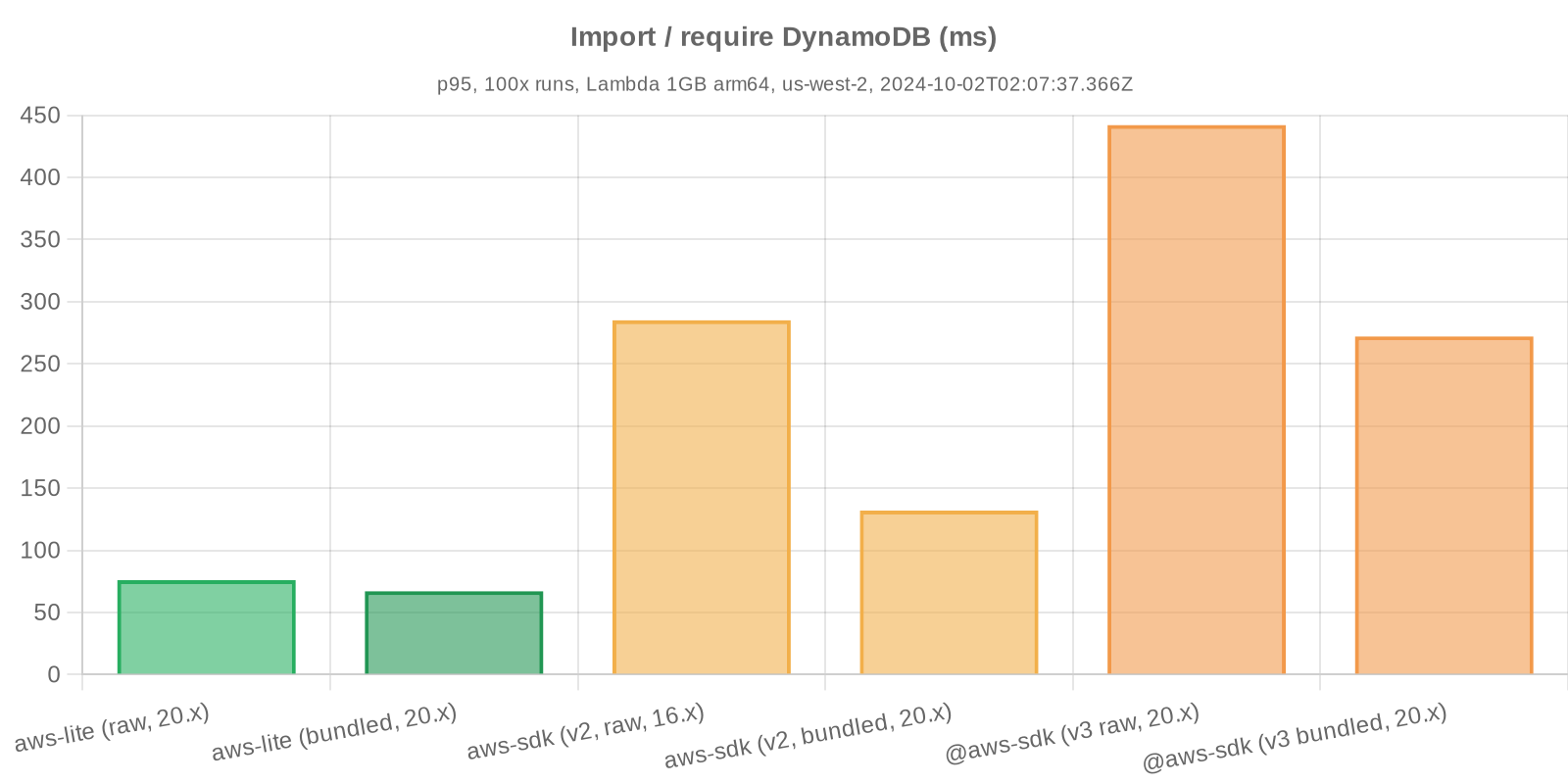
- Import SDK
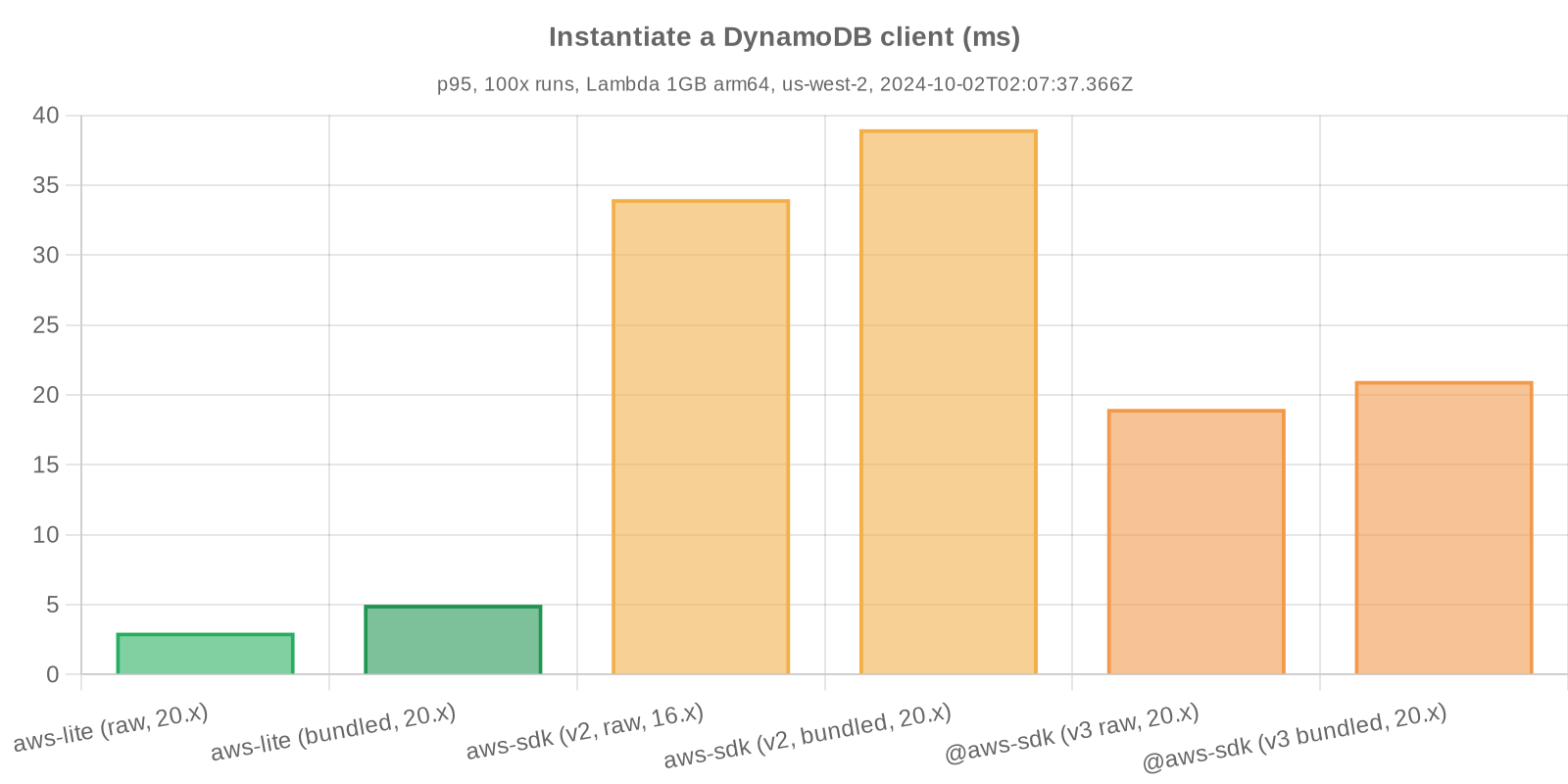
- Instantiate SDK client
- Perform read operation
- Perform write operation (as needed)
- Return metrics
Steps 2-5 are repeated sequentially for the various SDKs tested, currently: CloudFormation, DynamoDB, IAM, Lambda, S3, and STS.
Each test Lambda has only and exactly what it requires to complete the benchmark run; all extraneous dependencies and operations are removed.
Performance metrics are gathered on a regular basis to account for ongoing improvements to the SDKs (and, to a lesser extent, Lambda).
Note: import / require times are tied to individual services; in this example, only the DynamoDB service client is imported. Usage of additional AWS services in your own business logic would necessitate additional imports, thereby compounding response latency.

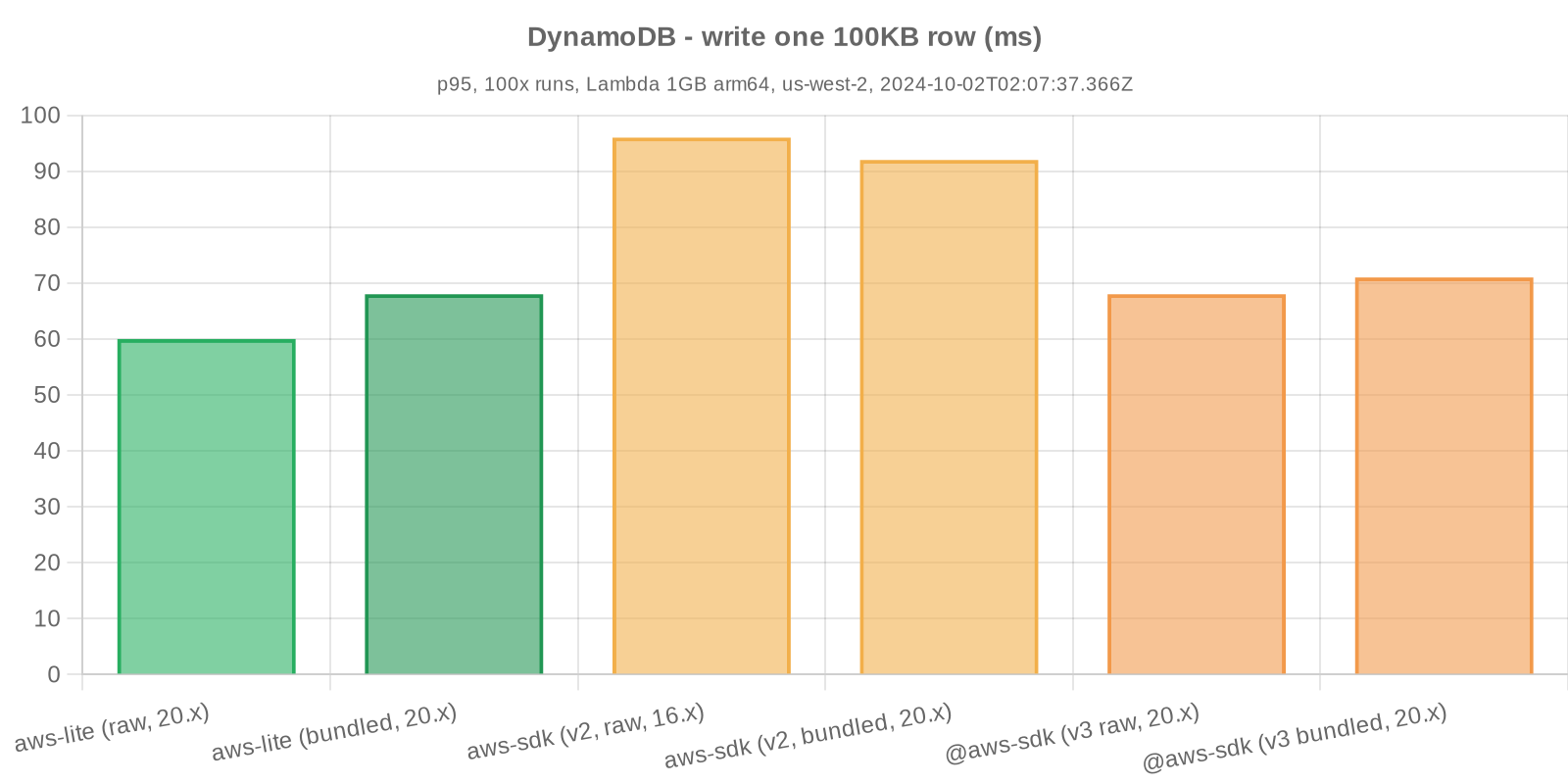
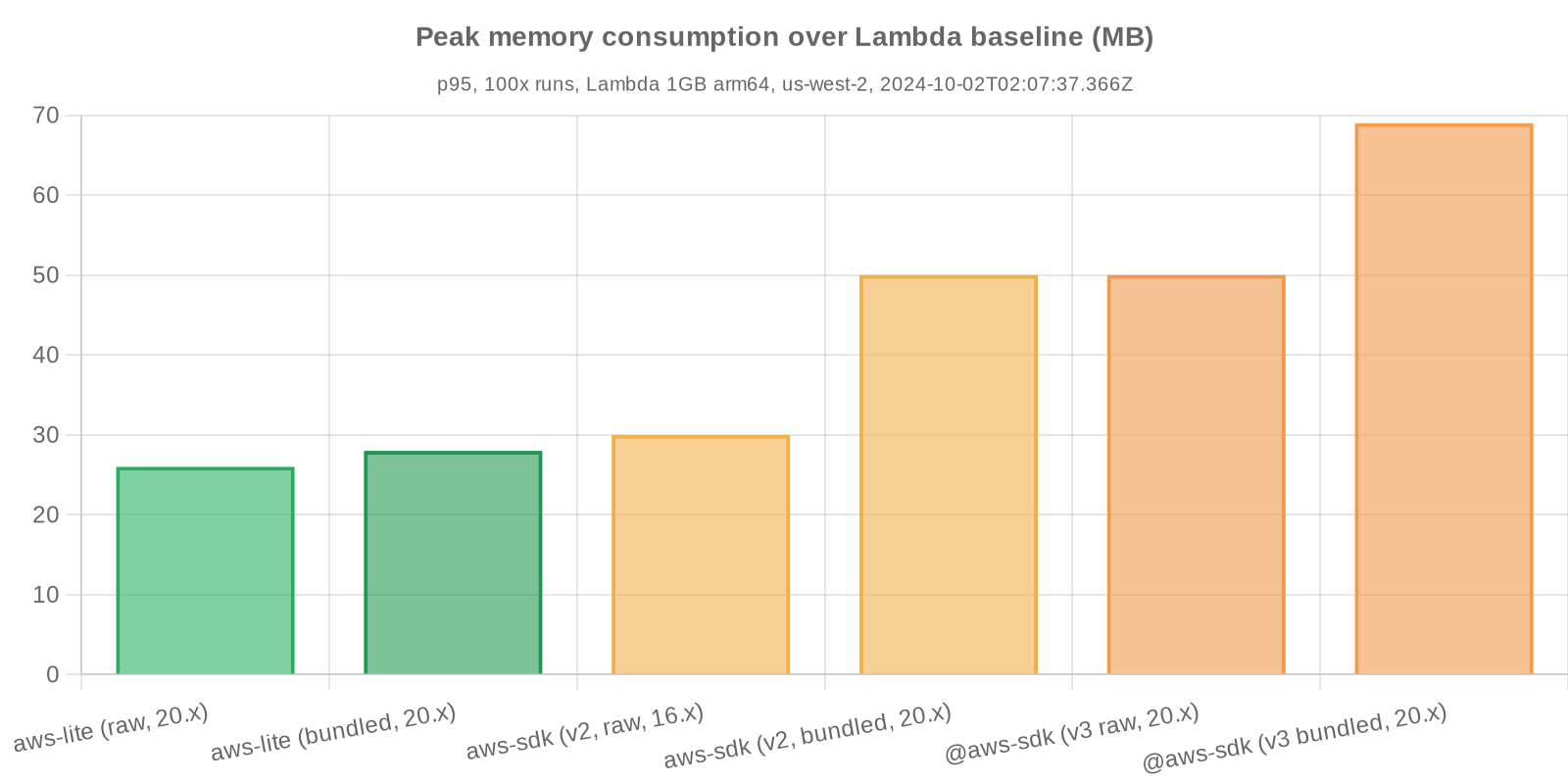
Note: peak memory consumption is shown as values above the Lambda Node.js baseline. Baseline memory consumption would be expected to include Node.js itself, Lambda bootstrap processes, etc. The memory baseline used always corresponds to the equivalent peak memory of the control test (e.g. aws-lite peak memory p95 - control peak memory p95).
Raw data from the benchmark runs that produced the above graphs can be downloaded here
We endeavor to take a straightforward and scientific approach to publishing AWS SDK performance data:
- Open - the code, techniques, reasoning, and findings of our tests should be open and available for anyone to review
- Real-world - our performance benchmarks should represent real-world usage patterns, avoiding contrived or trivial examples
- Reproducible - all results should be generally reproducible by others, whether using this repo's code and techniques or not
The process for benchmarking and processing performance metrics is run in the following phases and steps:
- Prep - a clean CI environment is instantiated; the latest versions of key dependencies (e.g.
@aws-lite/client,@aws-sdk/client-dynamodb, etc.) are installed; basic linting / tests are run - Hydration - the following SDK dependency scenarios are prepared:
- Raw, installed - a raw, unbundled dependency will be used; for
@aws-lite/*, that means the dependency will be installed and deployed with the code payload - Raw, provided - a raw, unbundled dependency provided by the Lambda container will be used (e.g.
@aws-sdk/*innodejs20.x) - Bundled - a bundled dependency will be used for comparison against the raw version; see bundling
- Raw, installed - a raw, unbundled dependency will be used; for
- Deployment - all scenario Lambdas (e.g.
control,aws-lite-raw, etc.) are deployed via@architect/architectvia AWS CloudFormation
- Prep - testing resources are created or updated as necessary, for example: a simple, flat 100KB row is written to the
dummy-dataDynamoDB database for DynamoDB client testing - Force coldstart - publish an update to each scenario Lambda's environment variables, forcing a coldstart
- Lambda invoke - invoke the Lambda, which runs through its prescribed operations
- Failures - all runs from all scenario Lambdas are required to complete; if any single invocation fatally errors, does not complete, or coldstart data cannot be found, the entire process fails and is retried
- Writing results - results are written to a DynamoDB database for possible future use / research, as well as to a JSON file to be published to S3
- Parsing - results are aggregated and parsed
- Charting - parsed data is passed to the chart generator, which stamps each chart with appropriate metadata (number of runs, date, etc.)
- Publishing - charts and raw data are published to a public S3 bucket
All scenario Lambdas share the same configuration: arm64 architecture; 1024 MB memory, all other default settings.
All Lambdas use nodejs20.x with the exception of the raw (provided) AWS SDK v2, which is only available provided in the nodejs16.x Lambda image.
AWS is deprecating AWS SDK v2 (and the Lambda Node.js runtimes that use it) in late 2023. Moving forward, developers will have to decide from the following options:
- Migrate to a new SDK (such as
aws-liteor AWS SDK v3) - Bundle AWS SDK v2 in its entirety and ship that as a (very large) vendored dependency
- Bundle individual AWS SDK v2 clients, and ship those as vendored dependencies
Putting aside the fact that AWS SDK v2 is deprecated and may only receive critical security updates for ~12mo, due to performance concerns we strongly advise against bundling the entirety of AWS SDK v2 as a vendored dependency.
Because we advise against bundling the entire v2 SDK, from a performance testing methodology perspective all bundled (read: not provided) AWS SDK v2 Lambda scenarios represented in this suite of metrics make use of individual bundled clients (e.g. aws-sdk/clients/dynamodb).
Once AWS finally deprecates nodejs16.x, the aws-sdk-v2-bundled Lambda scenario may be deprecated here as well, as we may no longer be able to publish changes to the application via CloudFormation.
The intention of this dataset is to provide an apples-to-apples comparison of the time and resource costs associated with JavaScript AWS SDKs. This can be reasonably accomplished within a single AWS region.
While it some degree of regional variability is to be expected, the goal is to test SDK performance, not regional performance. Given how the test suite operates, there is no reason to believe that a given SDK would demonstrate performance differences from region to region – in other words, while one region may have slightly faster Lambda hardware than another, that performance would be expected to impact all tests equally.
As such, at this time we feel that a single region can serve as a solid proxy for overall performance.1
We selected us-west-2 as, in our experience, it has been a highly reliable and performant region, which seems to get relatively early access to new features.
Bundled dependency scenarios are bundled with esbuild via simple entry files. The following settings are used platform: 'node', format: 'cjs'; for more detail, see the deployment plugin.
We encourage you to replicate these results. Assuming you have an AWS account and credentials with appropriate permissions (see Architect's AWS setup guide), run this same performance metric suite with the following steps:
- Pull down this repo
- Modify any AWS profile references to
openjsfto the appropriate AWS profile you'd like to use - Install dependencies:
npm i - Deploy the project to AWS:
npx arc deploy - Run the benchmarks and view the results:
npm run bench- To disable publishing results to a public S3 bucket, set a
DISABLE_PUBLISHenv var
- To disable publishing results to a public S3 bucket, set a
We'd like to acknowledge and thank the following people + projects in this space:
- Benchmarking the AWS SDK by AJ Stuyvenberg
cold-start-benchmarkerby AJ StuyvenbergSAR-measure-cold-startby Yan Cuidatadog-lambda-js- Reduce Lambda cold start times by Trivikram Kamat
Footnotes
-
AWS's own published SDK performance benchmarks also use the same single-region approach ↩