多目标跟踪是指在一段视频中同时跟踪多个目标的技术,是计算机视觉领域中的一个重要研究问题,也是研究其他高层任务(如动作识别,行为分析,行人重识别)的基础。由于行人是典型的非弹性形变物体,具有空间运动状态的复杂性和聚集行为,会引起复杂的遮挡关系,因此,以行人为对象对多目标跟踪技术提出了更大的挑战。行人多目标跟踪方法涉及行人位置自动初始化算法(如目标检测),行人目标特征描述策略及算法、在线或离线的目标轨迹优化算法等方面的领域知识。
本次比赛不提供有监督的数据集,仅仅提供多个场景采集得到的视频数据,要求选手通过无监督的学习方法训练模型。因此,我们首先分析了初赛无标注的训练视频的场景,分别如下:





首先我们将视频数据分为白天和夜间两种类别,将夜间视频与白天视频的比例作为训练过程中带权采样和图像数据增强的依据,其次由于摄像头拍摄角度广泛,景深较大,帧内包含了尺度不一的行人样本,近处的行人尺度较大,容易检测,而远处且带有遮挡性质的行人不易被检测到,这对我们选用检测模型设置了阻碍项。
- MOTA:多目标跟踪准确度(Multiple Object Tracking Accuracy),它是用来衡量单摄像头多目标跟踪准确度的一个指标,计算如下:
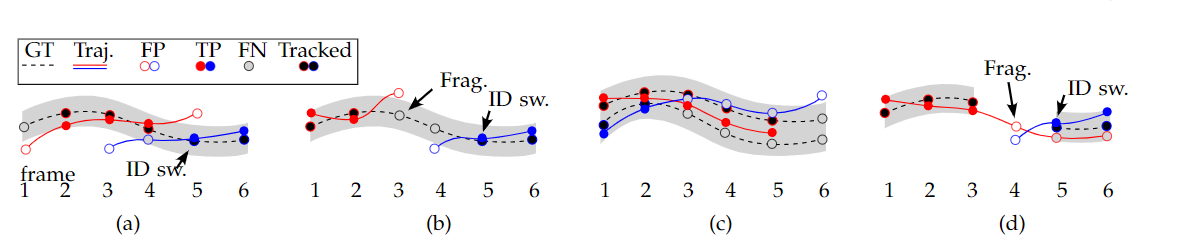
其中,FN为 False Negative(假的阴性,即为漏检样本),为整个视频中的漏检数量之和;FP为False Positive(假的阳性,即为误检样本),为整个视频误检数量之和;IDSW为ID Switch(ID交换次数,标志着错误匹配的次数);GT是Ground Truth物体的数量,为整段视频GT数量的和。在MOTA中的这三项依次表示漏检率,误检率,误匹配率,可以看出MOTA非常关注Tracking的性能,而和目标检测的精度无关。
- MOTP:多目标跟踪精确度(Multiple Object Tracking Precision),用以衡量单摄像头多目标跟踪位置误差的一个指标,计算如下:
-
MT:大多数匹配(Mostly Tracked):一条轨迹被跟踪到80%以上就可以认为是MT。需要注意的是,如果一条轨迹上的预测发生了ID Switch,但是综合来看,这条轨迹占到真实轨迹的80%以上,就依然认为是MT。
-
ML:大部分跟踪缺失(Mostly Lost),一条轨迹只被跟踪到20%以下就认为是ML。
-
FM:当一条轨迹从跟踪状态转换到未跟踪状态时,就对FM加一,换句话说,FM用来表示一条轨迹被切断的次数。
-
IDP:识别精确度(Identification Precision),指每个行人框中行人ID识别的精确度,计算如下:
其中,$IDTP$与$IDFP$分别表示真的正ID数目和假的正ID数目(误检),因此$IDP$表示的是ID识别的准确度。
- IDR:识别召回率(Identification Recall),指每个行人框中行人ID识别的召回率,计算公式如下:
其中,$IDFN$表示错的负ID数目(漏检),因此$IDR$表示了行人ID识别的召回率。
- IDF1:指每个行人框中行人ID识别的F1值,计算公式如下:
- CLANE(对比度受限的自适应直方图均衡):自适应直方图均衡化(AHE)用来提升图像的对比度的一种计算机图像处理技术。和普通的直方图均衡算法不同,AHE算法通过计算图像的局部直方图,然后重新分布亮度来改变图像对比度。因此,该算法更适合于改进图像的局部对比度以及获得更多的图像细节。AHE有过度放大图像中相同区域的噪音的问题,另外一种自适应的直方图均衡算法即限制对比度直方图均衡(CLAHE)算法,它能有限的限制这种不利的放大。由于视频中包含夜间场景,因此使用CLANE能够提升夜间场景的动态显示范围。
- 常规增强方式如翻转,转置,zoom in, zoom out;
- 针对于远处像素较少的行人的ROI+zoomin+Mixup,以增加较小目标下行人的样本数量;针对于靠近摄像头的近处的大目标行人的ROI+zoomout+Mixup,以增加较小目标下行人的样本数量;针对于近距离及中距离的行人的ROI+Mixup,以增加样本中的遮挡情形。
备选模型有:
(80类和20类)在COCO和PascalVOC上训练的双阶段的FasterRCNN, R-FCN, Cascade-RCNN
(80类和20类)在COCO和PascalVOC上训练的单阶段的SSD,yolov3, RetinaNet
(80类和20类)在COCO和PascalVOC上训练的anchor-free的FCOS
(2类)在CityPersons上训练的ALFNet,Reploss
为了得到纯度较高的训练样本标注结果,我们先使用80类模型下行人的检测结果进行融合,然后使用20类模型下行人的检测结果进行融合,进而将80类和20类的融合结果再进行一次融合,最后和2类模型进行融合,经过多次分层投票融合,得到了训练集的粗糙标注版本。
我们将得到的粗糙标注版本合并到COCO数据集的80类中一起进行训练Centernet,采样比例为1:4,训练的最小batch=20,并将COCO的验证集中行人类别的AP指标作为粗糙标注版本数据标注质量提升与否的标志。通过训练,得到此次比赛的无标注数据的标注,并在半监督的Centernet训练结束后,仅使用本次比赛的数据集对CenterNet再次进行训练。
在融合80个类别的FasterRCNN, R-FCN, Cascade-RCNN的结果时,使用IOU融合的方式去除存在重叠的多个框,在融合20个类别的FasterRCNN, R-FCN, Cascade-RCNN的结果时,使用IOU融合的方式去除存在重叠的多个框;在融合80个类别的SSD,yolov3, RetinaNet的结果时,使用IOU融合的方式去除存在重叠的多个框,在融合20个类别的SSD,yolov3, RetinaNet的结果时,使用IOU融合的方式去除存在重叠的多个框;
2.2.2 结果集成(WBF集成)
在融合80个类别的结果和20个类别的结果时,使用WBF充分使用所有检测框的置信度分数进行融合,在融合双阶段模型检测的结果,单阶段检测模型的结果以及anchor-free的模型的检测结果时,使用WBF充分使用所有检测框的置信度分数进行融合。
经过上述两种方法,对多个数据集,多种单双阶段模型的结果进行集成后,初步得到本次比赛训练集的粗糙标注结果。然后粗糙标注样本与COCO数据集进行混合(干净的数据来自于COCO,带有噪声的数据来自于上述集成模型的伪标注),每batch按照1:4的采样比例对centernet进行训练。使用centernet是因为anchor-free的centernet能够显著提高检测部分的速度,同时centernet在anchor-free的目标检测模型中,在速度和精度上取得了比较好的trade-off,检测结果要显著好于Yolov3,作为逐像素点预测bounding box的模型,centernet和Yolo系列的模型非常相似,但是却做到了anchor-free,在检测的细腻度上要好于yolo系列,对大目标和小目标的检测都比较好,因此使用了centernet作为最终跟踪模型的检测器部分。
使用干净数据和带标注噪声的数据对centernet在COCO上进行训练时,以COCO验证集中person的AP作为质量指标,以此反映半监督混合训练对含噪数据的去噪过程,使用余弦退火学习率进行学习率的调整,当标注数据被训练过程去噪时,保存标注结果,然后仅使用去完噪的数据再次对centernet进行训练微调。
| --arch | 'hourglass' |
|---|---|
| --input_res | 960 |
| --nms | True |
我们使用Focalloss训练Centernet的分类器,并分别训练了针对大类80个类别与小类2个类别的模型,仅关注person类别的AP。经过对比,使用Hourglass网络的情况下,使用80分类的模型要比使用2分类的模型有着更高的AP,最终在比赛中我们使用了COCO80个类别的模型来检测行人。经过分析,我们认为是有两个原因导致这种情况发生的。
- Focalloss和多分类的Softmax函数不同,Focalloss本质上仍然是在2分类器的基础上构建起来的,他是分别在优化80个二分类器,而不是在优化一个多分类器,也就是说在使用Focalloss对目标的heatmap进行优化的情况下,做2个类别的分类任务和80个类别的分类任务相比,要更加简单,因为80个类别的分类任务需要优化80个二分类器,它的优化约束要比2个类别的分类任务要严格。由于比赛中原始图片分辨率为$1920\times 1080$,在Dataset采样时我们已经将图片进行了resize,为了保证远处小目标行人的检出率,我们使用了降采样倍数小,但特征分辨率高的Hourglass网络作为检测网络的整体框架,而hourglass网络的参数量颇大,因此在较大网络中进行80分类出现过拟合的概率要低于使用大网络进行二分类。总结来看,80个类别的任务的AP高于2个类别的任务的原因在于2个类别的分类任务出现了轻微过拟合,而正负样本的严重不均衡更加剧了FN数目的增加。(或许采用较小的网络或者更少的训练时间可以缓解)
- 参与训练的数据中除了干净的COCO数据集外,还包括带有标注噪声的此次比赛的场景图,而标注噪声可以理解为避免使网络出现过拟合的正则化因子。80分类任务中,由于类别数多,因此存在于person类别中的标注噪声(FP)在训练过程中被其他类别样本逐渐矫正去噪时,person类的样本数量是减少了,但总体上被去噪的FP样本是被分摊在了其余79个类别中,总体来看训练集的样本分布不会产生更大的不均衡;而如果是在2分类任务中,带噪的样本被逐渐去除使,会加剧样本数目的不均衡,和非person类别的样本的数量相比,会让本身样本数目就少的person类别显得更少,这样形成的恶性循环使得person的检出量TP更低,而FN的数目会因为训练的恶化而逐渐增加。
总体而言,我们的方案思路是tracking-by-detection,因此检测成了MOT的重中之重,能够保证一个很好的检出率就能够让后续的tracking的匹配过程有材料可以操作,毕竟,巧妇难为无米之炊嘛。
- 检测:检测部分,我们使用了anchor-free的Centernet,它将图像中行人目标建模为高斯模板,用来表征目标存在与否,再配合一个尺度回归器来回归行人的长和宽,最终得到行人的检测结果。
- reid:由于Deep Sort在跟踪部分有着完善鲁棒的框架,我们需要在Deepsort的第一部分的级联匹配过程中通过度量学习提取行人检测框内的feature,这里使用了image-based的reid来提取特征,紧接着完成IOU匹配后,得到了初步的跟踪结果,然后使用Video-based的TACAN(文章发表于2020WACV)再次进行行人重识别以减少轨迹的FM和FN,以有效提升MOTA,减少ID Switch次数。
- 跟踪匹配:经典的Deepsort框架,使用卡尔曼滤波对轨迹进行操作,得到预测值,结合检测器的观测值,通过Embedding Level的级联贪婪匹配和IOU级别的快速匹配,快速跟踪目标。
以上就是本次无监督比赛的整体参赛方案,我们通过半监督学习得到了纯化过的训练集的伪标注训练了Anchor-free的Centernet,使用Deepsort做了初步的跟踪,然后使用video-based的行人重识别技术再次进行reid特征的提取,以提升MOTA,减少ID Switch和FN。
conda env create -f CenterNet.yml
pip install -r requirments.txt
80分类的hourglass网络的权重参数hourglass
80分类的DLA34网络的权重参数dla34
python demo_tracking.py
| 测试项目 | 速度 |
|---|---|
| 解析速度 | 17.86FPS |
| 检测速度 | 8.62FPS |
| 跟踪速度 | 20.41FPS |
| 整体速度 | 4.53FPS |
测试场景共有5个,包含一段夜间视频和4段白天视频,测试结果见1,4,5
@misc{zhou2019objects,
title={Objects as Points},
author={Xingyi Zhou and Dequan Wang and Philipp Krähenbühl},
year={2019},
eprint={1904.07850},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{wojke2017simple,
title={Simple Online and Realtime Tracking with a Deep Association Metric},
author={Nicolai Wojke and Alex Bewley and Dietrich Paulus},
year={2017},
eprint={1703.07402},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@INPROCEEDINGS {9093413,
author = {M. Li and H. Xu and J. Wang and W. Li and Y. Sun},
booktitle = {2020 IEEE Winter Conference on Applications of Computer Vision (WACV)},
title = {Temporal Aggregation with Clip-level Attention for Video-based Person Re-identification},
year = {2020},
volume = {},
issn = {},
pages = {3365-3373},
keywords = {feature extraction;training;task analysis;measurement;robustness;computational modeling;aggregates},
doi = {10.1109/WACV45572.2020.9093413},
url = {https://doi.ieeecomputersociety.org/10.1109/WACV45572.2020.9093413},
publisher = {IEEE Computer Society},
address = {Los Alamitos, CA, USA},
month = {mar}
}