The only way to find out is to try. Most likely you'll be able to improve performance with custom recipes. Domain knowledge and intuition are essential to getting the best possible performance.
- Look at the examples in this repository. Some illustrative samples:
- Transformer:
- Suppose you have a string column that has values like
"A:B:10:5", "A:C:4:10", .... It might make sense to split these values by ":" and create four output columns, potentially all numeric, such as[0,1,10,5], [0,2,4,10], ...to encode the information more clearly for the algorithm to learn better from. - PyTorch deep learning model for text similarity analysis, computes a similary score for any given two text input columns.
- ARIMA model for time-series forecasting.
- Data augmentation, such as replacing a zip code with demographic information, or replacing a date column with a National holiday flag.
- Suppose you have a string column that has values like
- Model:
- All H2O-3 Algorithms including H2O AutoML
- Yandex CatBoost gradient boosting
- A custom loss function for LightGBM or XGBoost
- Scorer:
- Maybe you want to optimize your predictions for the top decile for a regression problem..
- Maybe you care about the false discovery rate for a binary classification problem.
- Explainer:
- Create custom recipes for model interpretability, fairness, robustness, explanations
- Create custom plots, charts, markdown reports, etc.
Perfect. Relax and sit back. We'll keep making Driverless AI better and better with every version, so you don't have to. Several of the recipes in this repository will likely be included in future releases of Driverless AI out of the box, after more performance improvements and hardening.
You will get better at doing data science and you will get better results. Writing code is essential to improving your data science skills. Especially when writing data science code. Recipes are perfect for that.
Anyone who can or wants to. Mostly data scientists or developers. Some of the best recipes are trivial and make a big difference, like custom scorers.
A text editor. All you need is to create a .py text file containing source code.
- Examine the references below for the API specification and architecture diagrams.
- Look at the examples in this repository.
- Clone this repository and make modifications to existing recipes.
- Start an experiment and upload the recipe in the expert settings of an experiment.
Driverless AI uses Python version 3.6, so all custom recipes will run with Python 3.6 as well.
Driverless AI will tell you whether it makes the cut:
- First, it is subjected to acceptance tests. If it passes, great. If not, Driverless AI provides you with feedback on how to improve it.
- Then, you can choose to include it in your experiment(s). It will decide which recipes are best suited to solve the problem. At worst, you can cause the experiment to slow down.
- The easiest way (for now) is to keep uploading it to the expert settings in Driverless AI until the recipe is accepted.
- Another way is to do minimal changes as shown in this debugging example and use PyCharm or a similar Python debugger.
- Read the entire error message, it most likely contains the stack trace and helpful information on how to fix the problem.
- If you can't figure out how to fix the recipe, we suggest you post your questions in the Driverless AI community Slack channel
- You can also send us your experiment logs zip file, which will contain the recipe source files.
What happens if my transformer recipe doesn't lead to the highest variable importance for the experiment?
That's nothing to worry about. It's unlikely that your features have the strongest signal of all features. Even 'magic' Kaggle grandmaster features don't usually make a massive difference, but they still beat most of the competition.
- Don't give up. You learned something.
- Check the logs for failures if unsure whether the recipe worked at all or not.
- Driverless AI will ignore recipe failures unless this robustness feature is specifically disabled. Under Expert Settings, disable
skip_transformer_failuresandskip_model_failuresif you want to fail the experiment on any unexpected errors due to custom recipes. - Inside the experiment logs zip file, there's a folder called
detailsand if it contains.stackfiles with stacktraces referring to your custom code, then you know it bombed.
If you can hook it up to Python, then yes. We have many recipes that use Java and C++ backends. Most of Driverless AI uses C++ backends.
No. Same code base. No performance penalty. No calling overhead. Same inputs and outputs.
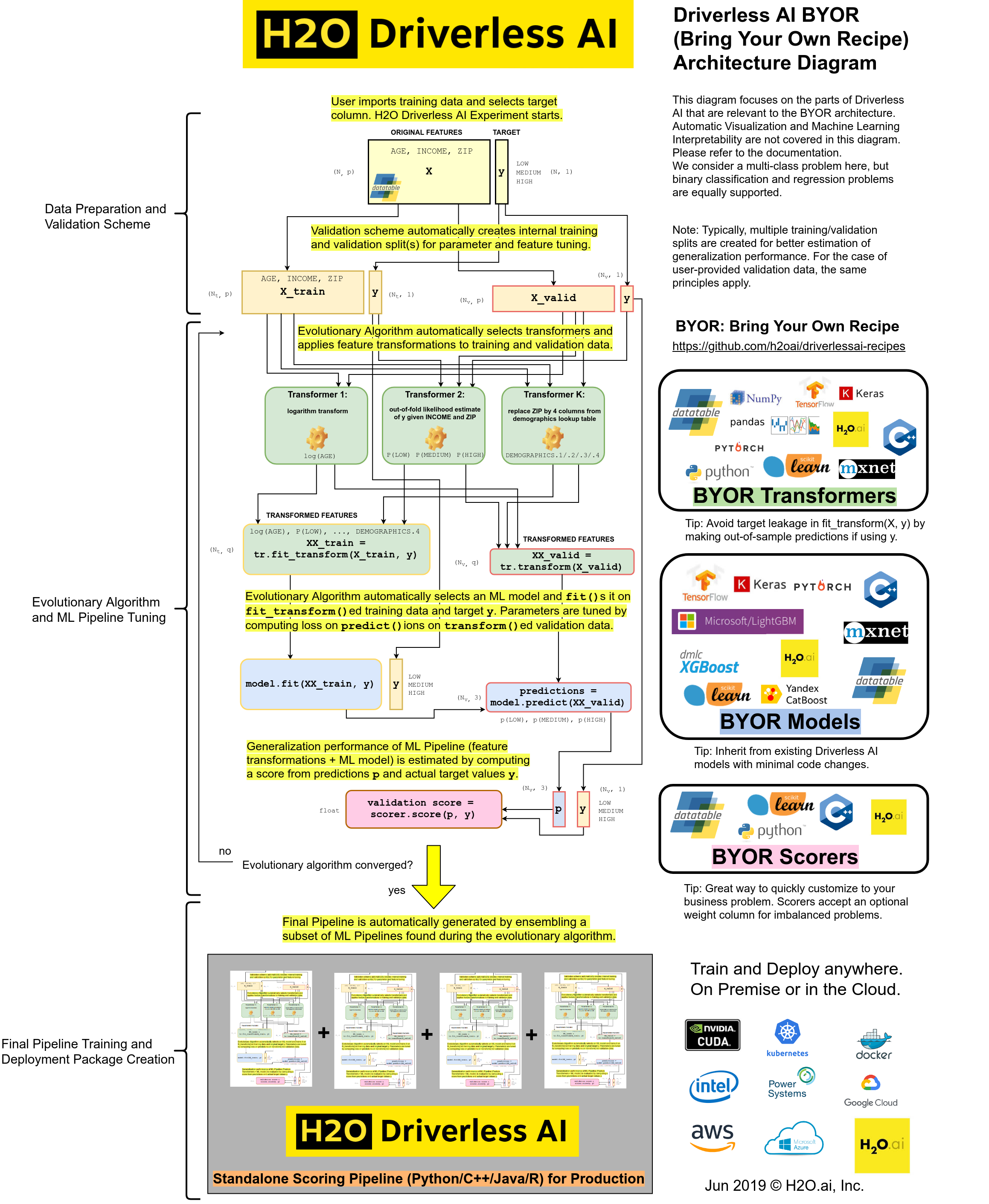
Separating of work. With the transformer API, we can replace only the particular input column(s) with out-of-fold estimates of the target column. All other columns (features) can be processed by other transformers. The combined union of all features is then passed to the model(s) which can yield higher accuracy than a model that only sees the particular input column(s). For more information about the flow of data, see the technical references section.
Recipes are meant to be built by people you trust and each recipe should be code-reviewed before going to production. If you don't want custom code to be executed by Driverless AI, set enable_custom_recipes=false in the config.toml, or add the environment variable DRIVERLESS_AI_ENABLE_CUSTOM_RECIPES=0 at startup of Driverless AI. This will disable all custom transformers, models and scorers. If you want to keep all previously uploaded recipes enabled and disable the upload of any new recipes, set enable_custom_recipes_upload=false or DRIVERLESS_AI_ENABLE_CUSTOM_RECIPES_UPLOAD=0 at startup of Driverless AI.
If you upload a new version of a recipe, it will become the new default version for that recipe. Previously run experiments using older versions of that recipe will continue to work, and use the older version. New experiments will use the new version.
Everyone with access to the Driverless AI instance can run all recipes, even if they were uploaded by someone else. Recipes remains on the instance that runs Driverless AI. Experiment logs may contain relevant information about your recipes (such as their source code), so double-check before you share them.
If you really need to delete all recipes, you can delete the contrib folder inside the data_directory (usually called tmp) and restart Driverless AI. Caution: Previously created experiments using custom recipes will not be able to make predictions any longer, so this is not recommended unless you also delete all related experiments as well.
In most cases (especially for complex recipes), MOJOs won’t be available out of the box. But, it is possible to get the MOJO. Contact [email protected] for more information about creating MOJOs for custom recipes. (Note: The Python Scoring Pipeline features full support for custom recipes.)
We encourage you to share your recipe in this repository. If your recipe works, please make a pull request and improve the experience for everyone!
- sklearn API
- Implement
fit_transform(X, y)for batch transformation of the training data - Implement
transform(X)for row-by-row transformation of validation and test data
- Implement
- Custom Transformer Recipe SDK/API Reference
- Using datatable
- sklearn API
- Implement
fit(X, y)for batch training on the training data - Implement
predict(X)for row-by-row predictions on validation and test data
- Implement
- Custom Model Recipe SDK/API Reference
- sklearn API
- Implement
score(actual, predicted, sample_weight, labels)for computing scores and metrics from predictions and actual values
- Implement
- Custom Scorer Recipe SDK/API Reference

{kind=link}
Webinar: Extending the H2O Driverless AI Platform with Your Recipes Website: H2O Driverless AI Recipes