diff --git a/.nojekyll b/.nojekyll
index 3019752..91e682b 100644
--- a/.nojekyll
+++ b/.nojekyll
@@ -1 +1 @@
-7c0a989e
\ No newline at end of file
+075003d9
\ No newline at end of file
diff --git a/search.json b/search.json
index c191fbc..22b6a69 100644
--- a/search.json
+++ b/search.json
@@ -102,7 +102,7 @@
"href": "tutorials/data-access/earthdata-search.html",
"title": "Earthdata Search",
"section": "",
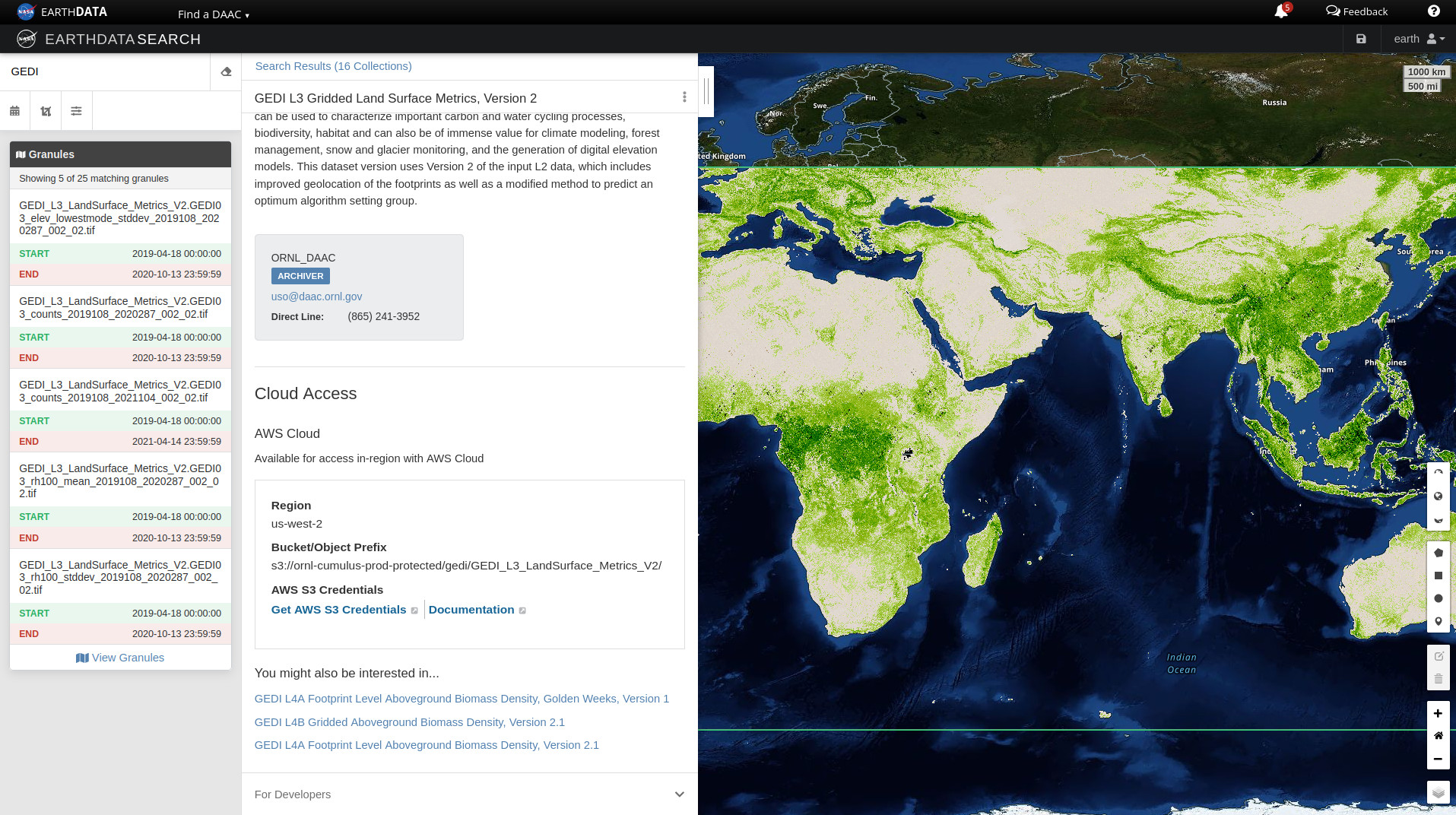
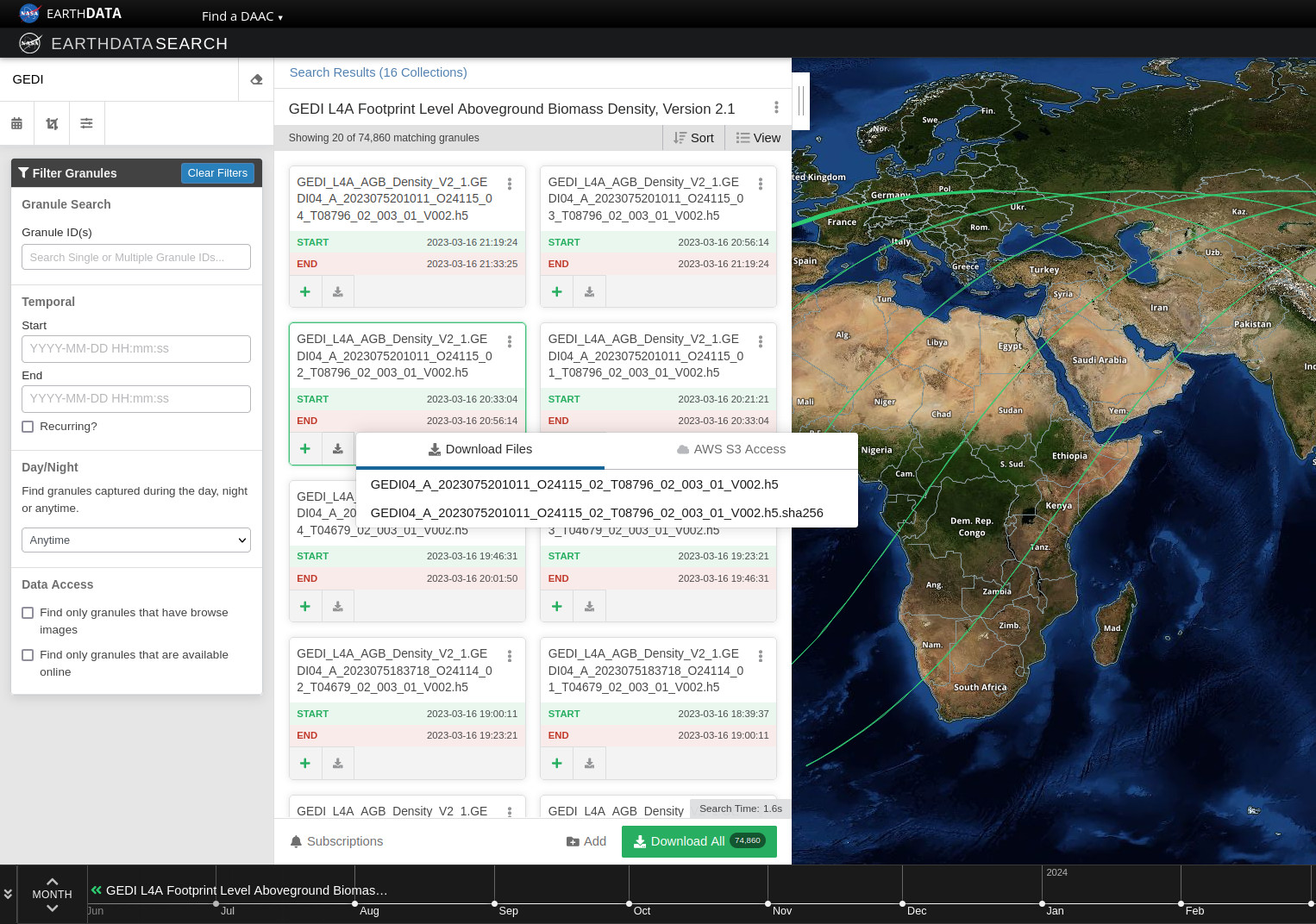
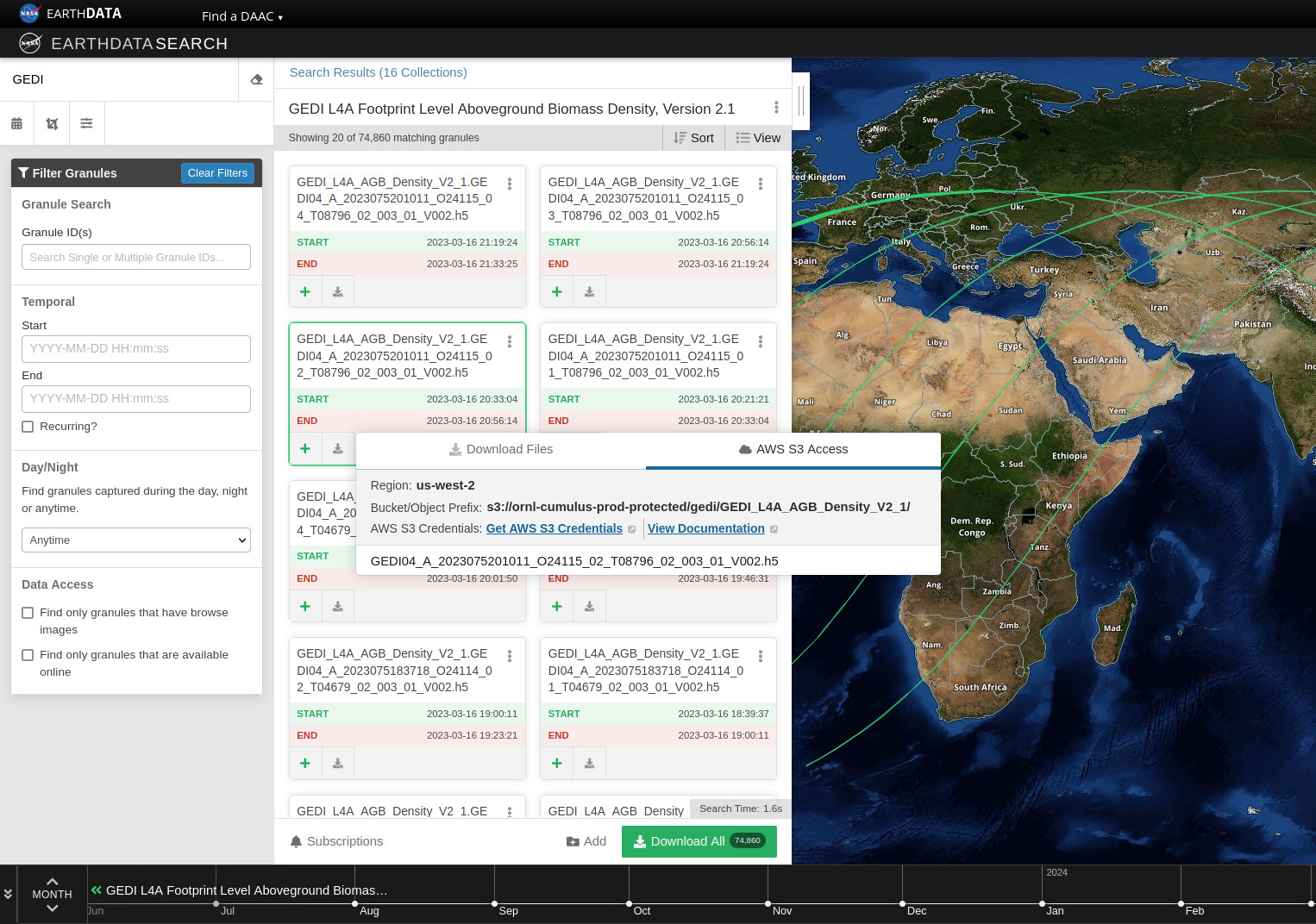
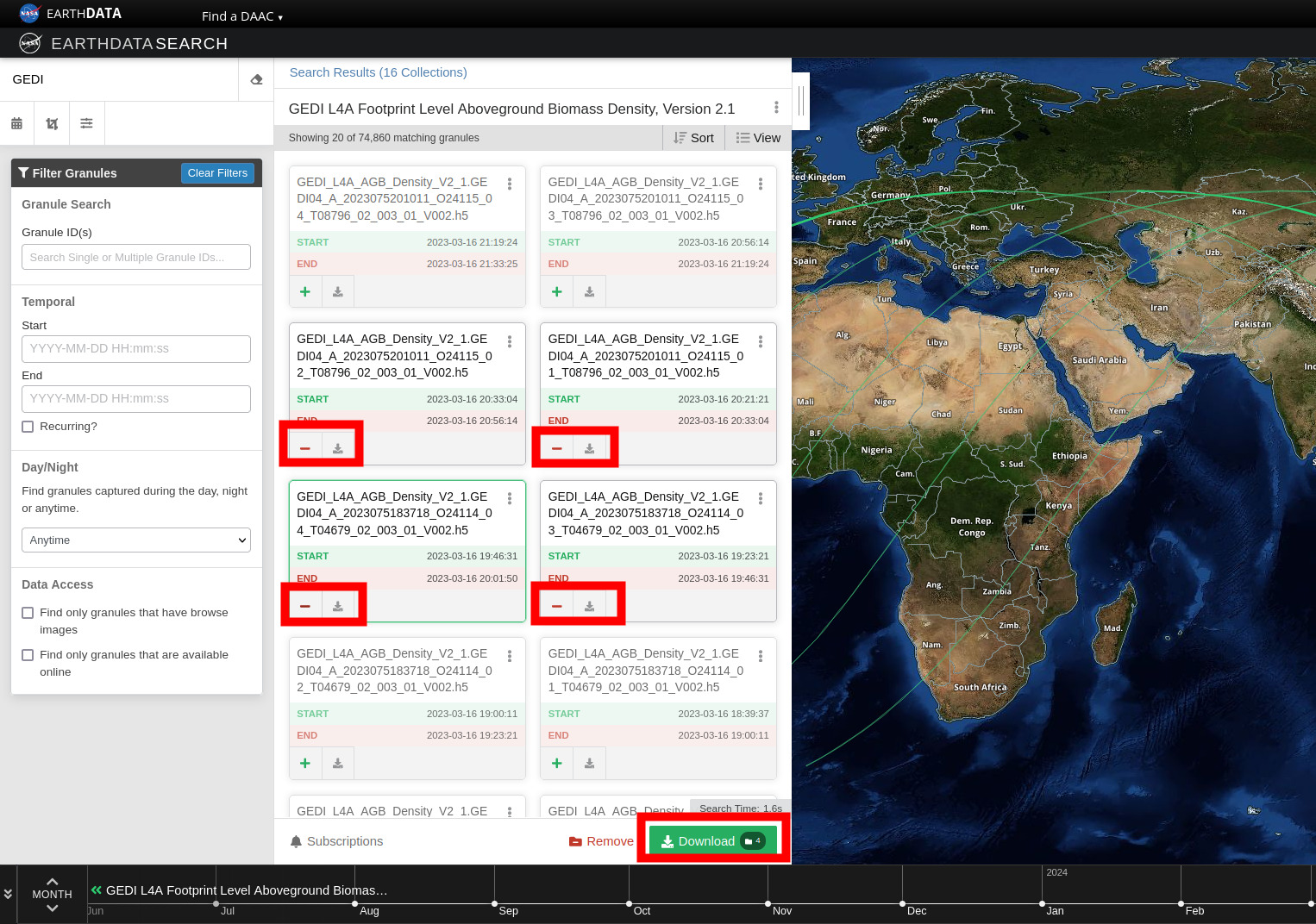
- "text": "Earthdata Search\nThis tutorial guides you through how to use Earthdata Search for NASA Earth observations search and discovery, and how to connect the search output (e.g. download or access links) to a programmatic workflow (locally or from within the cloud).\n\nStep 1. Go to Earthdata Search and Login\nGo to Earthdata Search https://search.earthdata.nasa.gov and use your Earthdata login credentials to log in. If you do not have an Earthdata account, please see the Workshop Prerequisites for guidance.\n\n\nStep 2. Search for dataset of interest\nUse the search box in the upper left to type key words. In this example we are interested in the GEDI or ICESAT-2 which is managed by the LP DAAC and made available from the NASA Earthdata Cloud archive hosted in AWS cloud.\nType GEDI in the search bar Click on the “Available from AWS Cloud” filter option on the left.\nWe can click on the (i) icon for the dataset to read more details, including the dataset shortname (helpful for programmatic workflows) just below the dataset name; here ECO_L2T_LSTE.\n\n\nStep 3. Explore the dataset details, including Cloud Access information\nOnce we clicked the (i), scrolling down the info page for the dataset we will see Cloud Access information, such as:\n\nwhether the dataset is available in the cloud\n\nthe cloud Region (all NASA Earthdata Cloud data is/will be in us-west-2 region)\n\nthe S3 storage bucket and object prefix where this data is located\n\nlink that generates AWS S3 Credentials for in-cloud data access (we will cover this in the Direct Data Access Tutorials)\n\nlink to documentation describing the In-region Direct S3 Access to Buckets. Note: these will be unique depending on the DAAC where the data is archived. (We will show examples of direct in-region access in Tutorial 3.)\n\n\n\n\nFigure caption: Cloud access info in EDS\n\n\n\n\n\nFigure caption: Documentation describing the In-region Direct S3 Access to Buckets\n\n\nNote: Clicking on “For Developers” to exapnd will provide programmatic endpoints such as those for the CMR API, and more.\nFor now, let’s say we are intersted in getting download link(s) or access link(s) for specific data files (granules) within this collection.\nAt the top of the dataset info section, click on Search Results, which will take us back to the list of datasets matching our search parameters. Clicking on the dataset (ECOSTRESS ECO_L2T_LSTE) we now see a list of files (granules) that are part of the dataset (collection).\n\n\nStep 4a. Download or data access for a single granule\nTo download files for a granule click the download arrow on the card (or list row)\n\n\n\nFigure caption: Download granules\n\n\nYou can also get the S3 information (e.g., AWS region, bucket, temperary credentials for S3 access, and file names) by selecting the AWS S3 Access tab.\n\n\n\nFigure caption: S3 access for granules\n\n\n\nStep 4b. Download or data access for multiple granule\nTo download multiple granules, click on the green + symbol to add files to our project. Click on the green button towards the bottom that says “Download”. This will take us to another page with options to customize our download or access link(s).\n\n\n\nFigure caption: Select granules and click download\n\n\nOn the next page click the Direct Download option and click the green Download Data on the bottom left side of the page.\n\n\n\nFigure caption: Direct download multiple granules\n\n\nWe’re now taked to the final page for instructions to download and links for data access in the cloud. You should see three tabs: Download Files, AWS S3 Access, Download Script:\n\n\n\nFigure caption: Download to local\n\n\n\n\n\nFigure caption: Direct S3 access\n\n\nThe Download Files tab provides the https:// links for downloading the files locally\nThe AWS S3 Access tab provides the S3:// links, which is what we would use to access the data directly in-region (us-west-2) within the AWS cloud."
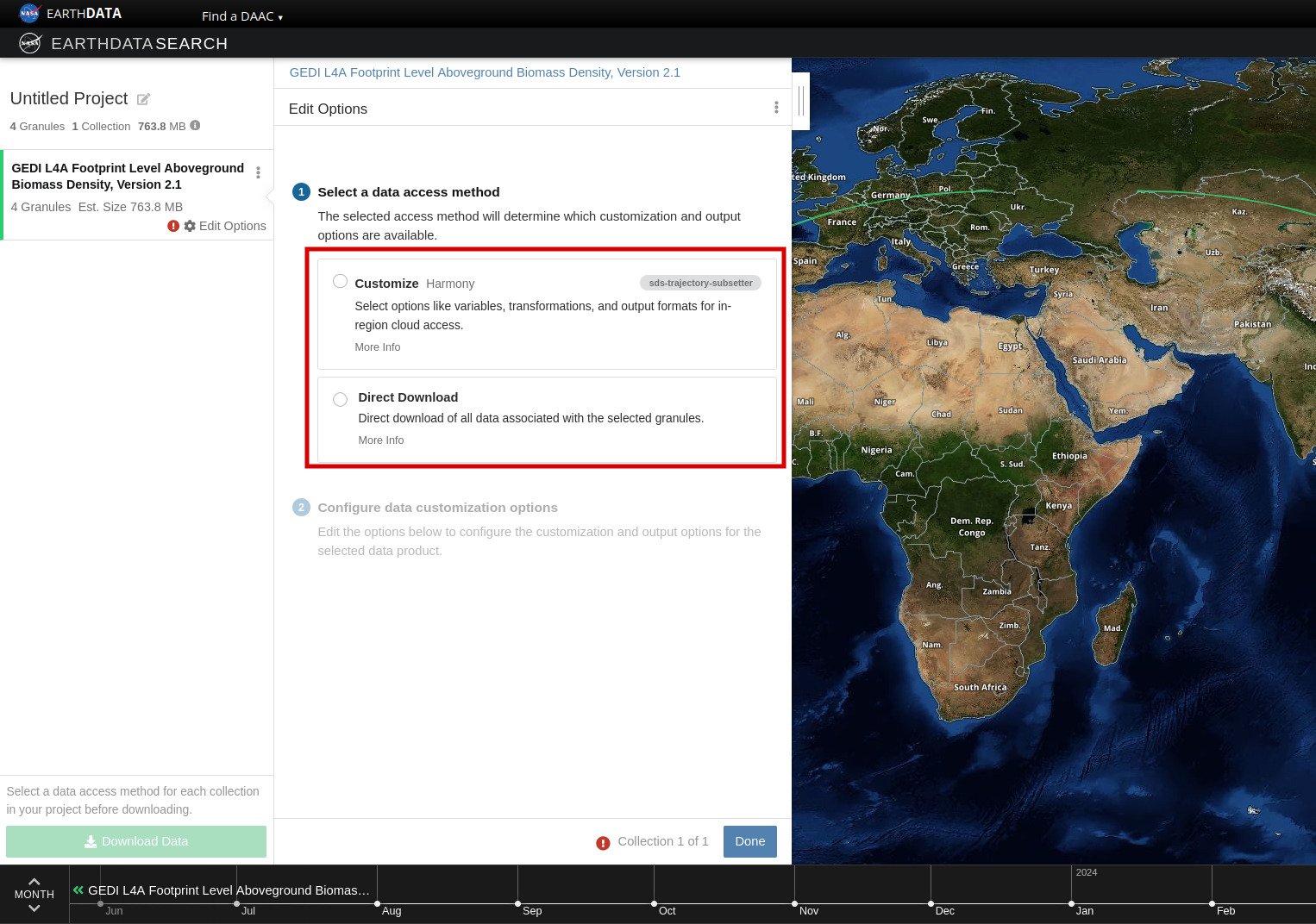
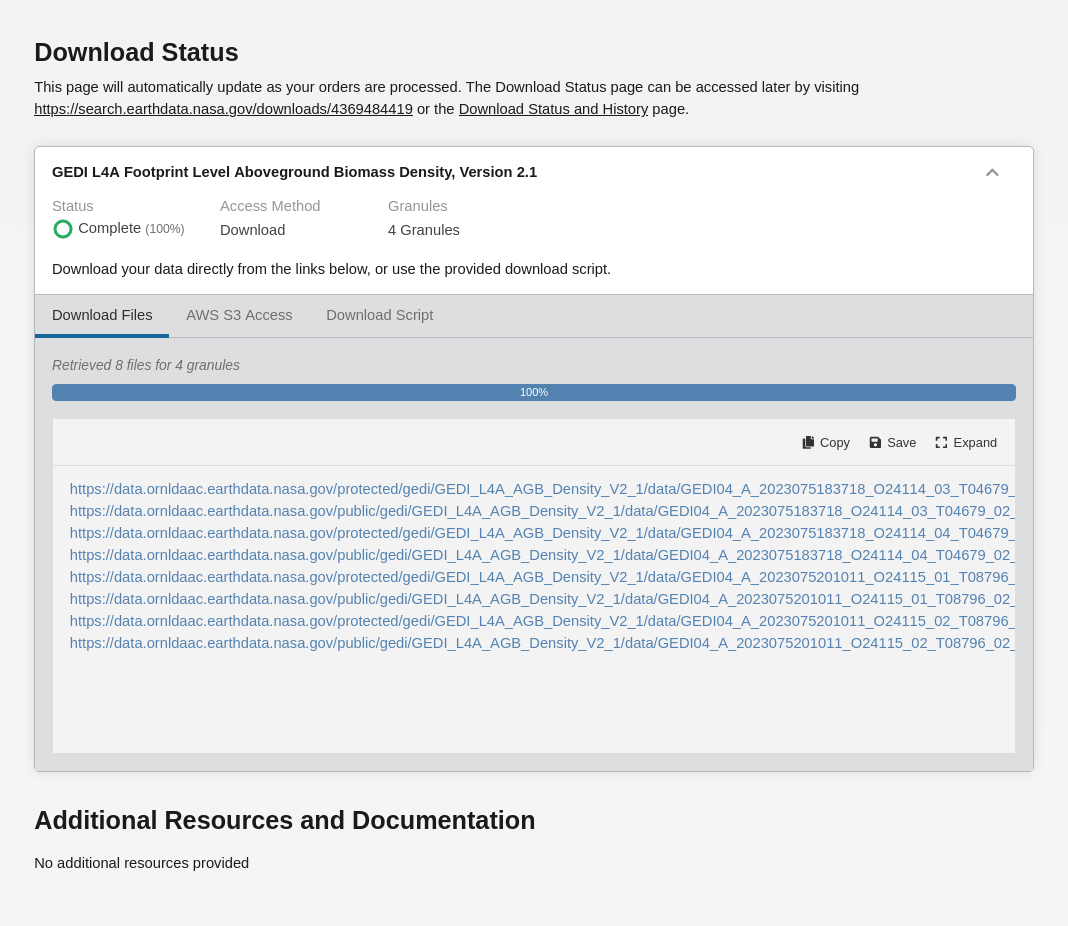
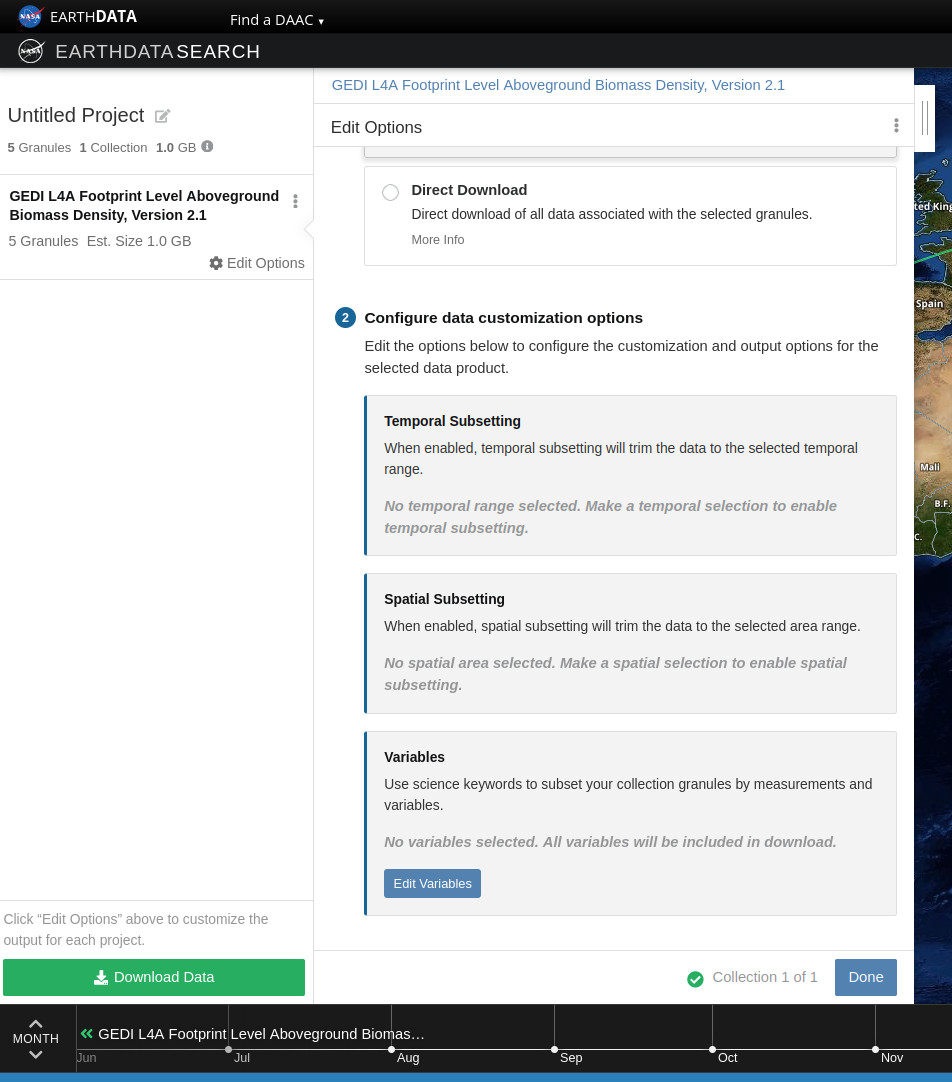
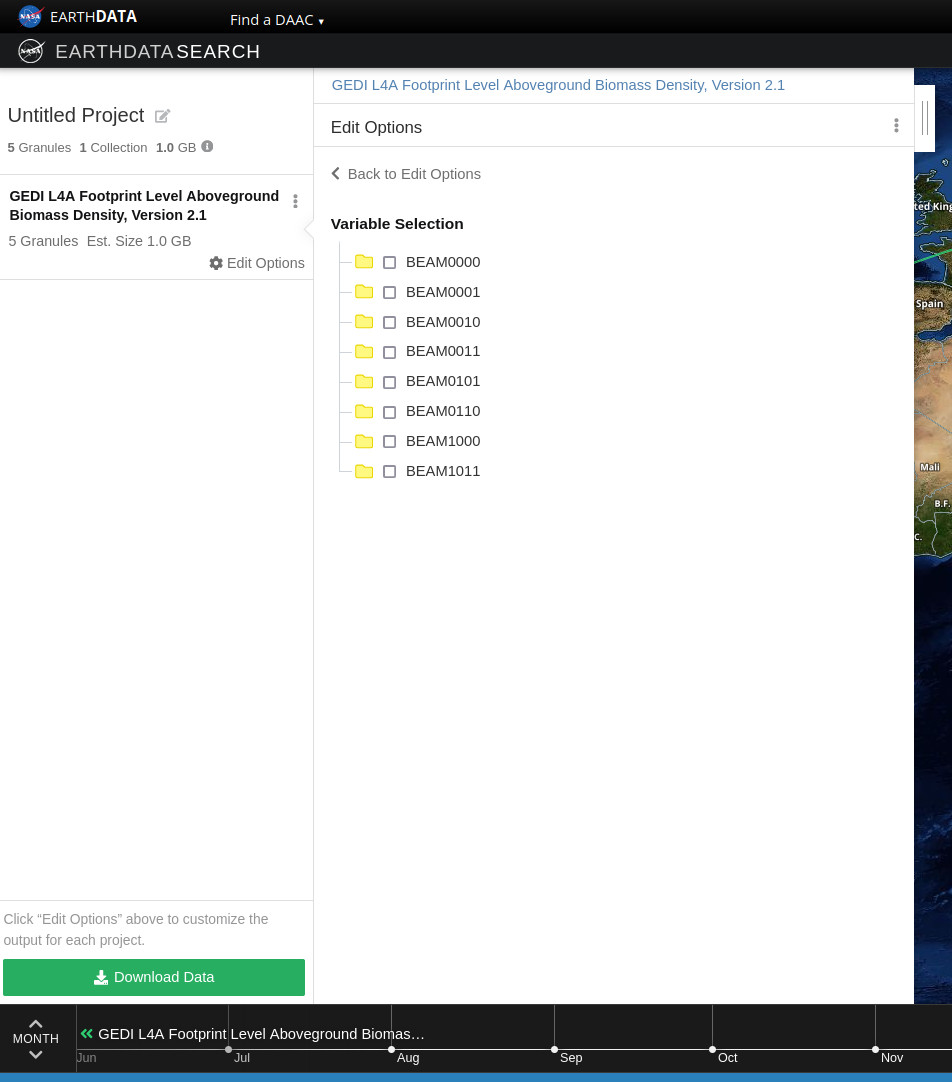
+ "text": "Earthdata Search\nThis tutorial guides you through how to use Earthdata Search for NASA Earth observations search and discovery, and how to connect the search output (e.g. download or access links) to a programmatic workflow (locally or from within the cloud).\n\nStep 1. Go to Earthdata Search and Login\nGo to Earthdata Search https://search.earthdata.nasa.gov and use your Earthdata login credentials to log in. If you do not have an Earthdata account, please see the Workshop Prerequisites for guidance.\n\n\nStep 2. Search for dataset of interest\nUse the search box in the upper left to type key words. In this example we are interested in the GEDI or ICESAT-2 which is managed by the LP DAAC and made available from the NASA Earthdata Cloud archive hosted in AWS cloud.\nType GEDI in the search bar Click on the “Available from AWS Cloud” filter option on the left.\nWe can click on the (i) icon for the dataset to read more details, including the dataset shortname (helpful for programmatic workflows) just below the dataset name; here we are using a keyword GEDI.\n\n\nStep 3. Explore the dataset details, including Cloud Access information\nOnce we clicked the (i), scrolling down the info page for the dataset we will see Cloud Access information, such as:\n\nwhether the dataset is available in the cloud\n\nthe cloud Region (all NASA Earthdata Cloud data is/will be in us-west-2 region)\n\nthe S3 storage bucket and object prefix where this data is located\n\nlink that generates AWS S3 Credentials for in-cloud data access (we will cover this in the Direct Data Access Tutorials)\n\nlink to documentation describing the In-region Direct S3 Access to Buckets. Note: these will be unique depending on the DAAC where the data is archived. (We will show examples of direct in-region access in Tutorial 3.)\n\n\n\n\nFigure caption: Documentation describing the In-region Direct S3 Access to Buckets\n\n\nNote: Clicking on “For Developers” to exapnd will provide programmatic endpoints such as those for the CMR API, and more.\nFor now, let’s say we are intersted in getting download link(s) or access link(s) for specific data files (granules) within this collection.\nAt the top of the dataset info section, click on Search Results, which will take us back to the list of datasets matching our search parameters. Clicking on the dataset (ECOSTRESS ECO_L2T_LSTE) we now see a list of files (granules) that are part of the dataset (collection).\n\n\nStep 4a. Download or data access for a single granule\nTo download files for a granule click the download arrow on the card (or list row)\n\n\n\nFigure caption: Download granules\n\n\nYou can also get the S3 information (e.g., AWS region, bucket, temperary credentials for S3 access, and file names) by selecting the AWS S3 Access tab.\n\n\n\nFigure caption: S3 access for granules\n\n\n\nStep 4b. Download or data access for multiple granule\nTo download multiple granules, click on the green + symbol to add files to our project. Click on the green button towards the bottom that says “Download”. This will take us to another page with options to customize our download or access link(s).\n\n\n\nFigure caption: Select granules and click download\n\n\nOn the next page click the Direct Download option and click the green Download Data on the bottom left side of the page. In this page some datasets will provide a data customization service, this is really important if we don’t want to download the full record but just the variables and region of interest.\n\n\n\nFigure caption: Direct download multiple granules\n\n\nIf we pick the direct download option, we’ll be redirected to the final page for instructions to download and links for data access in the cloud. You should see three tabs: Download Files, AWS S3 Access, Download Script:\n\n\n\nFigure caption: Download to local\n\n\nIf we select the data customization service we’ll be able to subset by region of interest, variables and temporal parameters.\n\n\n\nFigure caption: Harmony subsetter service\n\n\nVariables can be selected too.\n\n\n\nFigure caption: Harmony subsetter service\n\n\nThe Download Files tab provides the https:// links for downloading the files locally\nThe AWS S3 Access tab provides the S3:// links, which is what we would use to access the data directly in-region (us-west-2) within the AWS cloud."
},
{
"objectID": "tutorials/index.html",
@@ -193,7 +193,7 @@
"href": "tutorials/jupyterhub_demo/jupyterhub_demo.html",
"title": "Demo JupyterHub",
"section": "",
- "text": "Author: Tasha Snow\nnacunmsidsvo Learning Objectives - **Learn how to access and use the Openscapes JupyterHub** - **Open the JupyterHub and clone the Openscapes Espacio and Sostenibilidad Colloquium repository**"
+ "text": "Author: Tasha Snow\nbryoakxxlfos Learning Objectives - **Learn how to access and use the Openscapes JupyterHub** - **Open the JupyterHub and clone the Openscapes Espacio and Sostenibilidad Colloquium repository**"
},
{
"objectID": "tutorials/jupyterhub_demo/jupyterhub_demo.html#access-the-cryocloud-powerpoint-whenever-you-need-to-reference-it",
@@ -207,7 +207,7 @@
"href": "tutorials/jupyterhub_demo/jupyterhub_demo.html#open-cryocloud",
"title": "Demo JupyterHub",
"section": "Open CryoCloud",
- "text": "Open CryoCloud\n\nScroll through the server sizes. Stick with the 3.7Gb server (the default).\n\n```nacunmsidsvo Tip Be realistic about the max memory you will need. The amount you select, you are guaranteed, but if you use more you risk crashing your server for you and anyone else who is sharing with you. If you crash the server, it just requires logging out and reopening it, but it could be annoying for everyone.\nCheck your memory usage at the bottom in the middle of the screen.\n\n2) Choose the Python programming language.\n\n3) Sit back and learn about each of the tools!\n - JupyterHub options and viewing setup\n - Github\n - Virtual Linux desktop\n - SyncThing\n - Viewing and editing of different files\n\nNow after the demo...\n\n## Task: Clone the Espacio and Sostenibilidad Colloquium jupyterbook\n\nWe will import the [NASA Openscapes Espacio and Sostenibilidad Colloquium Github repository](https://github.com/NASA-Openscapes/2023-ssc.git).\n\nTo do this: \n1. Select the plus (`+`) sign above the `File Browser` to the left, which will bring up a `Launcher` window. \n\n2. Click the `terminal` button under Other to open it. This is your command line like you would have on any computer. \n\nBefore cloning the repo, you have the option to switch to another file folder using the _change directory_ terminal command: `cd folder` if you do not want the Hackweek repo in your current directory (you can check which directory you are currently in using _print working directory_ command: `pwd`).\ncd yourfoldername\n\n3. Now clone the hackweek code into your current directory: \ngit clone https://github.com/NASA-Openscapes/2023-ssc.git\n\n4. You will see the folder pop into your `File Browser` on the left if you have the current directory open. Click on the folder to navigate through the files. \n\n5. To open this tutorial, click on the `book` subdirectory > `tutorials` > `jupyterhub_demo` > and double click on `jupyterhub_demo`. This should open up this tutorial in case you want to review it in the future. \n\n## Shutting down your JupyterHub\n\n```{admonition} TIP\n**Best Practice: Shut down the Openscapes server when you are done to save us money.**\n\n**If you only close your tab or click log out, your server will continue running for 90 minutes.**\nWhenever you are done, it is best to shut down your server when you sign out to save money. Time on the JupyterHub costs money and there are systems in place to make sure your server doesn’t run indefinitely if you forget about it. After 90 minutes of no use, it will shut down. We prefer you shut down the server when so we save that 90 minutes of computing cost. To do so:\n\nIn upper left, click on File > Hub Control Panel, which will open another tab\nClick the Stop Server button. Once this button disappears after you clicked it, your server is off.\nClick Log Out in the top right of your screen and you will be logged out, or you can start a new server\nYou can now close this tab and the other tab where you were just working"
+ "text": "Open CryoCloud\n\nScroll through the server sizes. Stick with the 3.7Gb server (the default).\n\n```bryoakxxlfos Tip Be realistic about the max memory you will need. The amount you select, you are guaranteed, but if you use more you risk crashing your server for you and anyone else who is sharing with you. If you crash the server, it just requires logging out and reopening it, but it could be annoying for everyone.\nCheck your memory usage at the bottom in the middle of the screen.\n\n2) Choose the Python programming language.\n\n3) Sit back and learn about each of the tools!\n - JupyterHub options and viewing setup\n - Github\n - Virtual Linux desktop\n - SyncThing\n - Viewing and editing of different files\n\nNow after the demo...\n\n## Task: Clone the Espacio and Sostenibilidad Colloquium jupyterbook\n\nWe will import the [NASA Openscapes Espacio and Sostenibilidad Colloquium Github repository](https://github.com/NASA-Openscapes/2023-ssc.git).\n\nTo do this: \n1. Select the plus (`+`) sign above the `File Browser` to the left, which will bring up a `Launcher` window. \n\n2. Click the `terminal` button under Other to open it. This is your command line like you would have on any computer. \n\nBefore cloning the repo, you have the option to switch to another file folder using the _change directory_ terminal command: `cd folder` if you do not want the Hackweek repo in your current directory (you can check which directory you are currently in using _print working directory_ command: `pwd`).\ncd yourfoldername\n\n3. Now clone the hackweek code into your current directory: \ngit clone https://github.com/NASA-Openscapes/2023-ssc.git\n\n4. You will see the folder pop into your `File Browser` on the left if you have the current directory open. Click on the folder to navigate through the files. \n\n5. To open this tutorial, click on the `book` subdirectory > `tutorials` > `jupyterhub_demo` > and double click on `jupyterhub_demo`. This should open up this tutorial in case you want to review it in the future. \n\n## Shutting down your JupyterHub\n\n```{admonition} TIP\n**Best Practice: Shut down the Openscapes server when you are done to save us money.**\n\n**If you only close your tab or click log out, your server will continue running for 90 minutes.**\nWhenever you are done, it is best to shut down your server when you sign out to save money. Time on the JupyterHub costs money and there are systems in place to make sure your server doesn’t run indefinitely if you forget about it. After 90 minutes of no use, it will shut down. We prefer you shut down the server when so we save that 90 minutes of computing cost. To do so:\n\nIn upper left, click on File > Hub Control Panel, which will open another tab\nClick the Stop Server button. Once this button disappears after you clicked it, your server is off.\nClick Log Out in the top right of your screen and you will be logged out, or you can start a new server\nYou can now close this tab and the other tab where you were just working"
},
{
"objectID": "tutorials/jupyterhub_demo/jupyterhub_demo.html#summary",
diff --git a/sitemap.xml b/sitemap.xml
index 1806345..3239edf 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -2,82 +2,82 @@
https://nasa-openscapes.github.io/2023-ssc/index.html
- 2023-11-16T10:06:04.353Z
+ 2023-11-16T11:03:20.913Zhttps://nasa-openscapes.github.io/2023-ssc/how-tos/authentication/NASA_Earthdata_Authentication.html
- 2023-11-16T10:06:03.633Z
+ 2023-11-16T11:03:20.249Zhttps://nasa-openscapes.github.io/2023-ssc/how-tos/data-access/Intro_xarray_hvplot.html
- 2023-11-16T10:06:02.117Z
+ 2023-11-16T11:03:19.045Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/data-access/icepyx.html
- 2023-11-16T10:06:01.125Z
+ 2023-11-16T11:03:17.833Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/data-access/earthdata-search.html
- 2023-11-16T10:06:00.153Z
+ 2023-11-16T11:03:16.705Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/index.html
- 2023-11-16T10:05:59.013Z
+ 2023-11-16T11:03:15.569Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/schedule.html
- 2023-11-16T10:05:58.261Z
+ 2023-11-16T11:03:14.833Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/cloud/cloud-paradigm.html
- 2023-11-16T10:05:57.569Z
+ 2023-11-16T11:03:14.181Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/GEDI_data_SSC23.html
- 2023-11-16T10:05:56.633Z
+ 2023-11-16T11:03:13.377Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/further-resources.html
- 2023-11-16T10:05:54.277Z
+ 2023-11-16T11:03:10.913Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/prerequisites.html
- 2023-11-16T10:05:53.321Z
+ 2023-11-16T11:03:09.977Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/jupyterhub_demo/jupyterhub_demo.html
- 2023-11-16T10:05:54.633Z
+ 2023-11-16T11:03:11.273Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/science/Intro_xarray_hvplot.html
- 2023-11-16T10:05:57.117Z
+ 2023-11-16T11:03:13.889Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/cloud/index.html
- 2023-11-16T10:05:57.893Z
+ 2023-11-16T11:03:14.461Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/setup.html
- 2023-11-16T10:05:58.701Z
+ 2023-11-16T11:03:15.277Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/data-access/index.html
- 2023-11-16T10:05:59.753Z
+ 2023-11-16T11:03:16.305Zhttps://nasa-openscapes.github.io/2023-ssc/tutorials/data-access/earthaccess.html
- 2023-11-16T10:06:00.845Z
+ 2023-11-16T11:03:17.397Zhttps://nasa-openscapes.github.io/2023-ssc/how-tos/data-access/Earthdata_Cloud__Single_File__Direct_S3_Access_Clip_COG_Example.html
- 2023-11-16T10:06:01.633Z
+ 2023-11-16T11:03:18.545Zhttps://nasa-openscapes.github.io/2023-ssc/how-tos/data-discovery/Data_Discovery_CMR_API.html
- 2023-11-16T10:06:02.781Z
+ 2023-11-16T11:03:19.697Zhttps://nasa-openscapes.github.io/2023-ssc/how-tos/authentication/NASA_Earthdata_Login_Token.html
- 2023-11-16T10:06:04.033Z
+ 2023-11-16T11:03:20.601Z
diff --git a/tutorials/data-access/earthdata-search.html b/tutorials/data-access/earthdata-search.html
index 9c8458b..1dce3be 100644
--- a/tutorials/data-access/earthdata-search.html
+++ b/tutorials/data-access/earthdata-search.html
@@ -313,7 +313,7 @@
S
Step 2. Search for dataset of interest
Use the search box in the upper left to type key words. In this example we are interested in the GEDI or ICESAT-2 which is managed by the LP DAAC and made available from the NASA Earthdata Cloud archive hosted in AWS cloud.
Type GEDI in the search bar Click on the “Available from AWS Cloud” filter option on the left.
-
We can click on the (i) icon for the dataset to read more details, including the dataset shortname (helpful for programmatic workflows) just below the dataset name; here ECO_L2T_LSTE.
+
We can click on the (i) icon for the dataset to read more details, including the dataset shortname (helpful for programmatic workflows) just below the dataset name; here we are using a keyword GEDI.
Step 3. Explore the dataset details, including Cloud Access information
@@ -331,13 +331,7 @@
-
-Figure caption: Cloud access info in EDS
-
-
-
-
-
+
Figure caption: Documentation describing the In-region Direct S3 Access to Buckets
@@ -350,14 +344,14 @@
-
+
Figure caption: Download granules
You can also get the S3 information (e.g., AWS region, bucket, temperary credentials for S3 access, and file names) by selecting the AWS S3 Access tab.
-
+
Figure caption: S3 access for granules
@@ -366,28 +360,36 @@
-
+
Figure caption: Select granules and click download
-
On the next page click the Direct Download option and click the green Download Data on the bottom left side of the page.
+
On the next page click the Direct Download option and click the green Download Data on the bottom left side of the page. In this page some datasets will provide a data customization service, this is really important if we don’t want to download the full record but just the variables and region of interest.
-
+
Figure caption: Direct download multiple granules
-
We’re now taked to the final page for instructions to download and links for data access in the cloud. You should see three tabs: Download Files, AWS S3 Access, Download Script:
+
If we pick the direct download option, we’ll be redirected to the final page for instructions to download and links for data access in the cloud. You should see three tabs: Download Files, AWS S3 Access, Download Script:
-
+
Figure caption: Download to local
+
If we select the data customization service we’ll be able to subset by region of interest, variables and temporal parameters.
+
+
+
+Figure caption: Harmony subsetter service
+
+
+
Variables can be selected too.
-
-Figure caption: Direct S3 access
+
+Figure caption: Harmony subsetter service
The Download Files tab provides the https:// links for downloading the files locally
nacunmsidsvo Learning Objectives - **Learn how to access and use the Openscapes JupyterHub** - **Open the JupyterHub and clone the Openscapes Espacio and Sostenibilidad Colloquium repository**
+
bryoakxxlfos Learning Objectives - **Learn how to access and use the Openscapes JupyterHub** - **Open the JupyterHub and clone the Openscapes Espacio and Sostenibilidad Colloquium repository**
Open the powerpoint by directly clicking on the hyperlink above or to open it in the Openscapes Linux Desktop web browser as follows: - Copy this hyperlink: https://bit.ly/4785hMv - Click on the plus (+) sign in the File Browser to the left to open a Launcher window - Under Notebooks, click on Desktop to access the Linux Desktop. This will open a new tab. - Click on the Web Browser tool (globe) at the bottom of the screen - Paste the url into the search bar
@@ -324,7 +324,7 @@
Open CryoCloud
Scroll through the server sizes. Stick with the 3.7Gb server (the default).
-
```nacunmsidsvo Tip Be realistic about the max memory you will need. The amount you select, you are guaranteed, but if you use more you risk crashing your server for you and anyone else who is sharing with you. If you crash the server, it just requires logging out and reopening it, but it could be annoying for everyone.
+
```bryoakxxlfos Tip Be realistic about the max memory you will need. The amount you select, you are guaranteed, but if you use more you risk crashing your server for you and anyone else who is sharing with you. If you crash the server, it just requires logging out and reopening it, but it could be annoying for everyone.
Check your memory usage at the bottom in the middle of the screen.