A Pytorch implementation of the Dual-Adversarial Domain Adaptation (DADA) approach for replay spoofing detection in automatic speaker verification (ASV). Paper has been accepted by INTERSPEECH 2020.
Please get your running environment ready firstly, e.g., Pytorch 1.1+, Kaldi, etc. Specially, do not forget to update path.sh for Kaldi. Kaldi is only used for data pre-processing, e.g., cmvn.
Python requirements are:
matplotlib==3.1.1
pandas==0.23.3
kaldi_io==0.9.1
fire==0.1.3
tableprint==0.8.0
torch==1.1.0
tabulate==0.8.3
torchnet==0.0.4
numpy==1.17.3
imbalanced_learn==0.5.0
imblearn==0.0
librosa==0.7.2
PyYAML==5.3.1
scikit_learn==0.22.2.post1
soundfile==0.10.3.post1
tqdm==4.45.0
To install them, just run pip install -r requirements.txt.
We use two real-case replay datasets, whese replay attacks are replayed and recorded using real devices, rather than artificially simulated (e.g., ASVspoof 2019):
- ASVspoof 2017 uses a variety of replay configurations (acoustic environment, recording and playback devices). It focuses on
in the wildscenes. - BTAS 2016 is based on AVspoof dataset. This dataset contains both PA and LA attacks, but only the PA portion (denoted as BTAS16-PA) is used in our experiments.
After downloading these datasets, please use your own data paths in data/ASV17/flists/*.scp and data/BTAS16-PA/flists/*.scp.
257-dimensional log power spectrograms (LPS) are extracted as front-end features by computing 512-point Short-Time Fourier Transform (STFT) every 10 ms with a window size of 25 ms.
Here we use The librosa toolkit (code entry: scripts/make_features.sh).
Also, the Kaldi toolkit is employed to apply sliding-window cmvn per utterance.
Three typical anti-spoofing models are evaluated:
LCNN: Light CNN is the winner of the ASVspoof2017 challenge (paper). We use the adapted version in our previous work (paper), which applies to variable lengths of input features.ResNet10: The ResNet variations used in ASVspoof 2019 achieved great performance in the PA subtask. We use the 10-layer ResNet for it is comparable with LCNN in parameter size.CGCNN: Context-Gate CNN was our main proposal in ASVspoof 2019 (paper). Gated linear unit (GLU) activations are used to replace the MFM activations in LCNN. Except for that, CGCNN shares a similar structure with LCNN.
All model definitions can be seen in scripts/models.py.
The framework here uses a combination of google-fire and yaml parsing to enable a convenient interface.
By default one needs to pass a *.yaml configuration file into any of the command scripts.
However, parameters of the yaml files (seen in config/train.yaml) can also be overwritten.
e.g., to train a LCNN model using training data in the ASV17 dataset:
python3 -u scripts/run.py train --config=config/train.yaml \
--labels=data/ASV17/labels/train_dev.txt \
--features=data/ASV17/features/STFT-LPS/STFT-LPS_train-dev.ark \
--model=LightCNN_9Layers \
--label_type=label \
--seed=1
All training commands are listed in train.sh.
After training, we get the model path. To test the model, the command is:
python3 scripts/run.py score --model_path=MODEL_PATH/model.th \
--features=FEATURES.ark \
--label_type=label/DAT/DADA \
--dataset=ASV17/BTAS16-PA \
--output=OUTPUT.txt \
--eval_out=EVALUATION_RESULT.txt
Just run test.sh using correct testing parameters.
Evaluation scripts are directly taken from the baseline of the ASVspoof2019 challenge, seen here.
We can extract deep embeddings for t-SNE visualization. The command is:
python3 scripts/run.py extract --model_path=MODEL_PATH/model.th \
--features=FEATURES.ark \
--output_arkfile=OUTPUT.ark
Please refer to scripts/extract_embeddings.sh.
We pool the training set and the development set as the actual training data, 10% of which are further divided asthe validation set for model selection. All models are tested on both evaluation sets.
The results are as follows:
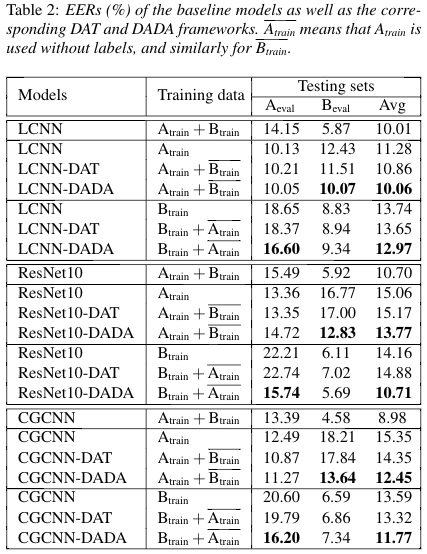
If you use our models, please cite the following papers:
@article{wang2019cross,
title={Cross-domain replay spoofing attack detection using domain adversarial training},
author={Wang, Hongji and Dinkel, Heinrich and Wang, Shuai and Qian, Yanmin and Yu, Kai},
journal={Proc. Interspeech 2019},
pages={2938--2942},
year={2019}
}
@article{yang2019sjtu,
title={The SJTU Robust Anti-spoofing System for the ASVspoof 2019 Challenge},
author={Yang, Yexin and Wang, Hongji and Dinkel, Heinrich and Chen, Zhengyang and Wang, Shuai and Qian, Yanmin and Yu, Kai},
journal={Proc. Interspeech 2019},
pages={1038--1042},
year={2019}
}