A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets from 3D Scans (ICCV 2021)
Project Website · Paper · >> [Github] << · Data · Pretrained Weights · Annotator ·
We provide huggingface demos for monocular surface normal estimation and depth estimation. You can load/run the models
import torch
# you may need to install timm for the DPT (we use 0.4.12)
# Surface normal estimation model
model_normal = torch.hub.load('alexsax/omnidata_models', 'surface_normal_dpt_hybrid_384')
# Depth estimation model
model_depth = torch.hub.load('alexsax/omnidata_models', 'depth_dpt_hybrid_384')
# Without pre-trained weights
model_custom = torch.hub.load('alexsax/omnidata_models', 'dpt_hybrid_384', pretrained=False, task='normal')
Previously, installing + using the models was more difficult. Using torch.hub.load is now the recommended way to use the models locally.
- Pretrained models
- online demo [Updated Transormer models - Mar 2022]
- weights and pytorch demo [Updated Transormer models - Mar 2022]
- training
- Data
- dataset info
- download standardized portions of the dataset [Added Hypersim fix - Aug 2022]
- configurable pytorch dataloaders [Added multiview, mesh, camera parameters - Aug 2022]
- The Pipeline
- Source for all above
- Paper code (#MiDaS loss)
- Citing
Demo code, training losses, etc are available here: weights and code:
python demo.py --task depth --img_path $PATH_TO_IMAGE_OR_FOLDER --output_path $PATH_TO_SAVE_OUTPUT # or TASK=normal |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
You can download each component and modality individually or all at once with our download utility. MAIN DATA PAGE
conda install -c conda-forge aria2
pip install 'omnidata-tools'
omnitools.download point_info rgb depth_euclidean mask_valid fragments \
--components replica taskonomy \
--subset debug \
--dest ./omnidata_starter_dataset/ \
--name YOUR_NAME --email YOUR_EMAIL --agree_allWe ran our annotation pipeline on several collections of 3D meshes. The result is a 24-million-viewpoint multiview dataset comprising over 2000 scenes with the following labels for each image:
| RGB | Cam. Intrinsics | Cam. Pose | Correspondences (Flow) | Segm. (Instances) |
Segm. (Semantic) |
Segm. (2D Graphcut) |
Segm. (2.5D Graphcut) |
| Distance (Euclidean) | Depth (Z-Buffer) | Surface Normals | Curvature | Edges (Texture) | Shading (reshading) | Keypoints (2D, SIFT) | Keypoints (3D, NARF) |
| Masks (valid pixels) | Shading |
--components: Taskonomy, Hypersim, Replica, Google Scanned Objects in Replica, Habitat-Matterport3D, BlendedMVS, CLEVR
More about the data: Standardized data subsets and download tool
git clone https://github.com/Ainaz99/omnidata-annotator # Generation scripts
docker pull ainaz99/omnidata-annotator:latest # Includes Blender, Meshlab, other libs
docker run -ti --rm \
-v omnidata-annotator:/annotator \
-v PATH_TO_3D_MODEL:/model \
ainaz99/omnidata-annotator:latest
cd /annotator
./run-demo.sh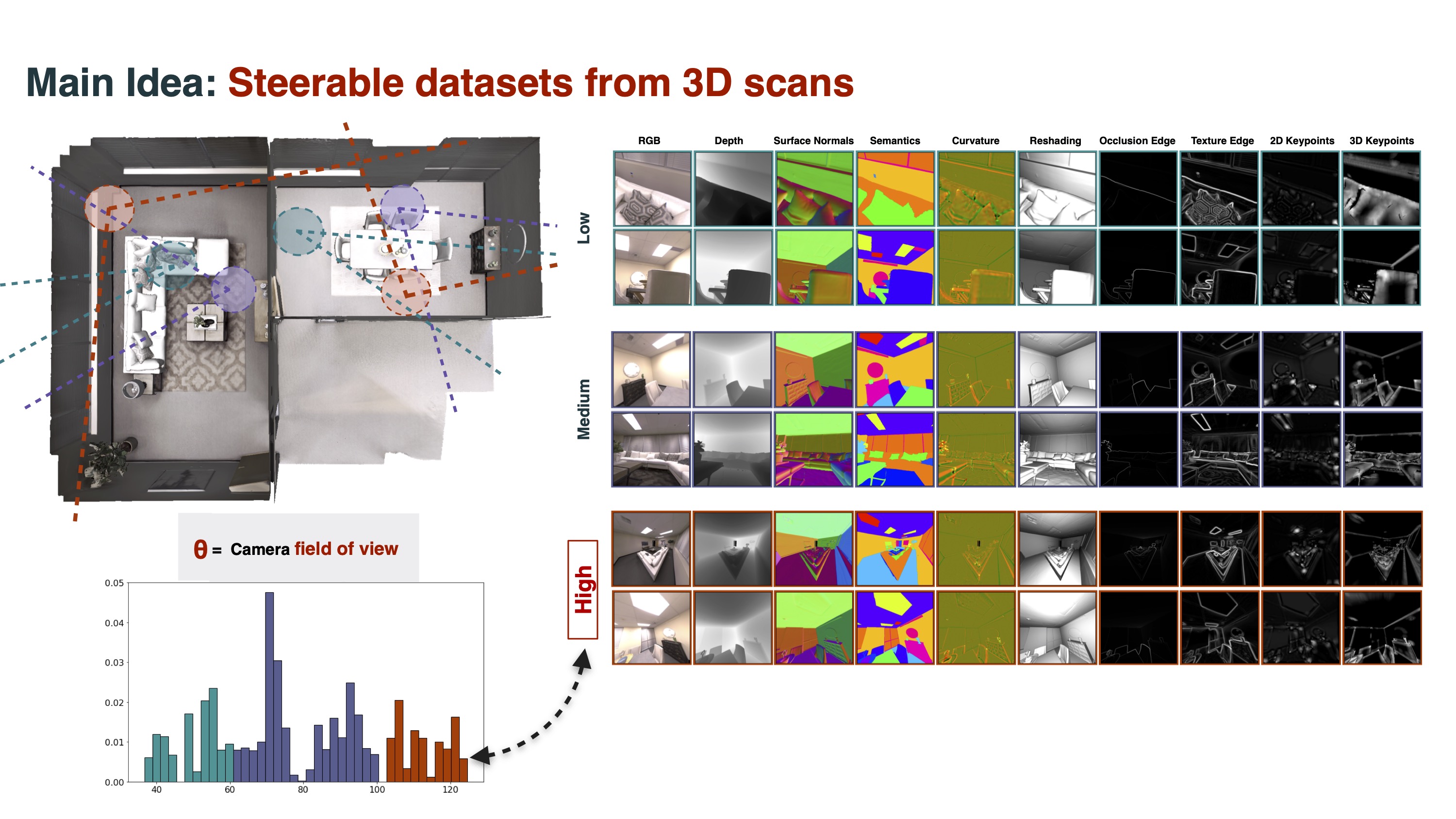
Documentation and a tutorial here.
git clone https://github.com/EPFL-VILAB/omnidata
cd omnidata_tools/torch # PyTorch code for configurable Omnidata dataloaders, scripts for training, demo of trained models
cd omnidata_tools # Code for downloader utility above, what's installed by: `pip install 'omnidata-tools'`
cd omnidata_annotator # Annotator code. Docker CLI above
cd paper_code # Reference
@inproceedings{eftekhar2021omnidata,
title={Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets From 3D Scans},
author={Eftekhar, Ainaz and Sax, Alexander and Malik, Jitendra and Zamir, Amir},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={10786--10796},
year={2021}
}
In case you use our latest pretrained models please also cite the following paper for 3D data augmentations:
@inproceedings{kar20223d,
title={3D Common Corruptions and Data Augmentation},
author={Kar, O{\u{g}}uzhan Fatih and Yeo, Teresa and Atanov, Andrei and Zamir, Amir},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={18963--18974},
year={2022}
}
...were you looking for the research paper or project website?